Flume的四个使用案例
一、Flume监听端口
1,在linux机器上下载telnet工具
yum search telnet
yumm install telnet.x86_64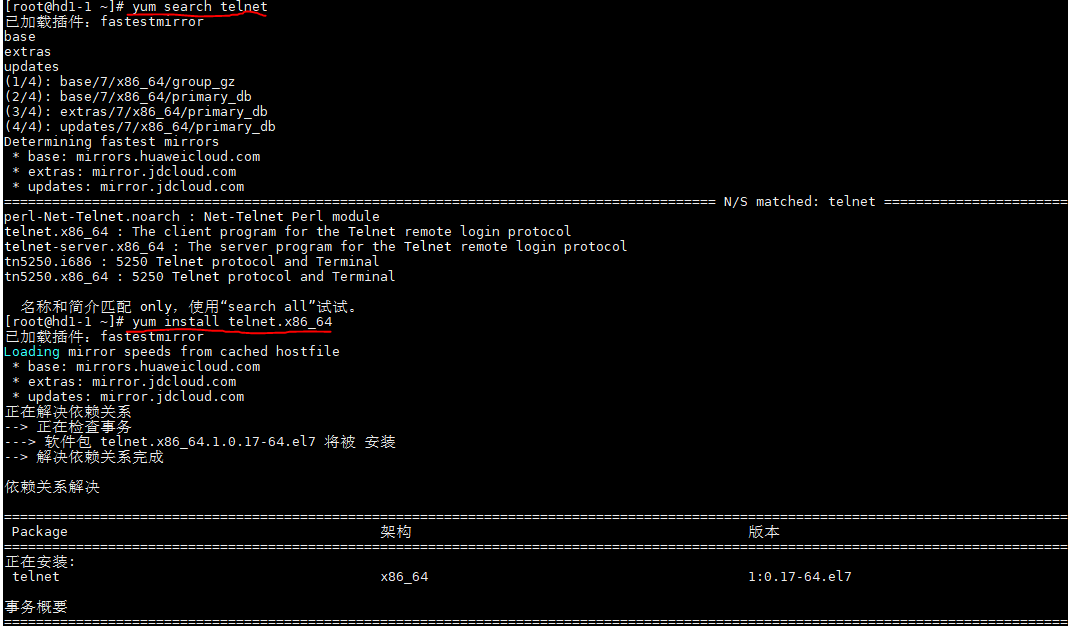
2.编写flume的配置文件,并将文件复制到flume/conf文件夹下
#.agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 #.source netcat表示监视端口、localhost监视本机(也可以写本机名如hd1-)
#44444端口号(随便写,注意不要与常用的端口号重复即可)
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = #.sinks Describe the sink 输出日志文件
a1.sinks.k1.type = logger #. 使用内存、总容量1000、每次传输100
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = #.Bind the source and sink to the channel 一个source可以绑定多个channel
# 一个sinks可以只能绑定一个channel 使用的是图二的模型
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3.启动配置文件
bin/flume-ng agent --conf conf/ --name a1 --conf-file conf/flumejob_telnet.conf -Dflume.root.logger==INFO,console
4.新建一个Linux本机,输入下面命令连接本机
telnet localhost 44444
5.发送数据查看
二、实施采集数据到hdfs(监控文件)
这里有一个无限产生数据的jar包,其产生的数据存放在/opt/jars/calllog.csv下
1.写配置文件 flumejob_hdfs.conf
# .agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # .sources
# exec 执行一个命令的方式去查看文件 tail -F 实时查看
a1.sources.r1.type = exec
# 要执行的脚本command tail -F 默认10行 man tail 查看帮助
a1.sources.r1.command = tail -F /opt/jars/calllog.csv
# 执行这个command使用的是哪个脚本 -c 指定使用什么命令
# bash: /usr/bin/bash /usr/share/man/man1/bash..gz
a1.sources.r1.shell = /usr/bin/bash -c # .sinks
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hd1-1:9000/flume/calllog
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹 秒 (默认30s)
a1.sinks.k1.hdfs.roundValue =
#重新定义时间单位(每小时滚动一个文件夹)
a1.sinks.k1.hdfs.roundUnit = minute
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a1.sinks.k1.hdfs.batchSize =
#设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件 秒
a1.sinks.k1.hdfs.rollInterval =
#设置每个文件的滚动大小 字节(最好128M)
a1.sinks.k1.hdfs.rollSize =
#文件的滚动与 Event 数量无关
a1.sinks.k1.hdfs.rollCount =
#最小冗余数(备份数 生成滚动功能则生效roll hadoop本身有此功能 无需配置) 1份 不冗余
a1.sinks.k1.hdfs.minBlockReplicas = # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.启动hdfs、yarn,并在hdfs上建立文件中的生成文件目录
hdfs dfs -mkdir -p /flume/calllog
3.启动命令
bin/flume-ng agent --conf conf/ --name a1 --conf-file conf/flumejob_hdfs.conf
4.启动jar包,然后查看hdfs上calllog文件夹下的变化
三、监控文件目录
1.写配置文件 flumejob_dir.conf
# .agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # .sources
a1.sources.r1.type = spooldir
# 监控的文件夹
a1.sources.r1.spoolDir = /root/spooldir
# 上传成功后显示后缀名
a1.sources.r1.fileSuffix = .COMPLETED
# 如论如何 加绝对路径的文件名 默认false
a1.sources.r1.fileHeader = true #忽略所有以.tmp 结尾的文件(正在被写入),不上传
# ^以任何开头 出现无限次 以.tmp结尾的
a1.sources.r1.ignorePattern = ([^ ]*\.tmp) # .sinks
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hd09-01:9000/flume/spooldir/%Y%m%d/%H
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = spooldir-
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue =
#重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a1.sinks.k1.hdfs.batchSize = #设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval =
#设置每个文件的滚动大小大概是 128M
a1.sinks.k1.hdfs.rollSize =
#文件的滚动与 Event 数量无关
a1.sinks.k1.hdfs.rollCount =
#最小副本数
a1.sinks.k1.hdfs.minBlockReplicas = # .channels
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # .bink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.启动hdfs、yarn,注意,不需要在hdfs上创建
3.启动命令
bin/flume-ng agent --conf conf\ --name a1 --conf-file conf/flumejob_dir.conf
4.将任意文件复制到spool文件目录中,在hdfs中可看到生成日志文件
四、Flume监听一个文件,然后使用两个channel,一个channle对应的sink存储到hdfs,另一个channel对应的sink存储到本地。
思路:这时应需要三个agent,
第一个agent用来监听文件并将数据源复制为两份发送到其他两个agent,
第二个agent将数据传输到hdfs存储,第三个agent将数据存储在本地。
1.编写三个conf文件(flumejob1.conf、flumejob2.conf、flumejob3.conf)
# name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 将数据流复制给多个 channel
a1.sources.r1.selector.type = replicating # Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /tmp/root/hive.log
a1.sources.r1.shell = /bin/bash -c # Describe the sink
# 分两个端口发送数据
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hd09-
a1.sinks.k1.port = a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hd09-
a1.sinks.k2.port = # Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = a1.channels.c2.type = memory
a1.channels.c2.capacity =
a1.channels.c2.transactionCapacity = # Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1 # Describe/configure the source
a2.sources.r1.type = avro
# 端口抓取数据
a2.sources.r1.bind = hd09-
a2.sources.r1.port = # Describe the sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://hd09-01:9000/flume2/%Y%m%d/%H #上传文件的前缀
a2.sinks.k1.hdfs.filePrefix = flume2-
#是否按照时间滚动文件夹
a2.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k1.hdfs.roundValue =
#重新定义时间单位
a2.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k1.hdfs.batchSize = #设置文件类型,可支持压缩
a2.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k1.hdfs.rollInterval =
#设置每个文件的滚动大小大概是 128M
a2.sinks.k1.hdfs.rollSize =
#文件的滚动与 Event 数量无关
a2.sinks.k1.hdfs.rollCount =
#最小副本数 # Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity =
a2.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c1 # Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hd09-
a3.sources.r1.port = # Describe the sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /root/flume2 # Describe the channel
a3.channels.c1.type = memory
a3.channels.c1.capacity =
a3.channels.c1.transactionCapacity = # Bind the source and sink to the channel
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
2.在本地创建文件中本地存放的文件夹,本地不会自动创建,而hdfs会
mkdir /root/flume2
3.打开jar包测试。
Flume的四个使用案例的更多相关文章
- Pandas系列(十四)- 实战案例
一.series import pandas as pd import string #创建Series的两种方式 #方式一 t = pd.Series([1,2,3,4,43],index=list ...
- Flume原理分析与使用案例
1.flume的特点: flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据 ...
- java基础之多线程四:简单案例
多线程案例: 有一个包包的数量为100个,分别从实体店和官网进行售卖.使用多线程的方式,分别打印实体店和官网卖出包包的信息.分别统计官网和实体店各卖出了多少个包包 第一种方法 继承Thread类: p ...
- 05_ Flume多级Agent之间串联案例
多级agent之间串联: 从tail命令获取数据发送到avro端口,另一个节点可配置一个avro源来获取数据,发送外部存储 启动两个Agent节点: 使用scp命令拷贝flume安装包到另一台虚拟机; ...
- 04_ Flume采集文件到HDFS案例
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs 根据需求,首先定义以下3大要素 采集源,即source——监控文件内容更新 : ex ...
- maven第四章背景案例
4.3简要设计 4.3.1接口设计 4.3.2模块结构 思想 先定义出核心接口,一个接口可以认为是一个功能,根据接口划分功能 设计模式就是一种思想,外观模式和代理模式,适配者模式三者的区别 http: ...
- 《数据结构与算法(C语言版)》严蔚敏 | 第四章课本案例
//二叉树的顺序存储表示 #define MAXTSIZE 100 typedef TElemtype SqBiTree[MAXTSIZE]; SqBiTree bt; //二叉树的二叉链表存储表示 ...
- Flume具体应用(多案例)
日志采集 对于flume的原理其实很容易理解,我们更应该掌握flume的具体使用方法,flume提供了大量内置的Source.Channel和Sink类型.而且不同类型的Source.Channel和 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
随机推荐
- 配置nginx php上传大文件
配置nginx php上传大文件: 1. 修改PHP配置文件中的三项:vim /usr/local/php/etc/php.ini 1.file_uploads 设为On,允许通过HTTP上传文件 2 ...
- FTP服务器配置和管理
一:ftp 简介 1:ftp服务: internet 是一个非常复杂额计算机环境,其中有pc/mac/小型机/大型机等.而在这些计算机上运行的操作系统也是五花八门,有 unix.Linux.微软的wi ...
- Swift 通过字符串创建控制器
由于Swift 中新增了一个命名空间(在同一个命名空间中的文件可以直接访问而不用引入头文件)的概念 所以通过字符串创建控制器需要带上命名空间 1 首先为Bundle 写一个分类 获取命名空间 ext ...
- jQuery获取地址栏中的链接参数
http://caibaojian.com/177.html 问题描述 今天做一个主题,有一个需求是根据不同的页面来做,虽然php也可以做到,不过考虑到自己的特效代码都是在jQuery上完成,想着能否 ...
- 扇形多级菜单可配置Demo
预览效果 领导是想把这个做成复选框,所以做成了可以多选的... Demo下载:https://github.com/zhangzn3/arc-menu
- 【gearman】gearmand -d 无反应解决
背景:安装了gearman后,用指令gearmand -d启动后.输入ps -ef|grep gearmand 查找不到.说明服务并没有启动. 查看报错: gearmand -d -l gear.lo ...
- 【splunk】按时间统计并找到异常值
场景: 有长时间对多个端口访问的日志数据,每天对端口的访问量是稳定的.如果某一天对某个端口的访问量突然增加表示可能出现了问题.现在要通过splunk找到异常值. 思路: 统计每个端口每天的访问量.统计 ...
- Linux基础实操一
开启Linux操作系统,要求以root用户登录GNOME图形界面,语言支持选择为汉语 使用快捷键切换到虚拟终端2,使用普通用户身份登录,查看系统提示符 使用命令退出虚拟终端2上登录的用户 使用快捷键切 ...
- 解决Xshell不从22端口连接服务器
xshell默认是22端口 如果服务器给的ssh端口不是22,会连接失败 需要去指定连接 新建 设置ip和端口,点下面的确定 双击刚创建的会话 输入用户名密码 连接成功
- js中json对象数组按对象属性排序---1
转载:https://www.cnblogs.com/jasonwang2y60/p/6656103.html 在实际工作经常会出现这样一个问题:后台返回一个数组中有i个json数据,需要我们根据js ...