《Apache kafka实战》读书笔记-管理Kafka集群安全之ACL篇
《Apache kafka实战》读书笔记-管理Kafka集群安全之ACL篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
想必大家能看到这篇博客的小伙伴,估计你对kafka已经有了深入对一步了解了,因为现在的你已经不考虑如何部署kafka以及调优了,而是考虑到kafka安全的问题。其实,在很多企业中,很少有人考虑到kafka的安全,小到几十人的小型互联网公司,达到某些云平台的云服务(我这里就不说是哪家云公司了),他们默认都是不会给kafka配置相关安全策略的,而是要求用户自己配置,而很多公司既然要买你的云服务,运维的事情自然也就外包出去了,换句话说,公司可能就没有运维(毕竟不是每家公司都招的起运维的!)。
很多企业或组织对于安全性都有着很高的要求(我所在的公司之前购买的云服务并没有配置安全策略,但是我们公司自建数据中心后,这些服务都是我从头部署,而我对kafka的安全很是看重)。在0.9.0.0版本之前,kafka并未提供任何形式的安全配置,用户只能通过粗粒度的网络配置“一刀切式”地限制对kafka集群的访问。其实关于kafka安全的解决方案有很多,比如,我们可以通过Linux自带的iptables控制访问来源,也可以配置相应的ACL,当然也可以用现在主流的kerberos + sentry这一套组合来配置kafka的安全认证策略。官方提供来关于ACL的命令行工具“kafka-acls.sh”可以用于处理与客户端访问控制相关的问题,它的文档可以在Apache kafka官方网站上找到:http://kafka.apache.org/documentation/#security_authz_cli。如果对kafka在公网传输对建议使用Kerberos,官方文档也有介绍,详情请参考:http://kafka.apache.org/documentation/#security_sasl_kerberos。
一.kafka安全
随着对kafka集群提供安全配置的呼声越来越高,社区终于在0.9.0.0版本正式添加了安全特性,并在0.10.0.0版本中进一步完善。
1>.Kafka的主要安全特性
第一:链接认证机制,包含服务器与客户端(生产者/消费者)链接,服务器间链接以及服务器与工具间链接。支持的认证机制包括SSL(TLS)或SASL。
第二:服务器与zookeeper之间的链接认证机制。
第三:基于SSL的链接通道数据传输加密。
第四:客户端读/写授权。
第五:支持可插拔的授权服务和外部授权服务的集成。
2>.认证(authentication)和授权(authorization)的区别
认证就是证明你是谁的过程。当访问kafka服务时你必须显示地提供身份信息来证明你的身份是合法的。
授权是验证你能访问那些服务的过程。
举一个简单的例子,在一个配置了认证和授权的kafka集群中,只有合法的生产者(已认证)才被允许向Kafka集群发送Produce请求,而发给broker的Produce请求是否会被真正处理则需要该生产者有对应的权限,通常生产者必须拥有主题写入的权限(topic write),即该生产者必须是已授权的。
3>.Kafka安全主要包含三大功能
如前所述,自0.9.0.0版本引入安全配置后,Kafka一只在完善安全特性的功能。当前Kafka安全主要包含三大功能:认证(authenication),信道加密(encryption)和授权(authorization),而其中的认证机制主要是指配置SASL,而授权是通过ACL借口命令来完成的。
在生产环境中,用户若要使用SASL,通常会配置Kerberos,但对一些小公司而言,他们的用户系统并不复杂(即需要访问Kafka集群服务的用户书并不是很多),显然使用Kerberos有些大材小用,而且由于运行在内网,SSL加密也不是很必要。因此一个基于明文传输(PLAITEXT)的SASL集群环境足以应对一般的使用场景。本片博客我们将给出一个可运行的实例来掩饰一下如何在不实用kerberos的情况下配置SASL+ACL以构建安全的Kafka集群。当然kerberos认证kafka的博客我有时间也会给大家整理出来。
二.SASL+ACL
1>.broker端的配置
若要开启SASL和ACL机制,我们需要在broker端进行三个方面的设置。
第一:编写JAAS配置文件;
第二:修改broker的启动脚本,并指定JAAS的配置文件存放路径;
第三:配置“server.properties”的文件内容;
首先是创建包含所有认证用户信息的JAAS文件。在本片博客中,我使用的是Kafka1.1.0,我们假设有三个用户:yinzhengjie,reader和writer,其中yinzhengjie这个用户是集群管理员,reader用户负责读取kafka集群中的topic数据,而writer用户则负责向kafka集群写入消息。好了,话不多说,我们开始在kafka的config目录下编写JAAS文件如下:(修改后最好同步到其他broker节点)
[root@node101 config]# hostname
node101.yinzhengjie.org.cn
[root@node101 config]#
[root@node101 config]# pwd
/soft/kafka/config
[root@node101 config]#
[root@node101 config]# cat /soft/kafka/config/yinzhengjie_kafka_server_jaas.conf
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="yinzhengjie"
password="yinzhengjie-kafka"
user_admin="yinzhengjie"
user_reader="reader"
user_writer="writer"; #注意,这里是倒数第二行,最后的分号千万别丢了,如果不写这个结尾的分号,那么JAAS文件将被视为无效。
};
[root@node101 config]#
由于“kafka-server-start.sh”只接收“server.properties”的位置,不接受其他任何参数,故需要修改Kafka启动脚本,具体做法如下:(修改后最好同步到其他broker节点)
[root@node101 ~]# hostname
node101.yinzhengjie.org.cn
[root@node101 ~]#
[root@node101 ~]# cp /soft/kafka/bin/kafka-server-start.sh /soft/kafka/bin/yinzhengjie-security-kafka-server-start.sh
[root@node101 ~]#
[root@node101 ~]# tail - /soft/kafka/bin/yinzhengjie-security-kafka-server-start.sh #编辑配置文件,指定JAAS文件的所在位置。
exec $base_dir/kafka-run-class.sh $EXTRA_ARGS -Djava.security.auth.login.config=/soft/kafka/config/yinzhengjie_kafka_server_jaas.conf kafka.Kafka "$@"
[root@node101 ~]#
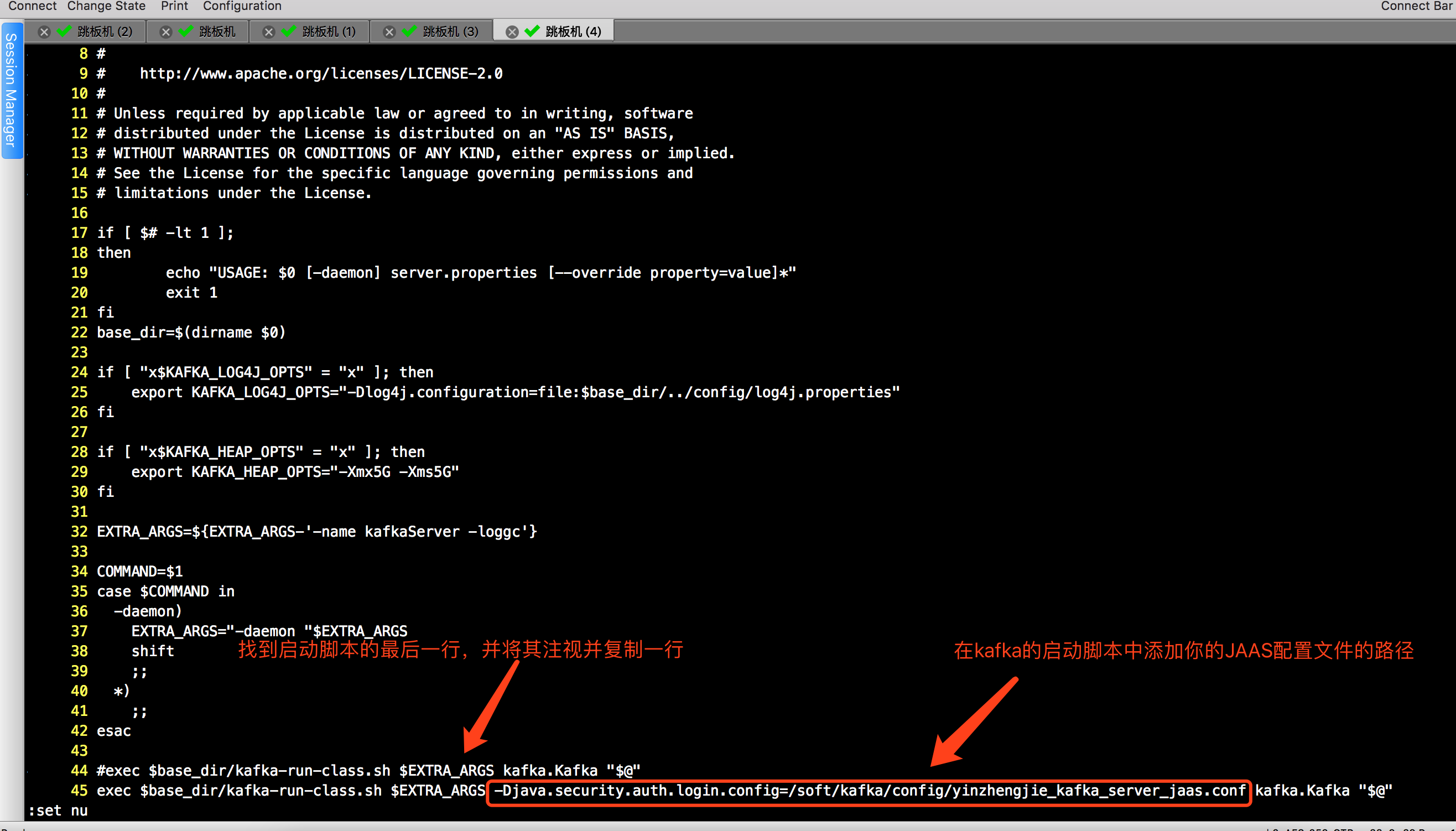
做完上看的步骤后,我们就在kafka的bin目录下做好了一份新的Kafka启动脚本(当然,如果你是老司机的话也可以直接在原来的脚本继续修改,但考虑到后期我需要给大家展示kerberos的配置方法,我有必要保留一份最初始的脚本)。接下来开始修改broker启动所需要的“server.properties” 配置文件,我的配置文件参数如下,也做了相应的中文注释。
[root@node101 ~]# cat /soft/kafka/config/server.properties
#kafka配置文档可参考自官网:
# http://kafka.apache.org/11/documentation.html#brokerconfigs。
# @author :yinzhengjie
# blog:http://www.cnblogs.com/yinzhengjie
# EMAIL:y1053419035@qq.com ############################# Server Basics ############################# # 每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况
broker.id= # 这就是说,这条命令其实并不执行删除动作,仅仅是在zookeeper上标记该topic要被删除而已,同时也提醒用户一定要提前打开delete.topic.enable开关,否则删除动作是不会执行的。推荐设置为true。
delete.topic.enable=true # 是否允许自动创建topic,默认值是true,若是false,就需要通过命令创建topic,推荐设置为false
auto.create.topics.enable=false # 0.11..0版本开始unclean.leader.election.enable参数的默认值由原来的true改为false,可以关闭unclean leader election,也就是不在ISR(IN-Sync Replica)列表中的replica,不会被提升为新的leader partition。kafka集群的持久化力大于可用性,如果ISR中没有其它的replica,会导致这个partition不能读写。
unclean.leader.election.enable=false ############################# Socket Server Settings #############################
# broker 监听器的CSV列表,格式为:[协议]://[主机名]:[端口],[[协议]]://[主机名]:[端口]].该参数主要用于可混搭链接broker使用,可以认为是broker端开放给clients的监听端口。如果不指定主机名,则表示绑定默认网卡;如果主机名是0.0.0.0,则表示绑定所有网卡。Kafka当前支持的协议类型包括PLAINTEXT,SSL及SASL_SSL等。对于新版本的Kafka,推荐值设置listerners一个参数就够了,对于已经过时的两个参数host.name和port,就不用再配置了。对于我未启用安全的Kafka集群,使用PLAINTEXT协议足以。如果启用的安全认证,可以考虑使用SSL或SAS_SSL协议。
listeners=SASL_PLAINTEXT://node101.yinzhengjie.org.cn:9092 # 设置协议,本例使用SASL_PLAINTEXT
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN # allow.everyone.if.no.acl.found参数是broker端端参数,不过有些奇怪的是,他并没记录在官网的broker端参数列表中(但我们可以在官网文档中看到这个参数,他只出现过一次:http://kafka.apache.org/documentation/#security_authz。)。当设置为true时,整个ACL机制将改为黑名单机制,即只有在黑名单中端用户才无法访问资源,非黑名单用户可以通常无阻端访问任何kafka资源;当参数为false时,也就是他端默认值时,ACL机制是白名单机制,只有白名单用户才能访问设定的资源,其他用户都属于未授权用户。
allow.everyone.if.no.acl.found=true # 设置yinzhengjie为超级用户,注意,这个用户是你需要在JAAS文件中指定的哟~
super.users=User:yinzhengjie # 配置ACL入口类
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer # 和listeners类似,该参数也是用于发布给clients的监听器,不过该参数主要用于IaaS环境,比如运上的机器通常都配有多块网卡(私网网卡和公网网卡)。对于这种机器,用户可以设置该参数绑定公网IP供外部clients使用。然后配置上面的listers来绑定私网IP供broker间通信使用。当然不设置该参数也是可以的,只是云上的机器很容易出现clients无法获取数据的问题,原因就是listeners绑定的是默认网卡,而默认网卡通常都是绑定绑定私网IP的。在实际使用场景中,对于配有多块网卡的机器而言,这个参数通常都是需要配置的。
#advertised.listeners=SASL_PLAINTEXT://node101.yinzhengjie.org.cn:9092 # 将侦听器名称映射到安全协议,默认情况下是相同的。在侦听器名称和安全协议之间映射。对于要在多个端口或IP中使用的相同安全协议,必须定义该安全协议。例如,内部和外部通信量可以分开,即使两者都需要SSL。具体地说,用户可以定义名称为INTERNAL和EXTERNAL的侦听器,该属性为:“INTERNAL:SSL,EXTERNAL:SSL”。如图所示,键和值用冒号分隔,映射项用逗号分隔。每个侦听器名称只在地图中出现一次。可以通过向配置名称添加规范化前缀(侦听器名称小写)来为每个侦听器配置不同的安全性(SSL和SASL)设置。例如,为了为INTERNAL侦听器设置不同的密钥存储,将设置名为“listener.name...ssl.keystore.location”的配置。如果未设置侦听器名称的配置,则配置将返回到通用配置(即`ssl.keystore.location')。详情请参考官网文档:http://kafka.apache.org/11/documentation.html#brokerconfigs。
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL # 它控制来一个broker在后台用于处理网络请求的线程数,默认是3。通常情况下,broker启动时会创建多个线程处理来自其他broker和clients发送过来的各种请求。注意,这里的“处理”其实只是负责转发请求,它会将接收到的请求转发到后面的处理线程中。在实际生产环境中,咱们需要不断的监控NetworkProcessorAvgIdlePercent JMX指标。如果该参数指标持续低于0.,建议适当增加该参数的值。
num.network.threads= # 这个参数就是控制broker端实际处理网络请求的线程数,默认值是8,即kafka borker默认创建8个线程以轮询的方式不停地监听转发过来的网络请求并进行实时处理。Kafka同样也为请求处理提供了一个JMX监控指标Request HandlerAvgIdlePercent。如果该参数指标持续低于0.,建议适当增加该参数的值。
num.io.threads= # 接字服务器使用的发送缓冲区(SOYSNDBUF), Socket服务器套接字的SOYSNDBUF缓冲区。如果值为-,则将使用OS默认值。
socket.send.buffer.bytes= # 接字服务器使用的接收缓冲区(SOYRCVBUF),用于网络请求的套接字接收缓冲器.
socket.receive.buffer.bytes= # 接字服务器将接受的请求的最大大小(对OOM的保护).
socket.request.max.bytes= # I/O线程等待队列中的最大的请求数,超过这个数量,network线程就不会再接收一个新的请求。应该是一种自我保护机制。
queued.max.requests= ############################# Log Basics ############################# # 该参数制定了Kafka持久化消息的目录。若待保存的消息数量非常多,那么最好确保该文件夹有充足的磁盘空间。该参数可以设置多个目录,以都好进行分隔。指定多个目录的做法通常是被推荐的,配置多个目录可以提升读写的能力,换句话说,就是提升Kafka的吞吐量。
log.dirs=/home/yinzhengjie/data/kafka/logs,/home/yinzhengjie/data/kafka/logs2,/home/yinzhengjie/data/kafka/logs3 # 在启动时恢复日志和关闭时刷盘日志时每个数据目录的线程的数量,默认1。这个值总共开启的线程数=num.recovery.threads.per.data.dir * log.dirs的数量。举个例子,假如log.dirs指定了3个目录,且num.recovery.threads.per.data.dir配置的是10,那么总共会开启30个线程会在broker停止或者启动时去加载或写入数据到磁盘中。理论上说我们应该适当增大这个值,以达到启动或者停止broker更快的目的,这个参数也就在broker启动和停止时才会起到一定的作用,而broker在启动或者停止的期间borker是无法正常提供服务的,因此我建议大家适当增大这个值以减少broker的启动时间。
num.recovery.threads.per.data.dir= # 服务器接受单个消息的最大大小,即消息体的最大大小,单位是字节
message.max.bytes= # 每当broker停止或崩溃领导时,该broker的分区转移到其他副本。这意味着默认情况下,当代理重新启动时,它将只是所有分区的跟随者,这意味着它不会用于客户端读取和写入。为了避免这种不平衡,Kafka有一个首选复制品的概念。如果分区的副本列表是1,,,则节点1首选作为节点5或9的引导者,因为它在副本列表中较早。您可以让Kafka群集通过运行命令尝试恢复已恢复副本的领导:"kafka-preferred-replica-election.sh --zookeeper zk_host:port/chroot " 由于运行此命令可能很繁琐,您还可以通过设置以下配置来配置Kafka自动执行此操作:auto.leader.rebalance.enable=true。当然,你可以不配置该参数,因为官方默认的配置是true。
auto.leader.rebalance.enable=true # 在强制fsync一个partition的log文件之前暂存的消息数量。调低这个值会更频繁的sync数据到磁盘,影响性能。通常建议人家使用replication来确保持久性,而不是依靠单机上的fsync,但是这可以带来更多的可靠性.
log.flush.interval.ms= ############################# Log Retention Policy ############################# # 这个参数是指定时间数据可以在kafka集群的保留时间。Kafka通常根据时间来决定数据可以被保留多久。默认使用log.retention.hours参数来配置时间,默认是168小时,也就是1周。除此之外,还有其他两个参数log.retention.minutes和log.retention.ms。这3个参数的作用是一样的,都是决定消息多久以后被删除,不过还是推荐使用log.retention.ms。如果指定了不止一个参数,Kafka会优先使用具有最小值的那个参数。
log.retention.hours= # 另一种方式是通过保留的消息字节数来判断消息是否过期。他的值通过参数log.retention.bytes来指定,作用在每一个分区上,也就是说,如果一个包含8个分区的主题,并且log.retention.bytes被设置为1GB,那么这个主题最多可以保留8GB的数据。所以,当主题的分区个数增加时,整个主题可以保留的数据也随之增加。温馨提示:如果同时指定log.retention.bytes和log.retention.ms(或者log.retention.hours或log.retention.minutes),只要任意一个条件得到满足,消息就会被删除。
#log.retention.bytes= # 以上的设置都作用在日志片段上,而不是作用在单个消息上。当消息达到broker时,他们被加分区的当前日志片段上。当日志片段大小达到log.segment.bytes指定的上线(默认是1GB)时,当前日志片段就会被关闭,一个新的日志片段被打开。如果一个日志片段被关闭,就开始等待过期。这个参数的值越小,就越会频繁的关闭和分破新文件,从而降低磁盘写入的整体效率。换句话说:它是控制日志segment文件的大小,超出该大小则追加到一个新的日志segment文件中(-1表示没有限制)
log.segment.bytes= # 日志片段文件的检查周期,查看它们是否达到了删除策略的设置(log.retention.hours或log.retention.bytes)
log.retention.check.interval.ms= ############################# Zookeeper ############################# # 用于保存broker元数据的zookeeper地址是通过zookeeper.connect来指定的。大家发现没有,下面就是我5台zookeeper地址,最后的“kafka_yinzhengjie_cluster1”表示zookeeper路径,作为kafka的chroot环境,如果不指定,默认使用根路径。推荐大家配置chroot路径,因为这样的话,当你部署多个kafka集群时可以共享同一套zookeeper集群,方便你维护。当然如果你不指定的话,它默认是在zookeeper的根路径创建,这样当你其他业务在使用zookeeper集群时,管理起来就很不方便啦!
zookeeper.connect=10.1.2.114:,10.1.2.115:,10.1.2.116:,10.1.2.117:,10.1.2.118:/yinzhengjie_kafka_test # 指定多久消费者更新offset到zookeeper中。注意offset更新时基于time而不是每次获得的消息。一旦在更新zookeeper发生异常并重启,将可能拿到已拿到过的消息,连接zk的超时时间
zookeeper.connection.timeout.ms= # 求的最大大小为字节,请求的最大字节数。这也是对最大记录尺寸的有效覆盖。注意:server具有自己对消息记录尺寸的覆盖,这些尺寸和这个设置不同。此项设置将会限制producer每次批量发送请的数目,以防发出巨量的请求。
max.request.size= ############################# Group Coordinator Settings ############################# # 在执行第一次重新平衡之前,组协调器将等待更多消费者加入新组的时间。更长的延迟意味着潜在的更少的重新平衡,但是增加了直到处理开始的时间。
group.initial.rebalance.delay.ms=
[root@node101 ~]#
[root@node101 ~]# cat /soft/kafka/config/server.properties #node101.yinzhengjie.org.cn的broker节点配置信息
[root@node102 ~]# cat /soft/kafka/config/server.properties
#kafka配置文档可参考自官网:
# http://kafka.apache.org/11/documentation.html#brokerconfigs。
# @author :yinzhengjie
# blog:http://www.cnblogs.com/yinzhengjie
# EMAIL:y1053419035@qq.com ############################# Server Basics ############################# # 每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况
broker.id= # 这就是说,这条命令其实并不执行删除动作,仅仅是在zookeeper上标记该topic要被删除而已,同时也提醒用户一定要提前打开delete.topic.enable开关,否则删除动作是不会执行的。推荐设置为true。
delete.topic.enable=true # 是否允许自动创建topic,默认值是true,若是false,就需要通过命令创建topic,推荐设置为false
auto.create.topics.enable=false # 0.11..0版本开始unclean.leader.election.enable参数的默认值由原来的true改为false,可以关闭unclean leader election,也就是不在ISR(IN-Sync Replica)列表中的replica,不会被提升为新的leader partition。kafka集群的持久化力大于可用性,如果ISR中没有其它的replica,会导致这个partition不能读写。
unclean.leader.election.enable=false ############################# Socket Server Settings #############################
# broker 监听器的CSV列表,格式为:[协议]://[主机名]:[端口],[[协议]]://[主机名]:[端口]].该参数主要用于可混搭链接broker使用,可以认为是broker端开放给clients的监听端口。如果不指定主机名,则表示绑定默认网卡;如果主机名是0.0.0.0,则表示绑定所有网卡。Kafka当前支持的协议类型包括PLAINTEXT,SSL及SASL_SSL等。对于新版本的Kafka,推荐值设置listerners一个参数就够了,对于已经过时的两个参数host.name和port,就不用再配置了。对于我未启用安全的Kafka集群,使用PLAINTEXT协议足以。如果启用的安全认证,可以考虑使用SSL或SAS_SSL协议。
listeners=SASL_PLAINTEXT://node102.yinzhengjie.org.cn:9092 # 设置协议,本例使用SASL_PLAINTEXT
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN # allow.everyone.if.no.acl.found参数是broker端端参数,不过有些奇怪的是,他并没记录在官网的broker端参数列表中(但我们可以在官网文档中看到这个参数,他只出现过一次:http://kafka.apache.org/documentation/#security_authz。)。当设置为true时,整个ACL机制将改为黑名单机制,即只有在黑名单中端用户才无法访问资源,非黑名单用户可以通常无阻端访问任何kafka资源;当参数为false时,也就是他端默认值时,ACL机制是白名单机制,只有白名单用户才能访问设定的资源,其他用户都属于未授权用户。
allow.everyone.if.no.acl.found=true # 设置yinzhengjie为超级用户,注意,这个用户是你需要在JAAS文件中指定的哟~
super.users=User:yinzhengjie # 配置ACL入口类
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer # 和listeners类似,该参数也是用于发布给clients的监听器,不过该参数主要用于IaaS环境,比如运上的机器通常都配有多块网卡(私网网卡和公网网卡)。对于这种机器,用户可以设置该参数绑定公网IP供外部clients使用。然后配置上面的listers来绑定私网IP供broker间通信使用。当然不设置该参数也是可以的,只是云上的机器很容易出现clients无法获取数据的问题,原因就是listeners绑定的是默认网卡,而默认网卡通常都是绑定绑定私网IP的。在实际使用场景中,对于配有多块网卡的机器而言,这个参数通常都是需要配置的。
#advertised.listeners=SASL_PLAINTEXT://node102.yinzhengjie.org.cn:9092 # 将侦听器名称映射到安全协议,默认情况下是相同的。在侦听器名称和安全协议之间映射。对于要在多个端口或IP中使用的相同安全协议,必须定义该安全协议。例如,内部和外部通信量可以分开,即使两者都需要SSL。具体地说,用户可以定义名称为INTERNAL和EXTERNAL的侦听器,该属性为:“INTERNAL:SSL,EXTERNAL:SSL”。如图所示,键和值用冒号分隔,映射项用逗号分隔。每个侦听器名称只在地图中出现一次。可以通过向配置名称添加规范化前缀(侦听器名称小写)来为每个侦听器配置不同的安全性(SSL和SASL)设置。例如,为了为INTERNAL侦听器设置不同的密钥存储,将设置名为“listener.name...ssl.keystore.location”的配置。如果未设置侦听器名称的配置,则配置将返回到通用配置(即`ssl.keystore.location')。详情请参考官网文档:http://kafka.apache.org/11/documentation.html#brokerconfigs。
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL # 它控制来一个broker在后台用于处理网络请求的线程数,默认是3。通常情况下,broker启动时会创建多个线程处理来自其他broker和clients发送过来的各种请求。注意,这里的“处理”其实只是负责转发请求,它会将接收到的请求转发到后面的处理线程中。在实际生产环境中,咱们需要不断的监控NetworkProcessorAvgIdlePercent JMX指标。如果该参数指标持续低于0.,建议适当增加该参数的值。
num.network.threads= # 这个参数就是控制broker端实际处理网络请求的线程数,默认值是8,即kafka borker默认创建8个线程以轮询的方式不停地监听转发过来的网络请求并进行实时处理。Kafka同样也为请求处理提供了一个JMX监控指标Request HandlerAvgIdlePercent。如果该参数指标持续低于0.,建议适当增加该参数的值。
num.io.threads= # 接字服务器使用的发送缓冲区(SOYSNDBUF), Socket服务器套接字的SOYSNDBUF缓冲区。如果值为-,则将使用OS默认值。
socket.send.buffer.bytes= # 接字服务器使用的接收缓冲区(SOYRCVBUF),用于网络请求的套接字接收缓冲器.
socket.receive.buffer.bytes= # 接字服务器将接受的请求的最大大小(对OOM的保护).
socket.request.max.bytes= # I/O线程等待队列中的最大的请求数,超过这个数量,network线程就不会再接收一个新的请求。应该是一种自我保护机制。
queued.max.requests= ############################# Log Basics ############################# # 该参数制定了Kafka持久化消息的目录。若待保存的消息数量非常多,那么最好确保该文件夹有充足的磁盘空间。该参数可以设置多个目录,以都好进行分隔。指定多个目录的做法通常是被推荐的,配置多个目录可以提升读写的能力,换句话说,就是提升Kafka的吞吐量。
log.dirs=/home/yinzhengjie/data/kafka/logs,/home/yinzhengjie/data/kafka/logs2,/home/yinzhengjie/data/kafka/logs3 # 在启动时恢复日志和关闭时刷盘日志时每个数据目录的线程的数量,默认1。这个值总共开启的线程数=num.recovery.threads.per.data.dir * log.dirs的数量。举个例子,假如log.dirs指定了3个目录,且num.recovery.threads.per.data.dir配置的是10,那么总共会开启30个线程会在broker停止或者启动时去加载或写入数据到磁盘中。理论上说我们应该适当增大这个值,以达到启动或者停止broker更快的目的,这个参数也就在broker启动和停止时才会起到一定的作用,而broker在启动或者停止的期间borker是无法正常提供服务的,因此我建议大家适当增大这个值以减少broker的启动时间。
num.recovery.threads.per.data.dir= # 服务器接受单个消息的最大大小,即消息体的最大大小,单位是字节
message.max.bytes= # 每当broker停止或崩溃领导时,该broker的分区转移到其他副本。这意味着默认情况下,当代理重新启动时,它将只是所有分区的跟随者,这意味着它不会用于客户端读取和写入。为了避免这种不平衡,Kafka有一个首选复制品的概念。如果分区的副本列表是1,,,则节点1首选作为节点5或9的引导者,因为它在副本列表中较早。您可以让Kafka群集通过运行命令尝试恢复已恢复副本的领导:"kafka-preferred-replica-election.sh --zookeeper zk_host:port/chroot " 由于运行此命令可能很繁琐,您还可以通过设置以下配置来配置Kafka自动执行此操作:auto.leader.rebalance.enable=true。当然,你可以不配置该参数,因为官方默认的配置是true。
auto.leader.rebalance.enable=true # 在强制fsync一个partition的log文件之前暂存的消息数量。调低这个值会更频繁的sync数据到磁盘,影响性能。通常建议人家使用replication来确保持久性,而不是依靠单机上的fsync,但是这可以带来更多的可靠性.
log.flush.interval.ms= ############################# Log Retention Policy ############################# # 这个参数是指定时间数据可以在kafka集群的保留时间。Kafka通常根据时间来决定数据可以被保留多久。默认使用log.retention.hours参数来配置时间,默认是168小时,也就是1周。除此之外,还有其他两个参数log.retention.minutes和log.retention.ms。这3个参数的作用是一样的,都是决定消息多久以后被删除,不过还是推荐使用log.retention.ms。如果指定了不止一个参数,Kafka会优先使用具有最小值的那个参数。
log.retention.hours= # 另一种方式是通过保留的消息字节数来判断消息是否过期。他的值通过参数log.retention.bytes来指定,作用在每一个分区上,也就是说,如果一个包含8个分区的主题,并且log.retention.bytes被设置为1GB,那么这个主题最多可以保留8GB的数据。所以,当主题的分区个数增加时,整个主题可以保留的数据也随之增加。温馨提示:如果同时指定log.retention.bytes和log.retention.ms(或者log.retention.hours或log.retention.minutes),只要任意一个条件得到满足,消息就会被删除。
#log.retention.bytes= # 以上的设置都作用在日志片段上,而不是作用在单个消息上。当消息达到broker时,他们被加分区的当前日志片段上。当日志片段大小达到log.segment.bytes指定的上线(默认是1GB)时,当前日志片段就会被关闭,一个新的日志片段被打开。如果一个日志片段被关闭,就开始等待过期。这个参数的值越小,就越会频繁的关闭和分破新文件,从而降低磁盘写入的整体效率。换句话说:它是控制日志segment文件的大小,超出该大小则追加到一个新的日志segment文件中(-1表示没有限制)
log.segment.bytes= # 日志片段文件的检查周期,查看它们是否达到了删除策略的设置(log.retention.hours或log.retention.bytes)
log.retention.check.interval.ms= ############################# Zookeeper ############################# # 用于保存broker元数据的zookeeper地址是通过zookeeper.connect来指定的。大家发现没有,下面就是我5台zookeeper地址,最后的“kafka_yinzhengjie_cluster1”表示zookeeper路径,作为kafka的chroot环境,如果不指定,默认使用根路径。推荐大家配置chroot路径,因为这样的话,当你部署多个kafka集群时可以共享同一套zookeeper集群,方便你维护。当然如果你不指定的话,它默认是在zookeeper的根路径创建,这样当你其他业务在使用zookeeper集群时,管理起来就很不方便啦!
zookeeper.connect=10.1.2.114:,10.1.2.115:,10.1.2.116:,10.1.2.117:,10.1.2.118:/yinzhengjie_kafka_test # 指定多久消费者更新offset到zookeeper中。注意offset更新时基于time而不是每次获得的消息。一旦在更新zookeeper发生异常并重启,将可能拿到已拿到过的消息,连接zk的超时时间
zookeeper.connection.timeout.ms= # 求的最大大小为字节,请求的最大字节数。这也是对最大记录尺寸的有效覆盖。注意:server具有自己对消息记录尺寸的覆盖,这些尺寸和这个设置不同。此项设置将会限制producer每次批量发送请的数目,以防发出巨量的请求。
max.request.size= ############################# Group Coordinator Settings ############################# # 在执行第一次重新平衡之前,组协调器将等待更多消费者加入新组的时间。更长的延迟意味着潜在的更少的重新平衡,但是增加了直到处理开始的时间。
group.initial.rebalance.delay.ms=
[root@node102 ~]#
[root@node102 ~]# cat /soft/kafka/config/server.properties #node102.yinzhengjie.org.cn的broker节点配置信息
[root@node103 ~]# cat /soft/kafka/config/server.properties
#kafka配置文档可参考自官网:
# http://kafka.apache.org/11/documentation.html#brokerconfigs。
# @author :yinzhengjie
# blog:http://www.cnblogs.com/yinzhengjie
# EMAIL:y1053419035@qq.com ############################# Server Basics ############################# # 每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况
broker.id= # 这就是说,这条命令其实并不执行删除动作,仅仅是在zookeeper上标记该topic要被删除而已,同时也提醒用户一定要提前打开delete.topic.enable开关,否则删除动作是不会执行的。推荐设置为true。
delete.topic.enable=true # 是否允许自动创建topic,默认值是true,若是false,就需要通过命令创建topic,推荐设置为false
auto.create.topics.enable=false # 0.11..0版本开始unclean.leader.election.enable参数的默认值由原来的true改为false,可以关闭unclean leader election,也就是不在ISR(IN-Sync Replica)列表中的replica,不会被提升为新的leader partition。kafka集群的持久化力大于可用性,如果ISR中没有其它的replica,会导致这个partition不能读写。
unclean.leader.election.enable=false ############################# Socket Server Settings #############################
# broker 监听器的CSV列表,格式为:[协议]://[主机名]:[端口],[[协议]]://[主机名]:[端口]].该参数主要用于可混搭链接broker使用,可以认为是broker端开放给clients的监听端口。如果不指定主机名,则表示绑定默认网卡;如果主机名是0.0.0.0,则表示绑定所有网卡。Kafka当前支持的协议类型包括PLAINTEXT,SSL及SASL_SSL等。对于新版本的Kafka,推荐值设置listerners一个参数就够了,对于已经过时的两个参数host.name和port,就不用再配置了。对于我未启用安全的Kafka集群,使用PLAINTEXT协议足以。如果启用的安全认证,可以考虑使用SSL或SAS_SSL协议。
listeners=SASL_PLAINTEXT://node103.yinzhengjie.org.cn:9092 # 设置协议,本例使用SASL_PLAINTEXT
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN # allow.everyone.if.no.acl.found参数是broker端端参数,不过有些奇怪的是,他并没记录在官网的broker端参数列表中(但我们可以在官网文档中看到这个参数,他只出现过一次:http://kafka.apache.org/documentation/#security_authz。)。当设置为true时,整个ACL机制将改为黑名单机制,即只有在黑名单中端用户才无法访问资源,非黑名单用户可以通常无阻端访问任何kafka资源;当参数为false时,也就是他端默认值时,ACL机制是白名单机制,只有白名单用户才能访问设定的资源,其他用户都属于未授权用户。
allow.everyone.if.no.acl.found=true # 设置yinzhengjie为超级用户,注意,这个用户是你需要在JAAS文件中指定的哟~
super.users=User:yinzhengjie # 配置ACL入口类
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer # 和listeners类似,该参数也是用于发布给clients的监听器,不过该参数主要用于IaaS环境,比如运上的机器通常都配有多块网卡(私网网卡和公网网卡)。对于这种机器,用户可以设置该参数绑定公网IP供外部clients使用。然后配置上面的listers来绑定私网IP供broker间通信使用。当然不设置该参数也是可以的,只是云上的机器很容易出现clients无法获取数据的问题,原因就是listeners绑定的是默认网卡,而默认网卡通常都是绑定绑定私网IP的。在实际使用场景中,对于配有多块网卡的机器而言,这个参数通常都是需要配置的。
#advertised.listeners=SASL_PLAINTEXT://node103.yinzhengjie.org.cn:9092 # 将侦听器名称映射到安全协议,默认情况下是相同的。在侦听器名称和安全协议之间映射。对于要在多个端口或IP中使用的相同安全协议,必须定义该安全协议。例如,内部和外部通信量可以分开,即使两者都需要SSL。具体地说,用户可以定义名称为INTERNAL和EXTERNAL的侦听器,该属性为:“INTERNAL:SSL,EXTERNAL:SSL”。如图所示,键和值用冒号分隔,映射项用逗号分隔。每个侦听器名称只在地图中出现一次。可以通过向配置名称添加规范化前缀(侦听器名称小写)来为每个侦听器配置不同的安全性(SSL和SASL)设置。例如,为了为INTERNAL侦听器设置不同的密钥存储,将设置名为“listener.name...ssl.keystore.location”的配置。如果未设置侦听器名称的配置,则配置将返回到通用配置(即`ssl.keystore.location')。详情请参考官网文档:http://kafka.apache.org/11/documentation.html#brokerconfigs。
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL # 它控制来一个broker在后台用于处理网络请求的线程数,默认是3。通常情况下,broker启动时会创建多个线程处理来自其他broker和clients发送过来的各种请求。注意,这里的“处理”其实只是负责转发请求,它会将接收到的请求转发到后面的处理线程中。在实际生产环境中,咱们需要不断的监控NetworkProcessorAvgIdlePercent JMX指标。如果该参数指标持续低于0.,建议适当增加该参数的值。
num.network.threads= # 这个参数就是控制broker端实际处理网络请求的线程数,默认值是8,即kafka borker默认创建8个线程以轮询的方式不停地监听转发过来的网络请求并进行实时处理。Kafka同样也为请求处理提供了一个JMX监控指标Request HandlerAvgIdlePercent。如果该参数指标持续低于0.,建议适当增加该参数的值。
num.io.threads= # 接字服务器使用的发送缓冲区(SOYSNDBUF), Socket服务器套接字的SOYSNDBUF缓冲区。如果值为-,则将使用OS默认值。
socket.send.buffer.bytes= # 接字服务器使用的接收缓冲区(SOYRCVBUF),用于网络请求的套接字接收缓冲器.
socket.receive.buffer.bytes= # 接字服务器将接受的请求的最大大小(对OOM的保护).
socket.request.max.bytes= # I/O线程等待队列中的最大的请求数,超过这个数量,network线程就不会再接收一个新的请求。应该是一种自我保护机制。
queued.max.requests= ############################# Log Basics ############################# # 该参数制定了Kafka持久化消息的目录。若待保存的消息数量非常多,那么最好确保该文件夹有充足的磁盘空间。该参数可以设置多个目录,以都好进行分隔。指定多个目录的做法通常是被推荐的,配置多个目录可以提升读写的能力,换句话说,就是提升Kafka的吞吐量。
log.dirs=/home/yinzhengjie/data/kafka/logs,/home/yinzhengjie/data/kafka/logs2,/home/yinzhengjie/data/kafka/logs3 # 在启动时恢复日志和关闭时刷盘日志时每个数据目录的线程的数量,默认1。这个值总共开启的线程数=num.recovery.threads.per.data.dir * log.dirs的数量。举个例子,假如log.dirs指定了3个目录,且num.recovery.threads.per.data.dir配置的是10,那么总共会开启30个线程会在broker停止或者启动时去加载或写入数据到磁盘中。理论上说我们应该适当增大这个值,以达到启动或者停止broker更快的目的,这个参数也就在broker启动和停止时才会起到一定的作用,而broker在启动或者停止的期间borker是无法正常提供服务的,因此我建议大家适当增大这个值以减少broker的启动时间。
num.recovery.threads.per.data.dir= # 服务器接受单个消息的最大大小,即消息体的最大大小,单位是字节
message.max.bytes= # 每当broker停止或崩溃领导时,该broker的分区转移到其他副本。这意味着默认情况下,当代理重新启动时,它将只是所有分区的跟随者,这意味着它不会用于客户端读取和写入。为了避免这种不平衡,Kafka有一个首选复制品的概念。如果分区的副本列表是1,,,则节点1首选作为节点5或9的引导者,因为它在副本列表中较早。您可以让Kafka群集通过运行命令尝试恢复已恢复副本的领导:"kafka-preferred-replica-election.sh --zookeeper zk_host:port/chroot " 由于运行此命令可能很繁琐,您还可以通过设置以下配置来配置Kafka自动执行此操作:auto.leader.rebalance.enable=true。当然,你可以不配置该参数,因为官方默认的配置是true。
auto.leader.rebalance.enable=true # 在强制fsync一个partition的log文件之前暂存的消息数量。调低这个值会更频繁的sync数据到磁盘,影响性能。通常建议人家使用replication来确保持久性,而不是依靠单机上的fsync,但是这可以带来更多的可靠性.
log.flush.interval.ms= ############################# Log Retention Policy ############################# # 这个参数是指定时间数据可以在kafka集群的保留时间。Kafka通常根据时间来决定数据可以被保留多久。默认使用log.retention.hours参数来配置时间,默认是168小时,也就是1周。除此之外,还有其他两个参数log.retention.minutes和log.retention.ms。这3个参数的作用是一样的,都是决定消息多久以后被删除,不过还是推荐使用log.retention.ms。如果指定了不止一个参数,Kafka会优先使用具有最小值的那个参数。
log.retention.hours= # 另一种方式是通过保留的消息字节数来判断消息是否过期。他的值通过参数log.retention.bytes来指定,作用在每一个分区上,也就是说,如果一个包含8个分区的主题,并且log.retention.bytes被设置为1GB,那么这个主题最多可以保留8GB的数据。所以,当主题的分区个数增加时,整个主题可以保留的数据也随之增加。温馨提示:如果同时指定log.retention.bytes和log.retention.ms(或者log.retention.hours或log.retention.minutes),只要任意一个条件得到满足,消息就会被删除。
#log.retention.bytes= # 以上的设置都作用在日志片段上,而不是作用在单个消息上。当消息达到broker时,他们被加分区的当前日志片段上。当日志片段大小达到log.segment.bytes指定的上线(默认是1GB)时,当前日志片段就会被关闭,一个新的日志片段被打开。如果一个日志片段被关闭,就开始等待过期。这个参数的值越小,就越会频繁的关闭和分破新文件,从而降低磁盘写入的整体效率。换句话说:它是控制日志segment文件的大小,超出该大小则追加到一个新的日志segment文件中(-1表示没有限制)
log.segment.bytes= # 日志片段文件的检查周期,查看它们是否达到了删除策略的设置(log.retention.hours或log.retention.bytes)
log.retention.check.interval.ms= ############################# Zookeeper ############################# # 用于保存broker元数据的zookeeper地址是通过zookeeper.connect来指定的。大家发现没有,下面就是我5台zookeeper地址,最后的“kafka_yinzhengjie_cluster1”表示zookeeper路径,作为kafka的chroot环境,如果不指定,默认使用根路径。推荐大家配置chroot路径,因为这样的话,当你部署多个kafka集群时可以共享同一套zookeeper集群,方便你维护。当然如果你不指定的话,它默认是在zookeeper的根路径创建,这样当你其他业务在使用zookeeper集群时,管理起来就很不方便啦!
zookeeper.connect=10.1.2.114:,10.1.2.115:,10.1.2.116:,10.1.2.117:,10.1.2.118:/yinzhengjie_kafka_test # 指定多久消费者更新offset到zookeeper中。注意offset更新时基于time而不是每次获得的消息。一旦在更新zookeeper发生异常并重启,将可能拿到已拿到过的消息,连接zk的超时时间
zookeeper.connection.timeout.ms= # 求的最大大小为字节,请求的最大字节数。这也是对最大记录尺寸的有效覆盖。注意:server具有自己对消息记录尺寸的覆盖,这些尺寸和这个设置不同。此项设置将会限制producer每次批量发送请的数目,以防发出巨量的请求。
max.request.size= ############################# Group Coordinator Settings ############################# # 在执行第一次重新平衡之前,组协调器将等待更多消费者加入新组的时间。更长的延迟意味着潜在的更少的重新平衡,但是增加了直到处理开始的时间。
group.initial.rebalance.delay.ms=
[root@node103 ~]#
[root@node103 ~]# cat /soft/kafka/config/server.properties #node103.yinzhengjie.org.cn的broker节点配置信息
启动broker服务器。
[root@node101 ~]# which xkafka.sh
/usr/local/bin/xkafka.sh
[root@node101 ~]#
[root@node101 ~]#
[root@node101 ~]# cat /usr/local/bin/xkafka.sh
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -ne ];then
echo "无效参数,用法为: $0 {start|stop}"
exit
fi #获取用户输入的命令
cmd=$ for (( i= ; i<= ; i++ )) ; do
tput setaf
echo ========== node${i}.yinzhengjie.org.cn $cmd ================
tput setaf
case $cmd in
start)
ssh node${i}.yinzhengjie.org.cn "source /etc/profile ; yinzhengjie-security-kafka-server-start.sh -daemon /soft/kafka/config/server.properties"
echo node${i}.yinzhengjie.org.cn "服务已启动"
;;
stop)
ssh node${i}.yinzhengjie.org.cn "source /etc/profile ; kafka-server-stop.sh"
echo node${i}.yinzhengjie.org.cn "服务已停止"
;;
*)
echo "无效参数,用法为: $0 {start|stop}"
exit
;;
esac
done
[root@node101 ~]#
[root@node101 ~]# cat /usr/local/bin/xkafka.sh #编写kafka集群的启动脚本,在测试环境中可以使用,但在实际生产环境中不推荐使用!
[root@node101 logs]# xkafka.sh start
========== node101.yinzhengjie.org.cn start ================
node101.yinzhengjie.org.cn 服务已启动
========== node102.yinzhengjie.org.cn start ================
node102.yinzhengjie.org.cn 服务已启动
========== node103.yinzhengjie.org.cn start ================
node103.yinzhengjie.org.cn 服务已启动
[root@node101 logs]#
[root@node101 logs]#
[root@node101 logs]# xcall.sh jps
============= node101.yinzhengjie.org.cn : jps ============
Kafka
Jps
Main
命令执行成功
============= node102.yinzhengjie.org.cn : jps ============
Kafka
Jps
命令执行成功
============= node103.yinzhengjie.org.cn : jps ============
Kafka
Jps
命令执行成功
[root@node101 logs]#
[root@node101 logs]# xkafka.sh start #启动kafka集群
[root@yinzhengjie ~]# kafka-topics.sh --zookeeper 10.1.2.118/yinzhengjie_kafka_test --list #kafka启动后,我们在zookeeper查看元数据信息,发现并没topic
[root@yinzhengjie ~]#
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# kafka-topics.sh --create --zookeeper 10.1.2.118/yinzhengjie_kafka_test --topic yinzhengjie-kafka --partitions --replication-factor 2 #于是,我们可以创建kafka topic便于测试kafka写入和读取
Created topic "yinzhengjie-kafka".
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# kafka-topics.sh --zookeeper 10.1.2.118/yinzhengjie_kafka_test --list #再次查看kafka的topic列表
yinzhengjie-kafka
[root@yinzhengjie ~]#
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# kafka-topics.sh --zookeeper 10.1.2.118/yinzhengjie_kafka_test --describe --topic yinzhengjie-kafka #查看kafka的详细信息
Topic:yinzhengjie-kafka PartitionCount: ReplicationFactor: Configs:
Topic: yinzhengjie-kafka Partition: Leader: Replicas: , Isr: ,
Topic: yinzhengjie-kafka Partition: Leader: Replicas: , Isr: ,
Topic: yinzhengjie-kafka Partition: Leader: Replicas: , Isr: ,
Topic: yinzhengjie-kafka Partition: Leader: Replicas: , Isr: ,
Topic: yinzhengjie-kafka Partition: Leader: Replicas: , Isr: ,
Topic: yinzhengjie-kafka Partition: Leader: Replicas: , Isr: ,
Topic: yinzhengjie-kafka Partition: Leader: Replicas: , Isr: ,
Topic: yinzhengjie-kafka Partition: Leader: Replicas: , Isr: ,
Topic: yinzhengjie-kafka Partition: Leader: Replicas: , Isr: ,
Topic: yinzhengjie-kafka Partition: Leader: Replicas: , Isr: ,
[root@yinzhengjie ~]#
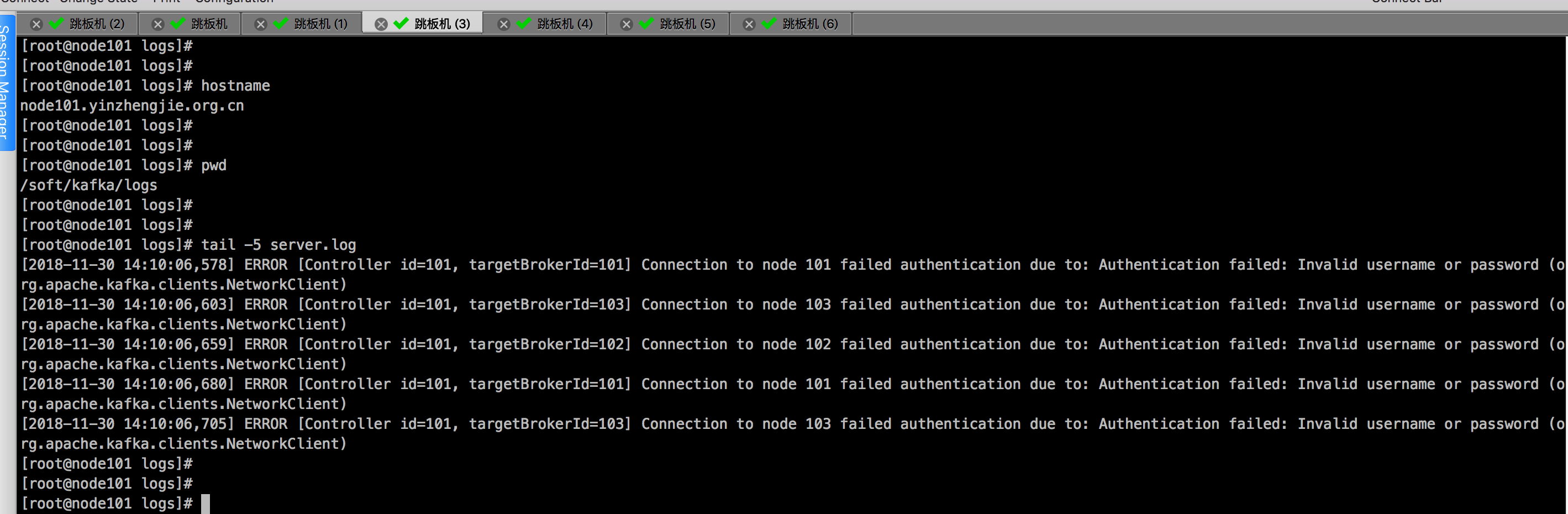
细心的同学可能已经发现了,我们不是启用了ACL吗?为什么客户端还能成功创建topic呢?这是因为当前“kafka-topics.sh”脚本是直接链接zookeeper的,完全绕过了ACL审查机制,故不受ACL的限制。所以无论是否配置了ACL,用户总是可以使用kafka-topics.sh来管理topic。所以,在实际使用过程中,最好能对链接zookeeper的用户也增加认证机制。言归正传,本例中我们的目的是要测试是否用户writer向“yinzhengjie-kafka”topic写入消息以及用户reader从“yinzhengjie-kafka”读取消息。很希然,当前的生产者和消费者都无法工作,报的错误就是无法链接broker(node101.yinzhengjie.org.cn:9092)。这是因为我们开启了认证机制。下面是日志信息。
[root@1yinzhengjie ~]# kafka-console-producer.sh --broker-list node101.yinzhengjie.org.cn: --topic yinzhengjie-kafka
尹正杰到此一游!!!
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
^C[root@yinzhengjie ~]#
[root@yinzhengjie ~]#
[root@1yinzhengjie ~]# kafka-console-producer.sh --broker-list node101.yinzhengjie.org.cn:9092 --topic yinzhengjie-kafka #启动生产者
[root@yinzhengjie ~]# kafka-console-consumer.sh --bootstrap-server node101.yinzhengjie.org.cn: --topic yinzhengjie-kafka --from-beginning
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Bootstrap broker node101.yinzhengjie.org.cn: disconnected (org.apache.kafka.clients.NetworkClient)
^C[root@yinzhengjie ~]#
[root@yinzhengjie ~]# kafka-console-consumer.sh --bootstrap-server node101.yinzhengjie.org.cn:9092 --topic yinzhengjie-kafka --from-beginning #启动消费者
其实,我们可以查看此时的broker的日志信息,会有以下报错:
2>.produce端的配置
若要往开启SASL和ACL机制的kafka集群写入数据,我们需要在produce端进行三个方面的设置。
第一:编写JAAS配置文件;
第二:修改produce端的启动脚本,将第一步编写的JAAS文件的路径写入;
第三:使用kafka-alcs.sh进行写入权限的授权操作;
下面我们为writer用户破诶值认证信息,首先需要创建一个属于writer用户的JAAS文件,该文件中指定用户writer的链接信息如下:
[root@yinzhengjie ~]# cat /yinzhengjie/softwares/kafkasoft/kafka/kafka_2.-1.1./config/yinzhengjie-writer-jaas.conf
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="writer"
password="writer"; #注意这个分号别忘记写啦!
};
[root@yinzhengjie ~]#
编写kafka的启动脚本,指定“yinzhengjie-writer-jaas.conf”配置文件的绝对路径。
[root@yinzhengjie ~]# cp /yinzhengjie/softwares/kafkasoft/kafka/kafka_2.-1.1./bin/kafka-console-producer.sh /yinzhengjie/softwares/kafkasoft/kafka/kafka_2.-1.1./bin/yinzhengjie-writer-kafka-console-producer.sh
[root@yinzhengjie ~]#
[root@yinzhengjie ~]# tail - /yinzhengjie/softwares/kafkasoft/kafka/kafka_2.-1.1./bin/yinzhengjie-writer-kafka-console-producer.sh
exec $(dirname $)/kafka-run-class.sh -Djava.security.auth.login.config=/yinzhengjie/softwares/kafkasoft/kafka/kafka_2.-1.1./config/yinzhengjie-writer-jaas.conf kafka.tools.ConsoleProducer "$@"
[root@yinzhengjie ~]#
接下来,我们需要给produce端进行授权操作,即运行那个用户写入数据,授权操作需要使用“kafka-acls.sh”这个脚本。这个脚本的使用大家可以参考Apache kafka官网文档,也可以参考confluent官网:https://docs.confluent.io/current/kafka/authorization.html#overview。既然是生产者,我们需要赋给它对应topic的写入权限,故执行以下命令创建对应的ACL规则:
[root@yinzhengjie ~]# kafka-acls.sh --authorizer kafka.security.auth.SimpleAclAuthorizer --authorizer-properties zookeeper.connect=10.1.2.118: --add --allow-principal User:writer --operation Write --topic yinzhengjie-kafka
Adding ACLs for resource `Topic:yinzhengjie-kafka`:
User:writer has Allow permission for operations: Write from hosts: * Current ACLs for resource `Topic:yinzhengjie-kafka`:
User:writer has Allow permission for operations: Write from hosts: * [root@yinzhengjie ~]# 上述重要参数介绍:
principal:
表示一个kafka user。
operation:
表示一个具体的操作类型,如WRITE,READ,DESCRIBE等。
Host:
表示连向Kafka集群的client的IP地址,如果是“*”则表示所有IP。注意,当前Kafka不支持主机名,只能指定IP地址。
Resource:
表示一种kafka资源类型,当前共有4种类型:TOPIC,CLUSTER,GROUP和TRANSCTIONID。
授权后,我们就可以使用咱们修改后的生产者来往broker写入数据:
[root@--- config]# yinzhengjie-writer-kafka-console-producer.sh --broker-list node101.yinzhengjie.org.cn: --topic yinzhengjie-kafka --producer-property security.protocol=SASL_PLAINTEXT --producer-property sals.mechanism=PLAIN
当然,如果你不想每次启动时指定生产者的参数,我们可以把“--producer-property security.protocol=SASL_PLAINTEXT --producer-property sals.mechanism=PLAIN”这2个属性写入生产者的配置文件中。
[root@yinzhengjie ~]# tail - /yinzhengjie/softwares/kafkasoft/kafka/kafka_2.-1.1./config/producer.properties
#Add by yinzhengjie
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
[root@yinzhengjie ~]#
修改之后,我们启动生产者时需要指定生产者的配置文件,具体操作如下:
[root@yinzhengjie ~]# yinzhengjie-writer-kafka-console-producer.sh --broker-list 10.1.2.101: --topic yinzhengjie-kafka --producer.config /yinzhengjie/softwares/kafkasoft/kafka/kafka_2.-1.1./config/producer.properties
很奇怪的一个现象,我启动生产者总是报错说认证失败,而大家也看到我配置了认证,始终报错认证失败:(这个原因我暂时还没有解决掉,仍在调研中.....)
[root@yinzhengjie ~]# yinzhengjie-writer-kafka-console-producer.sh --broker-list 10.1.2.101: --topic yinzhengjie-kafka --producer.config /yinzhengjie/softwares/kafkasoft/ka
fka/kafka_2.-1.1./config/producer.properties [-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
[-- ::,] WARN Error while fetching metadata with correlation id : {yinzhengjie-kafka=TOPIC_AUTHORIZATION_FAILED} (org.apache.kafka.clients.NetworkClient)
^C[root@yinzhengjie ~]#
捣鼓了一天,没有捣鼓明白, 我决定先放一放,如果哪位大佬看到我的问题欢迎帮我指正,我先调研一下kafka集群监控度量指标。
3>.consumer端端配置
三.SSL加密
《Apache kafka实战》读书笔记-管理Kafka集群安全之ACL篇的更多相关文章
- kafka实战读书笔记
1.katka_2.12-l.0.0.tgz 上面两个文件中的 2.11 /2.12 分别表示编译 Kafka 的 Scala 语言版本,后面的 1.0 .0 是 Kafka的版本 . 2.kafka ...
- [redis读书笔记] 第二部分 集群
1. 一个集群会包含多个节点(一个节点就是一个reid是服务器),CLUST MEET <ip><port>可以添加一个node到集群,命令执行后,两个node之间就会进行握手 ...
- 机器学习实战 - 读书笔记(12) - 使用FP-growth算法来高效发现频繁项集
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第12章 - 使用FP-growth算法来高效发现频繁项集. 基本概念 FP-growt ...
- kafka实战教程(python操作kafka),kafka配置文件详解
kafka实战教程(python操作kafka),kafka配置文件详解 应用往Kafka写数据的原因有很多:用户行为分析.日志存储.异步通信等.多样化的使用场景带来了多样化的需求:消息是否能丢失?是 ...
- Kafka 0.9+Zookeeper3.4.6集群搭建、配置,新Client API的使用要点,高可用性测试,以及各种坑 (转载)
Kafka 0.9版本对java client的api做出了较大调整,本文主要总结了Kafka 0.9在集群搭建.高可用性.新API方面的相关过程和细节,以及本人在安装调试过程中踩出的各种坑. 关于K ...
- 【转】Kafka实战-Flume到Kafka
Kafka实战-Flume到Kafka Kafka 2015-07-03 08:46:24 发布 您的评价: 0.0 收藏 2收藏 1.概述 前面给大家介绍了整个Kafka ...
- Kafka实战-Flume到Kafka (转)
原文链接:Kafka实战-Flume到Kafka 1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来 ...
- iPhone与iPad开发实战读书笔记
iPhone开发一些读书笔记 手机应用分类1.教育工具2.生活工具3.社交应用4.定位工具5.游戏6.报纸和杂志的阅读器7.移动办公应用8.财经工具9.手机购物应用10.风景区相关应用11.旅游相关的 ...
- 使用Kafka的一些简单介绍: 1集群 2原理 3 术语
目录 第一节 Kafka 集群 Kafka 集群搭建 Kafka 集群快速搭建 第二节 集群管理工具 集群管理工具 集群 Issues 第三节 使用命令操纵集群 第四节 Kafka 术语说明 第五节 ...
随机推荐
- JSON笔记
JSPN示例1: { "firstName": "Brett", "lastName":"McLaughlin", &q ...
- BZOJ3144[Hnoi2013]切糕——最小割
题目描述 输入 第一行是三个正整数P,Q,R,表示切糕的长P. 宽Q.高R.第二行有一个非负整数D,表示光滑性要求.接下来是R个P行Q列的矩阵,第z个 矩阵的第x行第y列是v(x,y,z) (1≤x≤ ...
- MySQL 同一台服务器同步数据
声明:我配置出来的slave_io_running和slave_sql_running都是yes.但是数据并没有同步! 希望有遇到相同问题的朋友,能够告诉我一下解决方案? 首先,如何在同一个服务器安装 ...
- Json.net 反序列化 部分对象
主要通过 Jobject获取想要序列化的部分对象. 直接上代码 static void Main(string[] args) { //先反序列化看看 string json = "{\&q ...
- Suffix
$ 题目描述 给定一个序列\(A\),请你输出\(\sum_{1< i< j < k < h}A_iA_jA_kA_h(mod ~~1e9+7)\) \(Solution\) ...
- MT【308】投影的定义
已知向量$\overrightarrow{a},\overrightarrow{b}$满足:$|\overrightarrow{a}|=2$,向量$\overrightarrow{b}$与$\over ...
- python学习日记(格式化输出,初始编码,运算符)
格式化输出 顾名思义,按照个人意愿定制想输出的格式. name = input('请输入姓名:') age = int(input('请输入年龄:')) job = input('请输入工作:') h ...
- 三天STL与pbds(平板电视)
19.02.11 ~ 19.02.13 hjmmm要专攻STL辣 先列一下大纲? 第一天:各种基础容器 第二天:实现平衡树和平板电视pbds 第三天:非变异算法和变异算法 那么我们就开始吧! Day1 ...
- JXOI 2018 简要题解
目录 「JXOI2018」游戏 题意 题解 代码 「JXOI2018」守卫 题意 题解 代码 「JXOI2018」排序问题 题意 题解 代码 总结 「JXOI2018」游戏 题意 可怜公司有 \(n\ ...
- 子网站不继承父的WEBCONFIG
环境 W10 IIS10 / WIN2012 IIS上以前有一个网站,后来写了一个接口项目,需要当成WEB应用程序挂到这网站下. 在右击添加应用程序,指向接口项目后.发现访问不了接口项目.死活配置有 ...