大数据基础Hadoop 2.x入门
hadoop概述
- 存储和分析网络数据
- 三大组件
- MapReduce
- 对海量数据的处理
- 思想:
- 分而治之
- 每个数据集进行逻辑业务处理map
- 合并统计数据结果reduce
- HDFS
- 储存海量数据
- 分布式存储
- 安全性高
- 副本数据
- YARN
- 分布式资源管理框架
- 管理整个集群的资源(内存、CPU核数)
- 分配调度集群资源
- 分布式资源管理框架
- Common
- 工具
- MapReduce
hadoop生态圈
- Hive(蜜蜂)通过使用sql语句来执行hadoop任务
- HBase 存储结构化数据的分布式数据库
- HBase放弃了事务特性,追求更高的扩展
- 和HDFS不同的,HBase提供数据的随机读写和实时访问,实现对表数据的读写功能
- zookeeper 维护节点状态
Hadoop安装
- 使用docker安装
docker run -i -t -p 50070:50070 -p 9000:9000 -p 8088:8088 -p 8040:8040 -p 8042:8042 -p 49707:49707 -p 50010:50010 -p 50075:50075 -p 50090:50090 sequenceiq/hadoop-docker:2.6.0 /etc/bootstrap.sh -bash
HDFS基本概念
- 块 (Block)
- HDFS的文件被分成块进行存储
- HDFS块的默认大小64M
- 块是文件储存处理的逻辑单元
- NameNode
- NameNode是管理节点,存放文件元数据
- 文件与数据块的映射表
- 数据块与数据节点的映射表

- DataNode
- 是HDFS的工作节点,存放数据块
HDFS中数据管理与容错
数据块副本

心跳检测
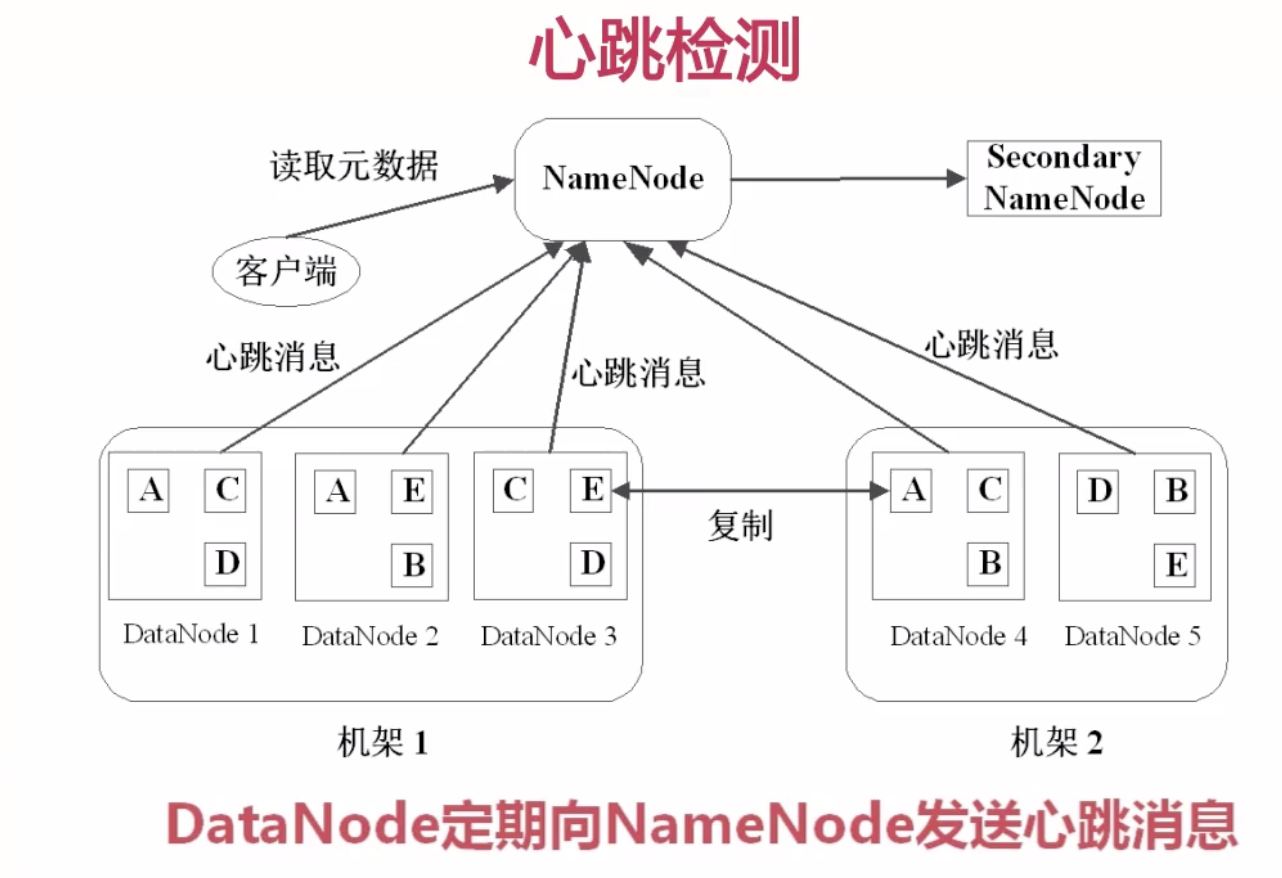
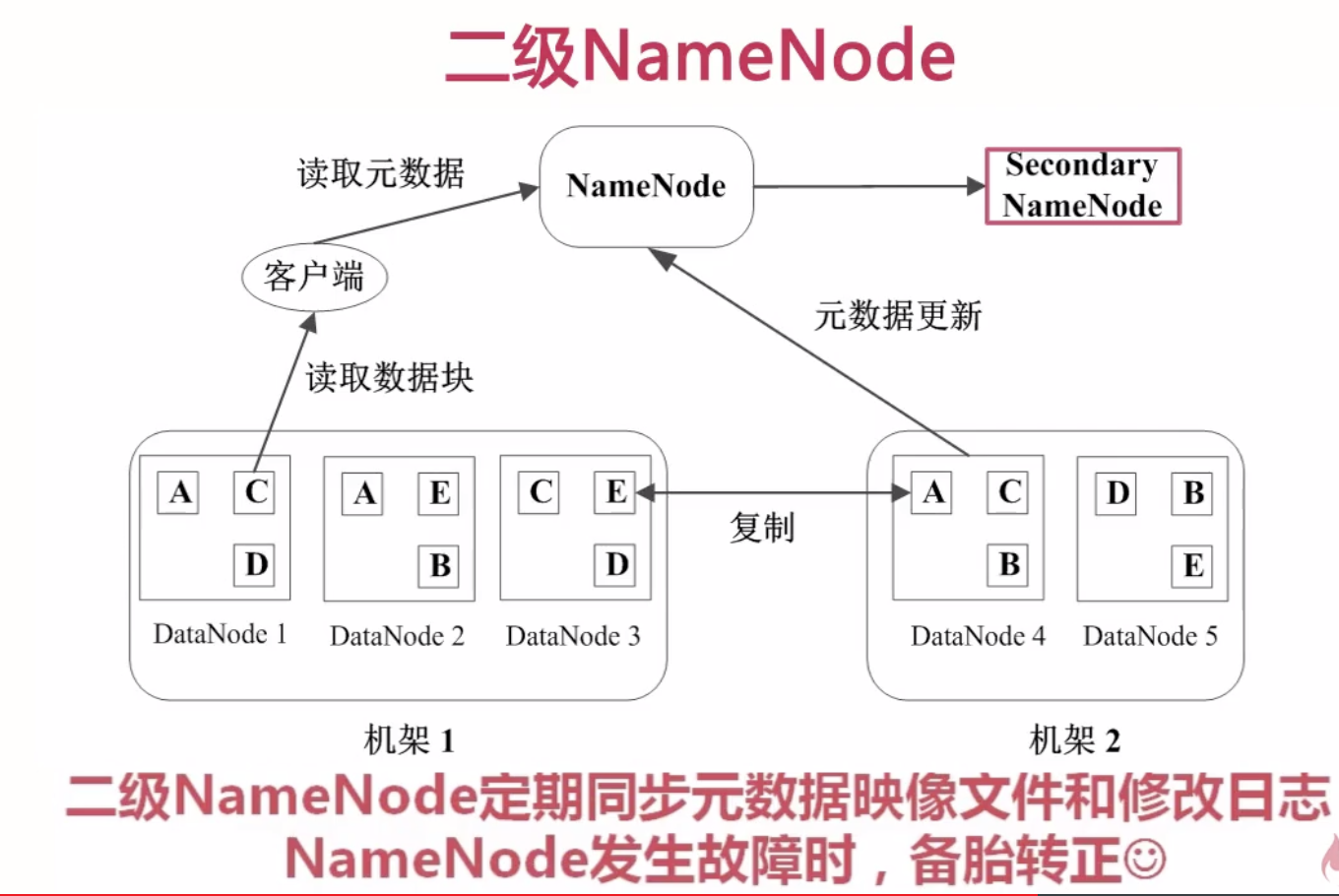
二级NameNode
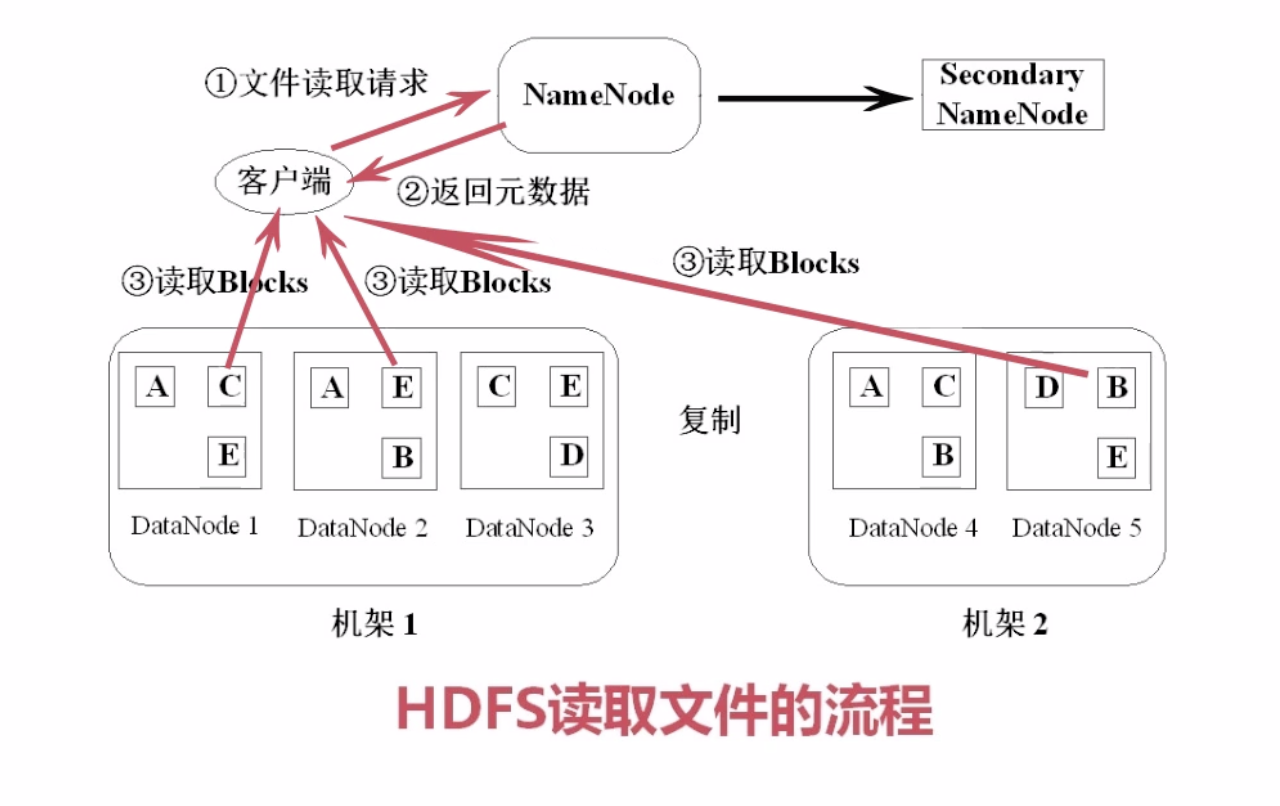
HDFS中文件读写的流程
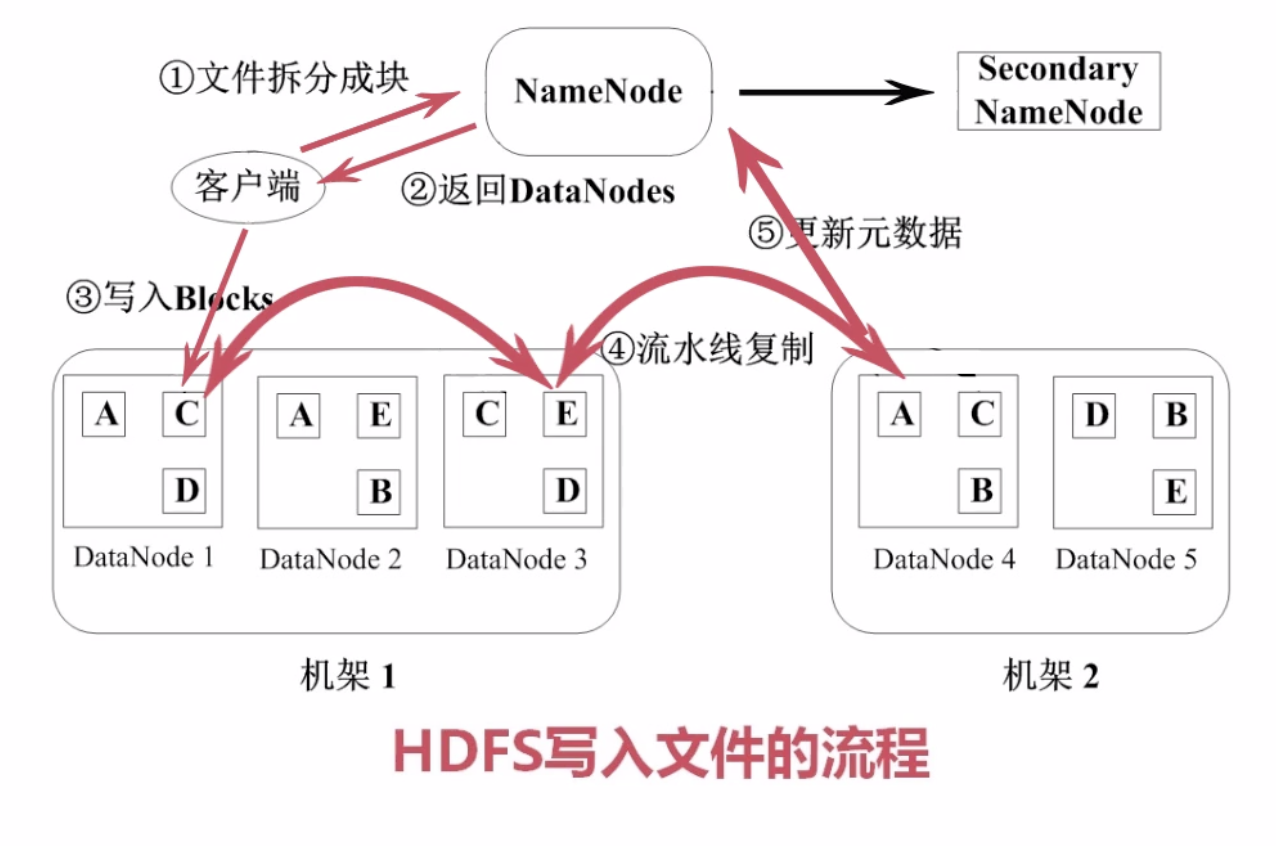
HDFS写入文件的流程
HDFS的特点
- 数据冗余,硬件容错
- 流式的数据访问
- 适合存储大文件
- 适合数据批量读写,吞吐量高
- 不适合交互式应用,低延迟很难满足
- 适合一次写入多次读取,顺序读写
- 不支持多用户并发写相同文件
HDFS命令行操作
- hadoop fs -ls /
- hadoop namenode -format 格式化操作
- hadoop fs -ls /user
- hadoop fs -put hadoop-env.sh /user/root 把文件放入hadoop
- hadoop fs -rm input
- hadoop fs -rm hadoop-env.sh
- hadoop fs -mkdir input
- hadoop fs -cat input/hadoop-env.sh
- hadoop fs -get input/hadoop-env.sh hadoop-env2.sh
- hadoop dfsadmin -report
MapReduce原理
- 分而治之,一个大人物分成多个小的子任务(map),并行执行后,合并结果(reduce)
- 比如:100GB的网站访问日志文件,找出访问次数最多的IP地址
- 根据日期切分,比如按周,每周一份进行统计
- 再合并到某几个机器进行分析合并
MapReduce运行流程
- 基本概念
- Job & Task 一个job就例如上面的例子,task可以分为map task和reduce task
- JobTracker
- 作业调度
- 分配任务、监控任务执行进度
- 监控TaskTracker的状态
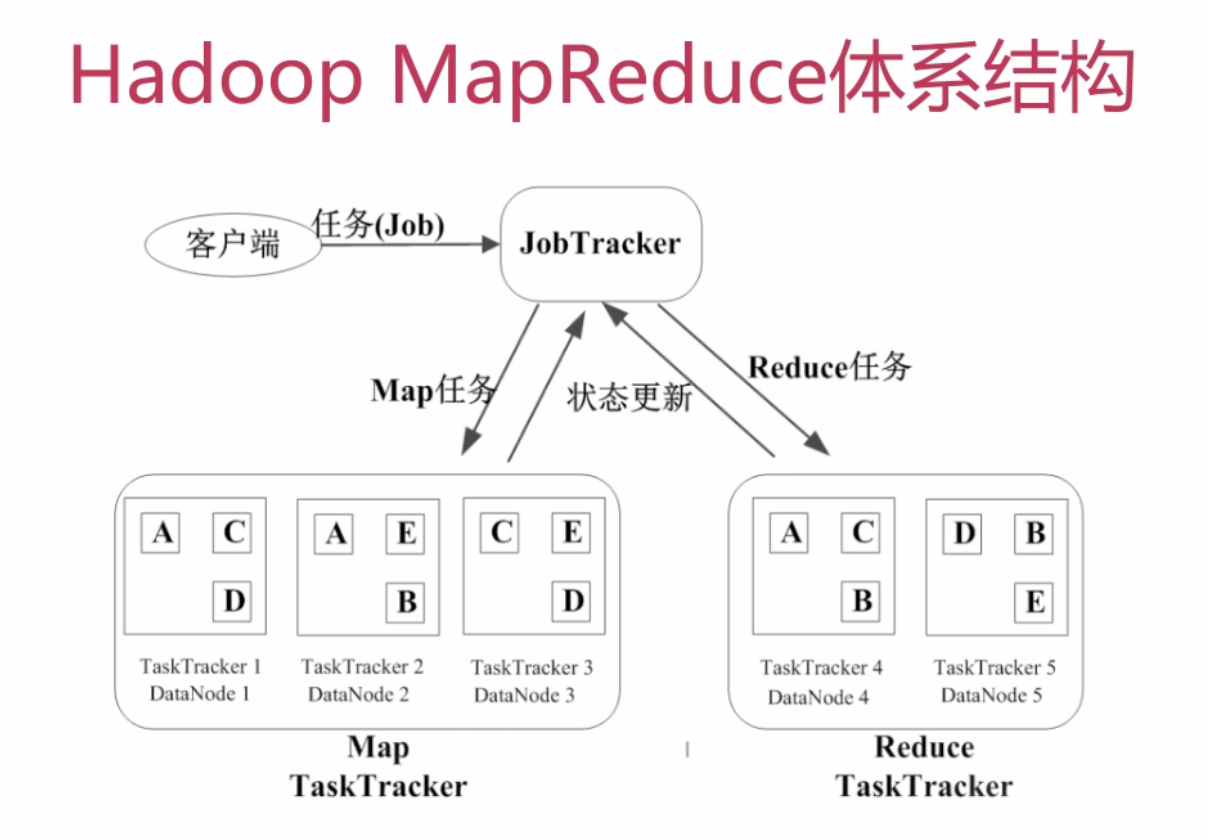
- TaskTracker
- 执行任务
- 汇报任务状态
- MapReduce作业执行过程

MapReduce的容错机制
- 重复执行
- 重复4次仍旧失败放弃
- 推测执行
- 假设有个TaskTracker执行特别慢,它会启动另一个TaskTracker执行相同的任务,两个谁先执行完,就放弃另一个
MapReduce应用
WordCount单词计数
- 由于我是docker安装,具体例子可以参考如下
- docker安装的容器里,自带了例子,位置是/usr/local/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar
大数据基础Hadoop 2.x入门的更多相关文章
- 【大数据系统架构师】1.2 大数据基础Hadoop 2.X
1. hadoop环境搭建 1.1 伪分布式环境搭建 1.1.1 伪分布式环境搭建 1.1.2 伪分布式搭建结果 hdfs可视化界面: http://od001:50070/dfshealth.htm ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- 大数据之Hadoop技术入门汇总
今天,小编对Hadoop入门学习知识进行了汇总,帮助大家更好地入手大数据.小编关于Hadoop入门总共发写了12篇原创文章,文章是参照尚硅谷大数据视频教程来进行撰写的. 今天,小编带你解锁正确的阅读顺 ...
- 大数据:Hadoop入门
大数据:Hadoop入门 一:什么是大数据 什么是大数据: (1.)大数据是指在一定时间内无法用常规软件对其内容进行抓取,管理和处理的数据集合,简而言之就是数据量非常大,大到无法用常规工具进行处理,如 ...
- Hadoop基础之初识大数据与Hadoop
前言 从今天起,我将一步一步的分享大数据相关的知识,其实很多程序员感觉大数据很难学,其实并不是你想象的这样,只要自己想学,还有什么难得呢? 学习Hadoop有一个8020原则,80%都是在不断的配置配 ...
- 大数据和Hadoop生态圈
大数据和Hadoop生态圈 一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop ...
- hadoop(一)之初识大数据与Hadoop
前言 从今天起,我将一步一步的分享大数据相关的知识,其实很多程序员感觉大数据很难学,其实并不是你想象的这样,只要自己想学,还有什么难得呢? 学习Hadoop有一个8020原则,80%都是在不断的配置配 ...
- 大数据和hadoop有什么关系?
本文资料来自百度文库相关文档 Hadoop,Spark和Storm是目前最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Storm常用于 ...
- Hadoop专业解决方案-第1章 大数据和Hadoop生态圈
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop生态圈小组已经翻译完成,在此 ...
随机推荐
- 腾讯开源的 Paxos库 PhxPaxos 代码解读---Accept阶段(一)
腾讯开源的 Paxos库 PhxPaxos 代码解读---Accept阶段(一) 在看Accept阶段代码之前, 我们再回想一下 Basic Paxos算法; 1. Basic Paxos 算法是为 ...
- Centos7下修改固定IP
1.直接关闭 NetworkManger 服务就好了, service NetworkManager stop, 并且禁止开机启动 chkconfig NetworkManager off 如何查看c ...
- mysql & sqlserver语法差异
isnull vs ifnull dateadd vs date_add limit vs top
- Java-常用工具方法
一 Json转换 1 输出组装好的json ObjectMapper mapper = new ObjectMapper(); try { String requiredJson = mapper.w ...
- 别人的Linux私房菜(13)学习Shell脚本
CentOS6.x以前版本的系统服务启动接口在/etc/init.d/目录下,存放了脚本. Shell脚本因调用外部命令和bash 的一些默认工具,速度较慢,不适合处理大量运算. 执行方式有:直接命令 ...
- # 2019-2020-4 《Java 程序设计》第六周总结
2019-2020-4 <Java 程序设计>第六周知识总结 第七章:内部类与异常类 1.内部类 (1)类可以有两种重要的成员:成员变量和方法,类还可以有一种成员:内部类. (2)java ...
- css摘要
由于需要,今天花三个小时了解一下css,在此记录一些摘要: 参考w3school 1. 当同一个 HTML 元素被不止一个样式定义时,会使用哪个样式呢? 一般而言,所有的样式会根据下面的规则层叠于一个 ...
- Mac os查看链接过的ssh key
https://shipengliang.com/software-exp/mac-os-如何管理ssh-key.html
- wcf生成客户端代理类步骤及语句
通过svcutil.exe工具生成客户端代理类和客户端的配置文件 .在运行中输入cmd打开命令行 ()cd C:\Program Files (x86)\Microsoft SDKs\Windows\ ...
- VS2015环境下生成和调用DLL动态链接库
一.生成动态链接库: 1.打开VS2015->文件->新建->项目->Visual C++->Win32->Win32控制台应用程序->将名称改为dll_ge ...