MapReduce编程之wordcount
实践
MapReduce编程之wordcount
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* 使用MapReduce开发WordCount的应用程序
*/
public class WordCountApp { /**
* Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
//按照指定分隔符进行拆分
String[] words = line.split(" ");
for(String word : words){
// 通过上下文把map的处理结果输出
context.write(new Text(word),one);
}
} } /**
* 归并操作
*/
public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for(LongWritable value : values){
//求key出现的次数和
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
} /**
* 定义Driver:封装lMapReduce作业的所有信息
* @param args
*/
public static void main(String[] args) throws Exception{
//创建configuration
Configuration configuration = new Configuration();
//准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
System.out.println("out file exists,but is has deleted!");
}
//创建job
Job job = Job.getInstance(configuration,"WordCount");
//设置job的处理类
job.setJarByClass(WordCountApp.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
//设置map相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce相关参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job , new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行
hadoop jar hadoop-train-1.0-SNAPSHOT.jar WordCountApp /hdfsapi/test/b.txt /hdfsapi/test/out
MapReduce编程之Combiner
本地reduce(map端reduce)
减少Map Tasks输出的数据量及数据网络传输量
combiner案例开发
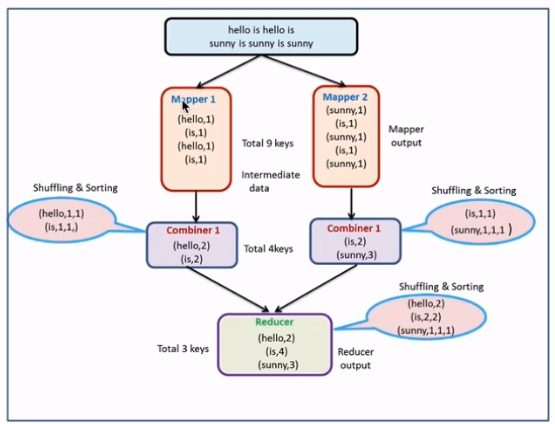
使用场景:求和、求次数
代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* 使用MapReduce开发WordCount的应用程序
*/
public class CombinerApp { /**
* Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
//按照指定分隔符进行拆分
String[] words = line.split(" ");
for(String word : words){
// 通过上下文把map的处理结果输出
context.write(new Text(word),one);
}
} } /**
* 归并操作
*/
public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for(LongWritable value : values){
//求key出现的次数和
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
} /**
* 定义Driver:封装lMapReduce作业的所有信息
* @param args
*/
public static void main(String[] args) throws Exception{ //创建configuration
Configuration configuration = new Configuration();
//准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
System.out.println("out file exists,but is has deleted!");
}
//创建job
Job job = Job.getInstance(configuration,"WordCount");
//设置job的处理类
job.setJarByClass(CombinerApp.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
//设置map相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce相关参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//通过job的设置combiner处理类,其实逻辑上和我们的reduce是一模一样的
job.setCombinerClass(MyReduce.class);
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job , new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 执行命令
hadoop jar hadoop-train-1.0-SNAPSHOT.jar WordCountApp /hdfsapi/test/b.txt /hdfsapi/test/out
MapReduce编程之Partitioner
partitioner决定MapTask输出的数据交由哪个ReduceTask处理
默认实现:分发的key的hash值对ReduceTask个数取模
partitioner案例开发
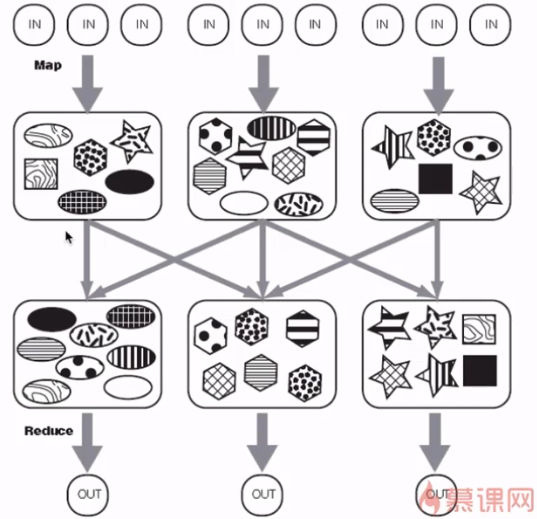
- 代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* 使用MapReduce开发WordCount的应用程序
*/
public class PartitionerApp { /**
* Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
//按照指定分隔符进行拆分
String[] words = line.split(" ");
context.write(new Text(words[0]),new LongWritable(Long.parseLong(words[1])));
}
} /**
* 归并操作
*/
public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for(LongWritable value : values){
//求key出现的次数和
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
} public static class MyPartitioner extends Partitioner<Text,LongWritable>{
@Override
public int getPartition(Text key, LongWritable longWritable, int i) {
if(key.toString().equals("xiaomi")){
return 0;
}
if(key.toString().equals("huawei")){
return 1;
}
if(key.toString().equals("iphone")){
return 2;
}
return 3;
}
}
/**
* 定义Driver:封装lMapReduce作业的所有信息
* @param args
*/
public static void main(String[] args) throws Exception{ //创建configuration
Configuration configuration = new Configuration();
//准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
System.out.println("out file exists,but is has deleted!");
}
//创建job
Job job = Job.getInstance(configuration,"WordCount");
//设置job的处理类
job.setJarByClass(PartitionerApp.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
//设置map相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce相关参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//通过job的设置partition
job.setPartitionerClass(MyPartitioner.class);
//设置4个reduce,每个分区一个
job.setNumReduceTasks(4);
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job , new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 执行命令
hadoop jar hadoop-train-1.0-SNAPSHOT.jar PartitionerApp /hdfsapi/test/partitioner /hdfsapi/test/outpartitioner
MapReduce编程之wordcount的更多相关文章
- mapReduce编程之auto complete
1 n-gram模型与auto complete n-gram模型是假设文本中一个词出现的概率只与它前面的N-1个词相关.auto complete的原理就是,根据用户输入的词,将后续出现概率较大的词 ...
- mapReduce编程之Recommender System
1 协同过滤算法 协同过滤算法是现在推荐系统的一种常用算法.分为user-CF和item-CF. 本文的电影推荐系统使用的是item-CF,主要是由于用户数远远大于电影数,构建矩阵的代价更小:另外,电 ...
- mapReduce编程之google pageRank
1 pagerank算法介绍 1.1 pagerank的假设 数量假设:每个网页都会给它的链接网页投票,假设这个网页有n个链接,则该网页给每个链接平分投1/n票. 质量假设:一个网页的pagerank ...
- MapReduce编程之Reduce Join多种应用场景与使用
在关系型数据库中 Join 是非常常见的操作,各种优化手段已经到了极致.在海量数据的环境下,不可避免的也会碰到这种类型的需求, 例如在数据分析时需要连接从不同的数据源中获取到数据.不同于传统的单机模式 ...
- MapReduce编程之Semi Join多种应用场景与使用
Map Join 实现方式一 ● 使用场景:一个大表(整张表内存放不下,但表中的key内存放得下),一个超大表 ● 实现方式:分布式缓存 ● 用法: SemiJoin就是所谓的半连接,其实仔细一看就是 ...
- MapReduce编程之Map Join多种应用场景与使用
Map Join 实现方式一:分布式缓存 ● 使用场景:一张表十分小.一张表很大. ● 用法: 在提交作业的时候先将小表文件放到该作业的DistributedCache中,然后从DistributeC ...
- Hadoop基础-Map端链式编程之MapReduce统计TopN示例
Hadoop基础-Map端链式编程之MapReduce统计TopN示例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.项目需求 对“temp.txt”中的数据进行分析,统计出各 ...
- 网络编程之socket
网络编程之socket socket:在网络编程中的一个基本组件,也称套接字. 一个套接字就是socket模块中的socket类的一个实例. 套接字包括两个: 服务器套接字和客户机套接字 套接字的实例 ...
- C++混合编程之idlcpp教程Python篇(9)
上一篇在这 C++混合编程之idlcpp教程Python篇(8) 第一篇在这 C++混合编程之idlcpp教程(一) 与前面的工程相比,工程PythonTutorial7中除了四个文件PythonTu ...
随机推荐
- python中的迭代器 生成器 装饰器
什么迭代器呢?它是一个带状态的对象,他能在你调用next()方法的时候返回容器中的下一个值,任何实现了__iter__和__next__()(python2中实现next())方法的对象都是迭代器,_ ...
- BZOJ1001或洛谷4001 [BJOI2006]狼抓兔子
BZOJ原题链接 洛谷原题链接 显然就是求最小割. 而对于一个平面图有结论,最大流=最小割=对偶图最短路. 所以这题可用最大流或是转换为对偶图求最短路,这里我是用的对偶图. 虽然理论上按上界算,这题\ ...
- 利用gulp搭建less编译环境
什么是less? 一种 动态 样式 语言. LESS 将 CSS 赋予了动态语言的特性,如 变量, 继承, 运算, 函数. LESS 既可以在 客户端 上运行 (支持IE 6+, Webkit, ...
- vim窗口切换
参考资料: http://www.cnblogs.com/litifeng/p/8282479.html 当用vim写代码的时候,我喜欢一边看着头文件中结构的定义,一边编写实现的代码,这样就经常用到多 ...
- partition
一.背景 1.在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作.有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念. 2.分区表指的是在创建表 ...
- 企业类Web原型制作分享-Kraftwerk
这是一个设计师团队,将数码产品的创意发挥到极致.整个网站采用深黑色背景和图文搭配,网站有很多动画特效,均突出数码产品的质感.网站结合滚动区实现导航栏悬浮效果,用弹出面板实现点击弹出内容等交互效果. 本 ...
- 安装配置nfs
#yum -y install nfs-utils rpcbind #service rpcbind start#service nfs start #chkconfig --add rpcbind# ...
- CSS学习笔记:盒子模型
盒子模型(CSS basic box model):When laying out a document, the browser's rendering engine represents each ...
- ubuntu下使用fstab挂载硬盘时,属于root,如何把它改为属于一个用户的(如sgjm)
http://zhidao.baidu.com/link?url=xnakfVD16EtunTSt3wBm153DyqHnXN3FSPO1E_2SpVmM5bmEIwICLA0N6zN85_ioQ3f ...
- MySQL Server参数优化 - innodb_file_per_table(独立表空间)
1 简介 Innodb存储引擎可将所有数据存放于ibdata*的共享表空间,也可将每张表存放于独立的.ibd文件的独立表空间. 共享表空间以及独立表空间都是针对数据的存储方式而言的. ...