mapReduce编程之auto complete
1 n-gram模型与auto complete
n-gram模型是假设文本中一个词出现的概率只与它前面的N-1个词相关。auto complete的原理就是,根据用户输入的词,将后续出现概率较大的词组显示出来。因此我们可以基于n-gram模型来对用户的输入作预测。
我们的实现方法是:首先用mapreduce在offline对语料库中的数据进行n-gram建模,存到数据库中。然后用户在输入的时候向数据库中查询,获取之后出现的概率较大的词,通过前端php脚本刷新实时显示在界面上。如下所示:
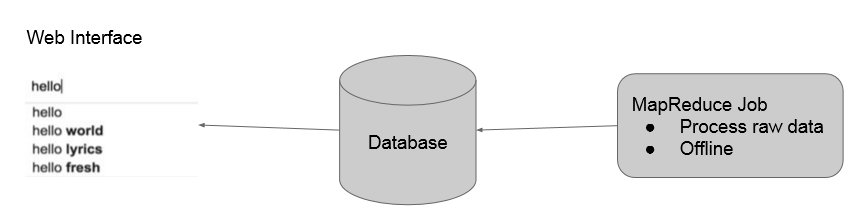
2 mapReduce流程
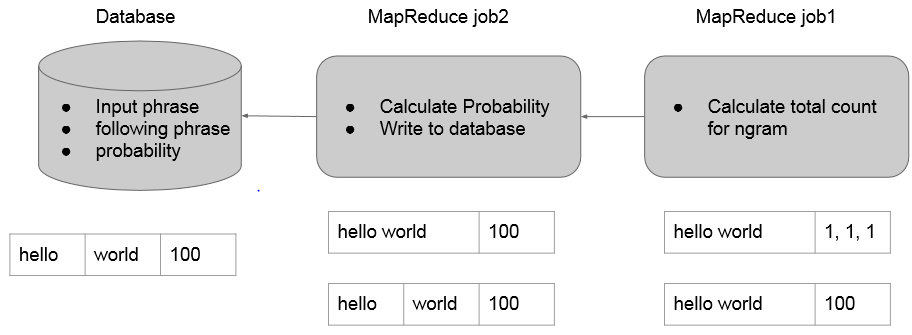
2.1 MR1
mapper负责按句读入语料库中的数据,分别作2~Ngram的切分(1-gram在这里没用),发送给reducer。
reducer则统计所有N-gram出现的次数。(这里就是一个wordcount)
2.2 MR2
mapper负责读入之前生成的N-gram及次数,将最后一个单词切分出来,以前面N-1个单词为key向reducer发送。
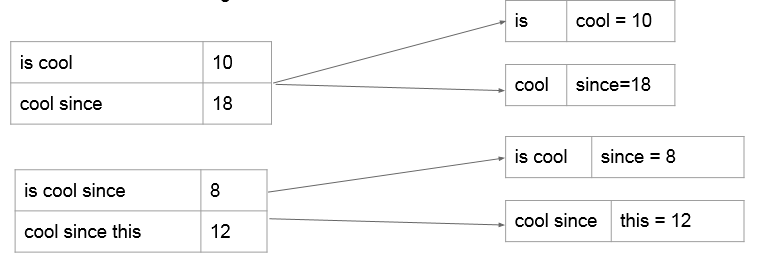
reducer里面得到的就是N-gram概率模型,即已知前N-1个词组成的phrase,最后一个词出现的所有可能及其概率。这里我们不用计算概率,仍然沿用词频能达到相同的效果,因为auto complete关注的是概率之间的相对大小而不是概率值本身。这里我们选择出现概率最大的topk个词来存入数据库,可以用treemap或者priorityQueue来做。

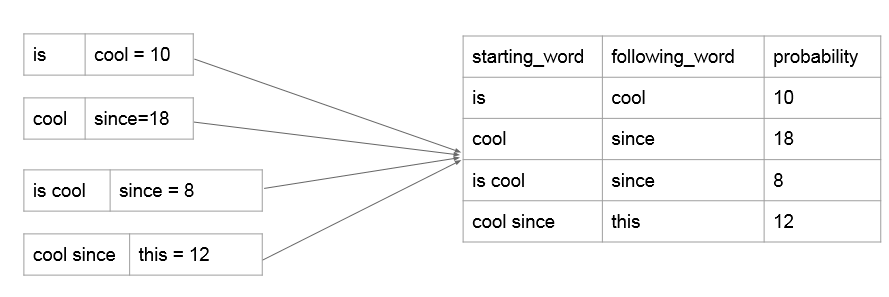
(注:这里的starting_word是1~n-1个词,following_word只能是一个词,因为这样才符合我们N-gram概率模型的意义。)
2.3 如何预测后面n个单词
数据库中的n-gram模型:

如上所述,我们看出使用n-gram模型只能与预测下一个单词。为了预测结果的多样性,如果我们要预测之后的n个单词怎么做?

使用sql语句,查询的时候查询匹配"input%"的所有starting_phrase,就可以实现。
3 代码
NGramLibraryBuilder.java
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class NGramLibraryBuilder {
public static class NGramMapper extends Mapper<LongWritable, Text, Text, IntWritable> { int noGram;
@Override
public void setup(Context context) {
Configuration conf = context.getConfiguration();
noGram = conf.getInt("noGram", 5);
} // map method
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); line = line.trim().toLowerCase();
line = line.replaceAll("[^a-z]", " "); String[] words = line.split("\\s+"); //split by ' ', '\t'...ect if(words.length<2) {
return;
} //I love big data
StringBuilder sb;
for(int i = 0; i < words.length-1; i++) {
sb = new StringBuilder();
sb.append(words[i]);
for(int j=1; i+j<words.length && j<noGram; j++) {
sb.append(" ");
sb.append(words[i+j]);
context.write(new Text(sb.toString().trim()), new IntWritable(1));
}
}
}
} public static class NGramReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// reduce method
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for(IntWritable value: values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
} }
LanguageModel.java
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
import java.util.Set;
import java.util.TreeMap; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; public class LanguageModel {
public static class Map extends Mapper<LongWritable, Text, Text, Text> { int threashold;
// get the threashold parameter from the configuration
@Override
public void setup(Context context) {
Configuration conf = context.getConfiguration();
threashold = conf.getInt("threashold", 20);
} @Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if((value == null) || (value.toString().trim()).length() == 0) {
return;
}
//this is cool\t20
String line = value.toString().trim(); String[] wordsPlusCount = line.split("\t");
if(wordsPlusCount.length < 2) {
return;
} String[] words = wordsPlusCount[0].split("\\s+");
int count = Integer.valueOf(wordsPlusCount[1]); if(count < threashold) {
return;
} //this is --> cool = 20
StringBuilder sb = new StringBuilder();
for(int i = 0; i < words.length-1; i++) {
sb.append(words[i]).append(" ");
}
String outputKey = sb.toString().trim();
String outputValue = words[words.length - 1]; if(!((outputKey == null) || (outputKey.length() <1))) {
context.write(new Text(outputKey), new Text(outputValue + "=" + count));
}
}
} public static class Reduce extends Reducer<Text, Text, DBOutputWritable, NullWritable> { int n;
// get the n parameter from the configuration
@Override
public void setup(Context context) {
Configuration conf = context.getConfiguration();
n = conf.getInt("n", 5);
} @Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //this is, <girl = 50, boy = 60>
TreeMap<Integer, List<String>> tm = new TreeMap<Integer, List<String>>(Collections.reverseOrder());
for(Text val: values) {
String curValue = val.toString().trim();
String word = curValue.split("=")[0].trim();
int count = Integer.parseInt(curValue.split("=")[1].trim());
if(tm.containsKey(count)) {
tm.get(count).add(word);
}
else {
List<String> list = new ArrayList<String>();
list.add(word);
tm.put(count, list);
}
}
//<50, <girl, bird>> <60, <boy...>>
Iterator<Integer> iter = tm.keySet().iterator();
for(int j=0; iter.hasNext() && j<n; j++) {
int keyCount = iter.next();
List<String> words = tm.get(keyCount);
for(String curWord: words) {
context.write(new DBOutputWritable(key.toString(), curWord, keyCount),NullWritable.get());
j++;
}
}
}
}
}
DBOutputWritable.java
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException; import org.apache.hadoop.mapreduce.lib.db.DBWritable; public class DBOutputWritable implements DBWritable{ private String starting_phrase;
private String following_word;
private int count; public DBOutputWritable(String starting_prhase, String following_word, int count) {
this.starting_phrase = starting_prhase;
this.following_word = following_word;
this.count= count;
} public void readFields(ResultSet arg0) throws SQLException {
this.starting_phrase = arg0.getString(1);
this.following_word = arg0.getString(2);
this.count = arg0.getInt(3); } public void write(PreparedStatement arg0) throws SQLException {
arg0.setString(1, starting_phrase);
arg0.setString(2, following_word);
arg0.setInt(3, count); } }
Driver.java
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class Driver { public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {
//job1
Configuration conf1 = new Configuration();
conf1.set("textinputformat.record.delimiter", ".");
conf1.set("noGram", args[2]); Job job1 = Job.getInstance();
job1.setJobName("NGram");
job1.setJarByClass(Driver.class); job1.setMapperClass(NGramLibraryBuilder.NGramMapper.class);
job1.setReducerClass(NGramLibraryBuilder.NGramReducer.class); job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(IntWritable.class); job1.setInputFormatClass(TextInputFormat.class);
job1.setOutputFormatClass(TextOutputFormat.class); TextInputFormat.setInputPaths(job1, new Path(args[0]));
TextOutputFormat.setOutputPath(job1, new Path(args[1]));
job1.waitForCompletion(true); //how to connect two jobs?
// last output is second input //2nd job
Configuration conf2 = new Configuration();
conf2.set("threashold", args[3]);
conf2.set("n", args[4]); DBConfiguration.configureDB(conf2,
"com.mysql.jdbc.Driver",
"jdbc:mysql://ip_address:port/test",
"root",
"password"); Job job2 = Job.getInstance(conf2);
job2.setJobName("Model");
job2.setJarByClass(Driver.class); job2.addArchiveToClassPath(new Path("path_to_ur_connector"));
job2.setMapOutputKeyClass(Text.class);
job2.setMapOutputValueClass(Text.class);
job2.setOutputKeyClass(DBOutputWritable.class);
job2.setOutputValueClass(NullWritable.class); job2.setMapperClass(LanguageModel.Map.class);
job2.setReducerClass(LanguageModel.Reduce.class); job2.setInputFormatClass(TextInputFormat.class);
job2.setOutputFormatClass(DBOutputFormat.class); DBOutputFormat.setOutput(job2, "output",
new String[] {"starting_phrase", "following_word", "count"}); TextInputFormat.setInputPaths(job2, args[1]);
job2.waitForCompletion(true);
} }
mapReduce编程之auto complete的更多相关文章
- MapReduce编程之wordcount
实践 MapReduce编程之wordcount import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Fi ...
- mapReduce编程之Recommender System
1 协同过滤算法 协同过滤算法是现在推荐系统的一种常用算法.分为user-CF和item-CF. 本文的电影推荐系统使用的是item-CF,主要是由于用户数远远大于电影数,构建矩阵的代价更小:另外,电 ...
- mapReduce编程之google pageRank
1 pagerank算法介绍 1.1 pagerank的假设 数量假设:每个网页都会给它的链接网页投票,假设这个网页有n个链接,则该网页给每个链接平分投1/n票. 质量假设:一个网页的pagerank ...
- MapReduce编程之Reduce Join多种应用场景与使用
在关系型数据库中 Join 是非常常见的操作,各种优化手段已经到了极致.在海量数据的环境下,不可避免的也会碰到这种类型的需求, 例如在数据分析时需要连接从不同的数据源中获取到数据.不同于传统的单机模式 ...
- MapReduce编程之Semi Join多种应用场景与使用
Map Join 实现方式一 ● 使用场景:一个大表(整张表内存放不下,但表中的key内存放得下),一个超大表 ● 实现方式:分布式缓存 ● 用法: SemiJoin就是所谓的半连接,其实仔细一看就是 ...
- MapReduce编程之Map Join多种应用场景与使用
Map Join 实现方式一:分布式缓存 ● 使用场景:一张表十分小.一张表很大. ● 用法: 在提交作业的时候先将小表文件放到该作业的DistributedCache中,然后从DistributeC ...
- Hadoop基础-Map端链式编程之MapReduce统计TopN示例
Hadoop基础-Map端链式编程之MapReduce统计TopN示例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.项目需求 对“temp.txt”中的数据进行分析,统计出各 ...
- C++混合编程之idlcpp教程Python篇(6)
上一篇在这 C++混合编程之idlcpp教程Python篇(5) 第一篇在这 C++混合编程之idlcpp教程(一) 工程PythonTutorial4中加入了四个文件:PythonTutorial4 ...
- C++混合编程之idlcpp教程Lua篇(6)
上一篇在这 C++混合编程之idlcpp教程Lua篇(5) 第一篇在这 C++混合编程之idlcpp教程(一) 工程LuaTutorial4中加入了四个文件:LuaTutorial4.cpp, Tut ...
随机推荐
- 人民币符号在html的显示方法
之前做页面的时候碰到一个问题——人民币符号 (¥) 的显示问题,IE6下特别明显. font-size:12px;的时候显示没有问题,但是一旦大于12px就会显示异常. 于是上网查了一下看有什么方法不 ...
- 只需2分钟,简单构建velocity web项目
Velocity是一个基于java的模板引擎(template engine).它允许任何人仅仅简单的使用模板语言(template language)来引用由java代码定义的对象 velocity ...
- iOS面试
1.进程.线程的区别?2.“三次握手”是什么?具体细节,连接释放时需要几次“握手”,说出大概过程.3.TCP.UDP协议的区别?计算机网络分几层,以及TCP.Http协议各自工作在哪一层及相关细节.4 ...
- 让Web API支持Protocol Buffers
简介 现在我们Web API项目基本上都是使用的Json作为通信的格式,随着移动互联网的兴起,Web API不仅其他系统可以使用,手机端也可以使用,但是手机端也有相对特殊的地方,网络通信除了wifi, ...
- 梦想成真,喜获微软MVP奖项,微软MVP FAQ?
之前一直很钦佩那些MVP获奖者,想着自己有一天也能拿到该多好,就在10月1日邮箱收到了微软的邮件,当选了2016年10月份的MVP.今天主要分享一下获奖的喜悦也分享一下如何获得MVP奖项. 什么是微软 ...
- 随便写一下看下效果。一个js问题
(function(a){ console.log(a); var a = 10; function a(){} }(100)); 问:执行这段代码会输出什么.
- MFC的多线程操作
记得用MFC做了一个图像自动修复软件,当时没有多线程操作这一概念,由于图像修复算法比较复杂,因此,当执行图像修复时,程序就像卡死了似得而不能做其他操作.其实MFC对这种情况有一种很好地解决方案,那就是 ...
- bzoj3731: Gty的超级妹子树
一代神题啊orz(至少是以前年代的神题吧) 块状树 复杂度nsqrtnlogn 真是exciting 还没有卡时限 话不多说直接上代码 (最近解锁了记事本写代码的技能...感觉越来越依赖OJ调试了.. ...
- 打电话,发短信,发邮件,app跳转
1.打电话 - (IBAction)callPhone1:(id)sender { NSURL *url = [NSURL URLWithString:@"tel://18500441739 ...
- DropDownList控件
1.DropDownList控件 <asp:DropDownList runat="server" ID="DropDownList1" AutoPost ...