Flink Task 并行度
并行的数据流
Flink程序由多个任务(转换/运算符,数据源和接收器)组成,Flink中的程序本质上是并行和分布式的。
在执行期间,流具有一个或多个流分区,并且每个operator具有一个或多个operator*子任务*。
operator子任务彼此独立,并且可以在不同的线程中执行,这些线程又可能在不同的机器或容器上执行。
operator子任务的数量是该特定operator的并行度。
流的并行度始终是其生成operator的并行度。
同一程序的不同operator可能具有不同的并行级别。
示意图:
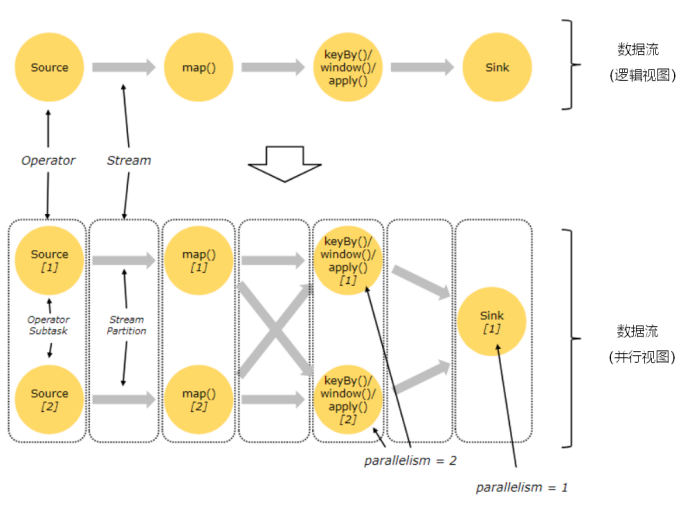
流可以以一对一(或重新分配)模式或以重新分发模式在两个运营商之间传输数据:
- 一对一流
- 如上图中的Source和map运算符之间
- 保留元素的分区和排序
- 这意味着map运算符的subtask [1] 将看到与Source运算符的subtask [1]生成的顺序相同的元素
- 重新分配流
- 在上面的map和keyBy / window之间,以及 keyBy / window和Sink之间重新分配流
- 每个运算符子任务将数据发送到不同的目标子任务, 具体取决于所选的转换。
- 图中是根据 keyby算子进行数据的重新分布。
- 一对一流
任务并行度设置
算子级别
可以通过调用其setParallelism()方法来定义单个运算符,数据源或数据接收器的并行度。
//1.初始化环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取数据源,并进行转换操作
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("ronnie01", 9999)
.flatMap(new Splitter())
.keyBy(0)
//每5秒触发一批计算
.timeWindow(Time.seconds(5))
// 设置并行度
.sum(1).setParallelism(3);
执行环境级别
执行环境级别的并行度是本次任务中所有的操作符,数据源和数据接收器的并行度。
可以通过显式的配置运算符并行度来覆盖执行环境并行度。
//1.初始化环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(3);
客户端级别
- 在向Flink提交作业时,可以在客户端设置并行度,通过使用指定的parallelism参数-p。
- 例如:
- ./bin/flink run -p 10 ../examples/WordCount-java.jar
系统级别
- 通过设置flink_home/conf/flink-conf.yaml 配置文件中的parallelism.default配置项来定义默认并行度。
Flink Task 并行度的更多相关文章
- Flink task之间的数据交换
Flink中的数据交换是围绕着下面的原则设计的: 1.数据交换的控制流(即,为了启动交换而传递的消息)是由接收者发起的,就像原始的MapReduce一样. 2.用于数据交换的数据流,即通过电缆的实际数 ...
- flink solt,并行度
转自:https://www.jianshu.com/p/3598f23031e6 简介 Flink运行时主要角色有两个:JobManager和TaskManager,无论是standalone集群, ...
- spark内核篇-task数与并行度
每一个 spark job 根据 shuffle 划分 stage,每个 stage 形成一个或者多个 taskSet,了解了每个 stage 需要运行多少个 task,有助于我们优化 spark 运 ...
- Flink并行度
并行执行 本节介绍如何在Flink中配置程序的并行执行.FLink程序由多个任务(转换/操作符.数据源和sinks)组成.任务被分成多个并行实例来执行,每个并行实例处理任务的输入数据的子集.任务的并行 ...
- 追源索骥:透过源码看懂Flink核心框架的执行流程
li,ol.inline>li{display:inline-block;padding-right:5px;padding-left:5px}dl{margin-bottom:20px}dt, ...
- Flink 靠什么征服饿了么工程师?
Flink 靠什么征服饿了么工程师? 2018-08-13 易伟平 阿里妹导读:本文将为大家展示饿了么大数据平台在实时计算方面所做的工作,以及计算引擎的演变之路,你可以借此了解Storm.Spa ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-split & select(拆分流)
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink on YARN时,如何确定TaskManager数
转自: https://www.jianshu.com/p/5b670d524fa5 答案写在最前面:Job的最大并行度除以每个TaskManager分配的任务槽数. 问题 在Flink 1.5 Re ...
随机推荐
- OOP的四大特征
抽象 abstract 最近对抽象有些不熟悉,那么先谈谈抽象. 抽象在java中常常表现为抽象类和抽象方法,即被abstract关键字修饰的类和方法. 抽象类:被abstract修饰的类 1 和接口不 ...
- 第1节 kafka消息队列:1、kafka基本介绍以及与传统消息队列的对比
1. Kafka介绍 l Apache Kafka是一个开源消息系统,由Scala写成.是由Apache软件基金会开发的一个开源消息系统项目. l Kafka最初是由LinkedIn开发,并于20 ...
- Mac安装jdk
jdk:https://blog.csdn.net/zw235345721/article/details/78702254 mysql:https://www.jianshu.com/p/fd3aa ...
- 33 第一个只出现一次的字符+ASCII码
题目描述 在一个字符串(1<=字符串长度<=10000,全部由字母组成)中找到第一个只出现一次的字符,并返回它的位置 思路:使用一个hashmap遍历一遍,统计每个字符出现的次数,然后再统 ...
- CH8 IO库
8.1 #include <iostream> #include <string> #include <sstream> #include <fstream& ...
- Android程序的入口点是什么,不是Main()吗
很多初入Android开发的网页可能不知道Android程序的入口点是什么,不是main()吗,当然我相信回复onCreate的在字面上不算错,但是你们想的是Activity中的onCreate 方法 ...
- 认识python中的super函数
需求分析 在类继承中,存在这么一种情况: class Human(object): def Move(self): print("我会走路...") class Man(Human ...
- 使用nginx做反向代理来访问tomcat服务器
本次记录的是使用nginx来做一个反向代理来访问tomcat服务器.简单的来说就是使用nginx做为一个中间件,来分发客户端的请求,将这些请求分发到对应的合适的服务器上来完成请求及响应. 第一步:安装 ...
- 【WPF学习】第二十二章 文本控件
WPF提供了三个用于输入文本的控件:TextBox.RichTextBox和PasswordBox.PasswordBox控件直接继承自Control类.TextBox和RichTextBox控件间接 ...
- Python 3.8 新功能【新手必学】
Python 3.8 是 Python 编程语言的最新主要版本, 它包含许多新功能和优化. Python 3.8 Python 3.8 的一些新功能包括: 1. 海象运算符 PS:很多人 ...