手把手教你使用Python爬取西刺代理数据(下篇)
/1 前言/
前几天小编发布了手把手教你使用Python爬取西次代理数据(上篇),木有赶上车的小伙伴,可以戳进去看看。今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下。
/2 首页分析及提取/
首先进入网站主页,如下图所示。
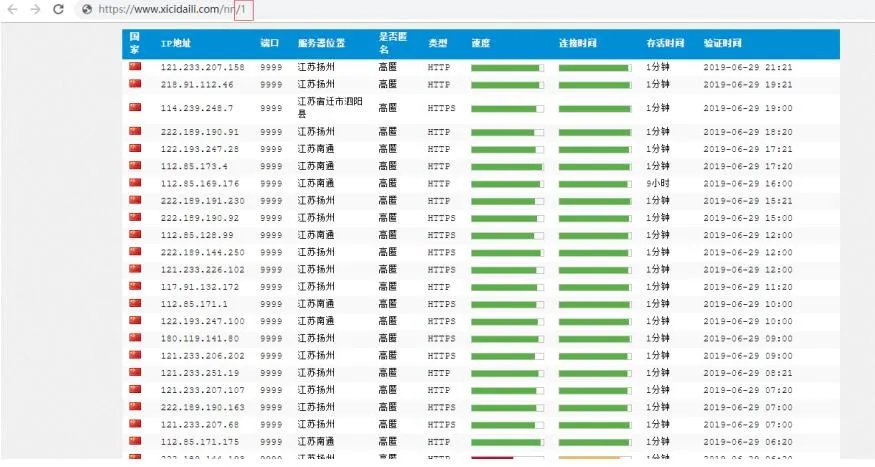
简单分析下页面,其中后面的 1 是页码的意思,分析后发现每一页有100 多条数据,然后网站底部总共有 2700+页 的链接,所以总共ip 代理加起来超过 27 万条数据,但是后面的数据大部分都是很多年前的数据了,比如 2012 年,大概就前 5000 多条是最近一个月的,所以决定爬取前面100 页。通 过网站 url 分析,可以知道这 100 页的 url 为:

规律显而易见,在程序中,我们使用一个 for 循环即可完整这个操作:

其中 scrapy 函数是爬取的主要逻辑,对应的代码为:
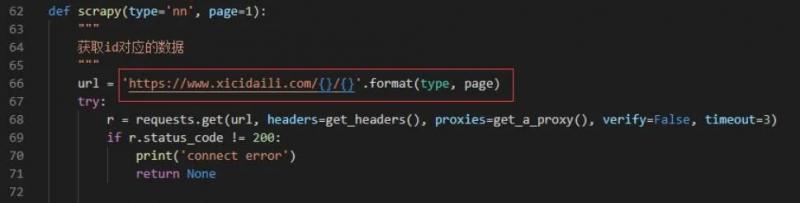
通过这个方式,我们可以得到每一页的数据。
/3 网页元素分析及提取/
接下来就是对页面内的元素进行分析,提取其中的代理信息。
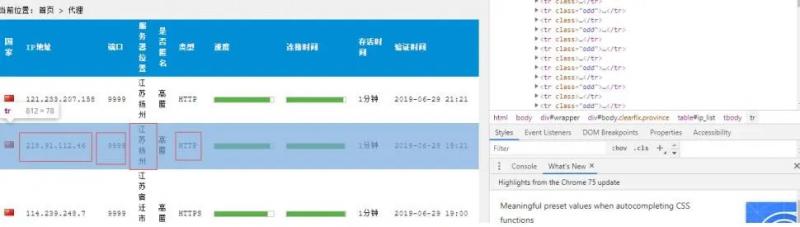
如上图,我们目的是进行代理地域分布分析,同时,在爬取过程中需要使用爬取的数据进行代 理更新,所以需要以下几个字段的信息:
Ip 地址、端口、服务器位置、类型
为此,先构建一个类,用于保存这些信息:
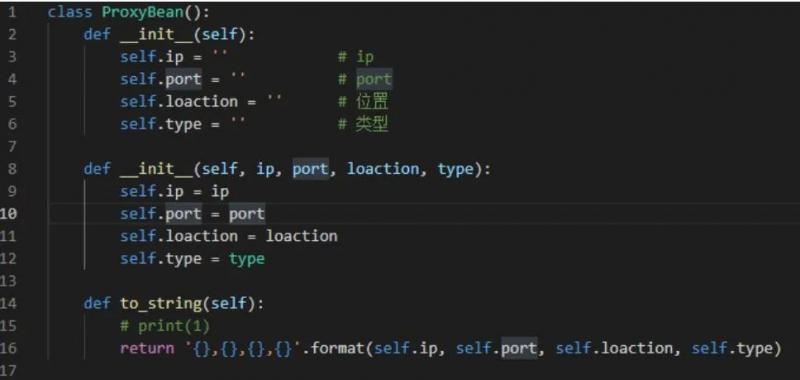
这样,每爬取一条信息,只要实例化一个 ProxyBean 类即可,非常方便。
接下来就是提取元素过程了,在这个过程我使用了正则表达式和 BeautifulSoup 库进行关键数据提取。
首先,通过分析网页发现,所有的条目实际上都是放在一个
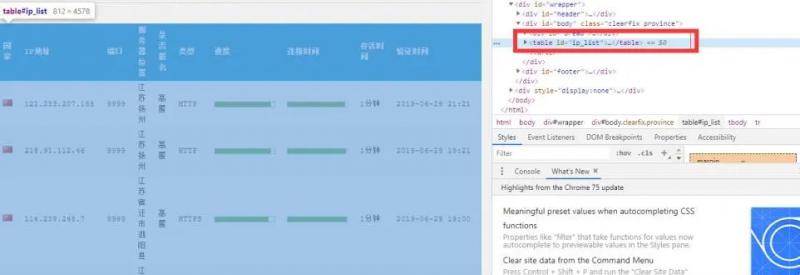
我们首先通过正则表达式将该标签的内容提取出来:
正则表达式为:
, 表示搜索
之 间的任意字符组成的数据。Python 中的实现如下:

其中得到的 data 就是这个标签的内容了。下面进一步分析。
进入到 table 中,发现每一个代理分别站 table 的一列
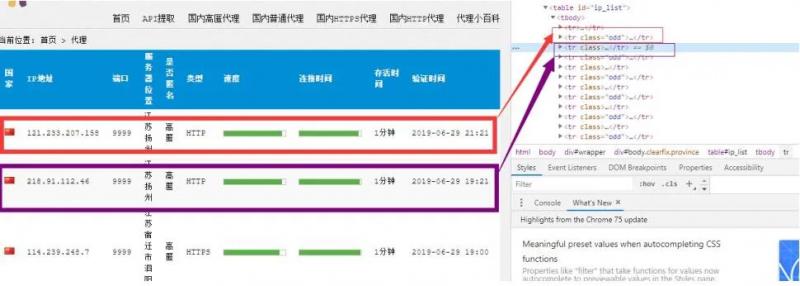
这个时候,可以使用 BeautifulSoup 对标签进行提取:
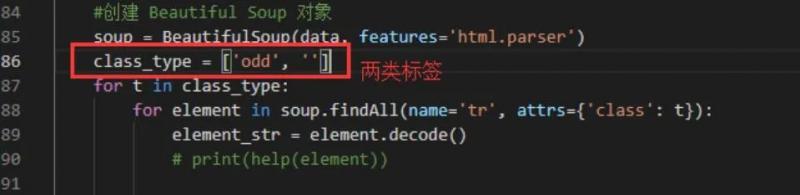
通过这种方式,就能获取到每一个列的列表了。
接下来就是从每个列中获取 ip、端口、位置、类型等信息了。进一步分析页面:
1、IP 字段:
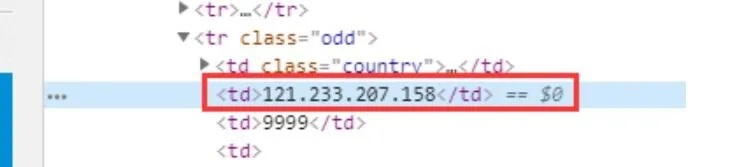
我们使用正则表达式对 IP 进行解析,IP 正则如下:
** (2[0-5]{2}|[0-1]?\d{1,2})(.(2[0-5]{2}|[0-1]?\d{1,2})){3}**

2、 端口字段
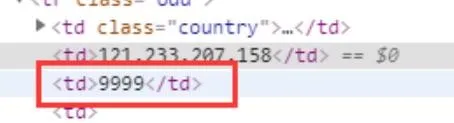
端口由
包裹,并且中间全部是数字,故可构造如下正则进行提取:
<td>([0-9]+)</td>

3、 位置字段
位置字段如下:
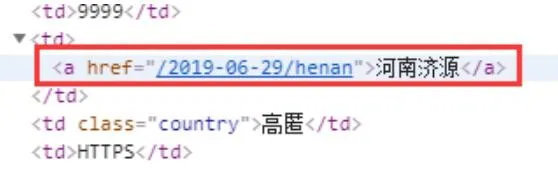
由 便签包裹,构造如下正则即可提取:
<a href="([>]*)>([<]*)

4、类型字段
类型字段如下:
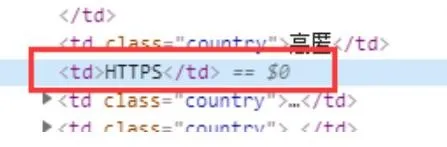
由

数据全部获取完之后,将其保存到文件中即可:
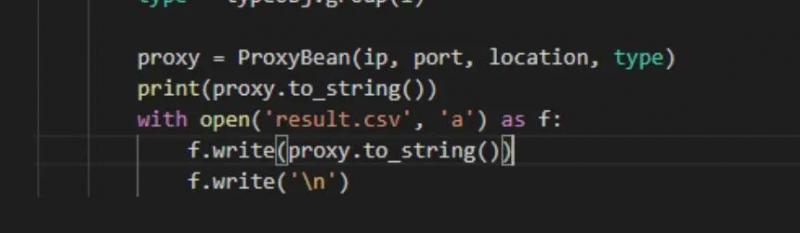
最后爬取的数据集如下图所示:
此次总共爬取了前面 5300 多条数据。
/4 小结/
本次任务主要爬取了代理网站上的代理数据。主要做了以下方面的工作:
1、学习 requests 库的使用以及爬虫程序的编写;
2、学习使用反爬虫技术手段,并在实际应用中应用这些技术,如代理池技术;
3、学习使用正则表达式,并通过正则表达式进行网页元素提取;
4、学习使用 beautifulsoup 库,并使用该库进行网页元素的提取。
Python爬虫是一项综合技能,在爬取网站的过程中能够学到很多知识,希望大家多多专研,需要代码的小伙伴,可以在[Python爬虫与数据挖掘]公众号后台回复“代理”二字,即可获取。
想学习更多关于Python的知识,可以参考Python爬虫与数据挖掘网站:http://pdcfighting.com/
本文由博客群发一文多发等运营工具平台 OpenWrite 发布
手把手教你使用Python爬取西刺代理数据(下篇)的更多相关文章
- 使用XPath爬取西刺代理
因为在Scrapy的使用过程中,提取页面信息使用XPath比较方便,遂成此文. 在b站上看了介绍XPath的:https://www.bilibili.com/video/av30320885?fro ...
- Python四线程爬取西刺代理
import requests from bs4 import BeautifulSoup import lxml import telnetlib #验证代理的可用性 import pymysql. ...
- Scrapy爬取西刺代理ip流程
西刺代理爬虫 1. 新建项目和爬虫 scrapy startproject daili_ips ...... cd daili_ips/ #爬虫名称和domains scrapy genspider ...
- python scrapy 爬取西刺代理ip(一基础篇)(ubuntu环境下) -赖大大
第一步:环境搭建 1.python2 或 python3 2.用pip安装下载scrapy框架 具体就自行百度了,主要内容不是在这. 第二步:创建scrapy(简单介绍) 1.Creating a p ...
- python+scrapy 爬取西刺代理ip(一)
转自:https://www.cnblogs.com/lyc642983907/p/10739577.html 第一步:环境搭建 1.python2 或 python3 2.用pip安装下载scrap ...
- python3爬虫-通过requests爬取西刺代理
import requests from fake_useragent import UserAgent from lxml import etree from urllib.parse import ...
- python爬取高匿代理IP(再也不用担心会进小黑屋了)
为什么要用代理IP 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人 ...
- 爬取西刺ip代理池
好久没更新博客啦~,今天来更新一篇利用爬虫爬取西刺的代理池的小代码 先说下需求,我们都是用python写一段小代码去爬取自己所需要的信息,这是可取的,但是,有一些网站呢,对我们的网络爬虫做了一些限制, ...
- 爬取西刺网的免费IP
在写爬虫时,经常需要切换IP,所以很有必要自已在数据维护库中维护一个IP池,这样,就可以在需用的时候随机切换IP,我的方法是爬取西刺网的免费IP,存入数据库中,然后在scrapy 工程中加入tools ...
随机推荐
- .NET 5 中的正则引擎性能改进(翻译)
前言 System.Text.RegularExpressions 命名空间已经在 .NET 中使用了多年,一直追溯到 .NET Framework 1.1.它在 .NET 实施本身的数百个位置中使用 ...
- vue-父组件传递参数到子组件
案例: 父组件 <template> <div id="app"> <h1>vuex</h1> <h3>count:{{ ...
- 关于《自动化测试实战宝典:Robot Framework + Python从小工到专家》
受新冠疫情影响,笔者被“困”在湖北老家七十余天,于4月1号(愚人节)这天,终于返回到广州.当前国内疫情基本已趋于平稳,但全球疫情整体势态仍在持续疯涨,累计确诊病例已近80万人.祈祷这场全球性灾难能尽早 ...
- J. Justifying the Conjecture(规律——整数拆分)
题目链接 五校友谊赛终于开始了,话不多说A题吧. 从前从前有一个正整数n,你需要找到一个素数x和一个合数y使x+y=n成立,这样就可以双剑合并了. 素数是一个大于1的自然数,它的因数只有1与它自己本身 ...
- Java 中的递归
递归 递归 一种通过调用某个方法来描述需要重复进行的操作.该方法的特点就是可以自己调用自己. 案例一 排队的问题 在生活中,我们经常需要排队.在排队中,我们怎么才能知道自己所排在第几位呢? 我们也许会 ...
- Nginx知多少系列之(三)配置文件详解
目录 1.前言 2.安装 3.配置文件详解 4.Linux下托管.NET Core项目 5.Linux下.NET Core项目负载均衡 6.Linux下.NET Core项目Nginx+Keepali ...
- escape和unescape知识点
decodeURI() 函数可对 encodeURI() 函数编码过的 URI 进行解码. encodeURI() 函数可把字符串作为 URI 进行编码 <script> var uri= ...
- Java第四天,随机数如何生成?ArrayList如何使用?
虽然很多时候我们查阅Java API文档,但是对于一些必要的类,我们还是需要去了解的.因为这样的情况下,我们就可以尽量的去缩短开发的周期.接下来我们认识一下哪些API类是必须熟记的. Random 这 ...
- Idea离线安装plugins插件 如Lombok
由于公司不允许使用外网,之前用的idea 15 安装了一次.但是idea15的提示不够友好,今天升级idea2017.3.2,同样又需要安装,那就写个教程吧. 网上其他的安装教程不通用,也是针对不同i ...
- GO中的逃逸分析
1.什么是逃逸分析 以前写c/c++代码时,为了提高效率,常常将pass-by-value(传值)“升级”成pass-by-reference,企图避免构造函数的运行,并且直接返回一个指针. 那么这里 ...