CDH5部署三部曲之三:问题总结
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
系列文章链接
本文是《CDH5部署三部曲》的终篇,前面两章完成了CDH5集群的部署和启动,本章将实战中遇到的问题做个总结,如果碰巧您也遇到过这些问题,希望本文能给您一些参考;
启动集群服务报错
- 首次启动集群服务报错,如下图:
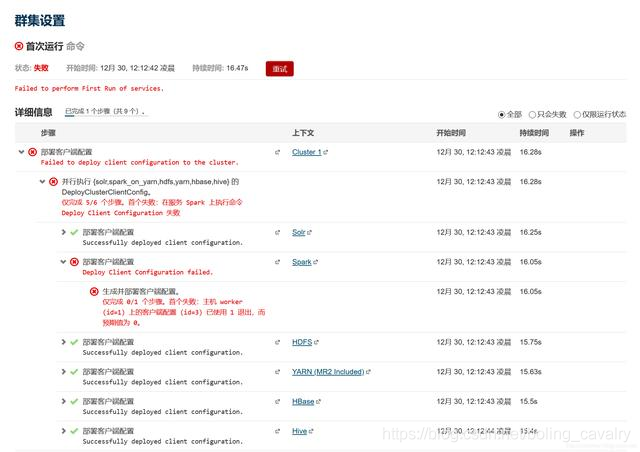
- 上述错误一般是对应节点的/usr/java/default目录下没有JDK所致,假设已将JDK部署在/usr/lib/jvm/jdk1.8.0_191,那么只需执行以下命令建立软链接即可:
mkdir /usr/java &&ln -s /usr/lib/jvm/jdk1.8.0_191 /usr/java/default
- 点击页面上的重试按钮;
NFS Gateway启动失败
- 发现NFS Gateway服务有问题,检查日志:
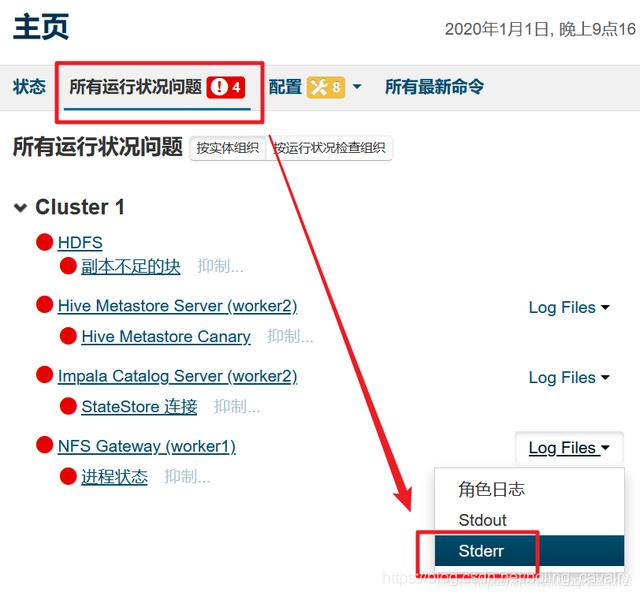
- 日志如下,在worker1节点上,portmap和rpcbind这两个服务不存在导致的:
No portmap or rpcbind service is running on this host. Please start portmap or rpcbind service before attempting to start the NFS Gateway role on this host.
- 于是安装所需服务:
yum install -y nfs-utils rpcbind
- 启动服务:
systemctl start rpcbind
- 再次启动:
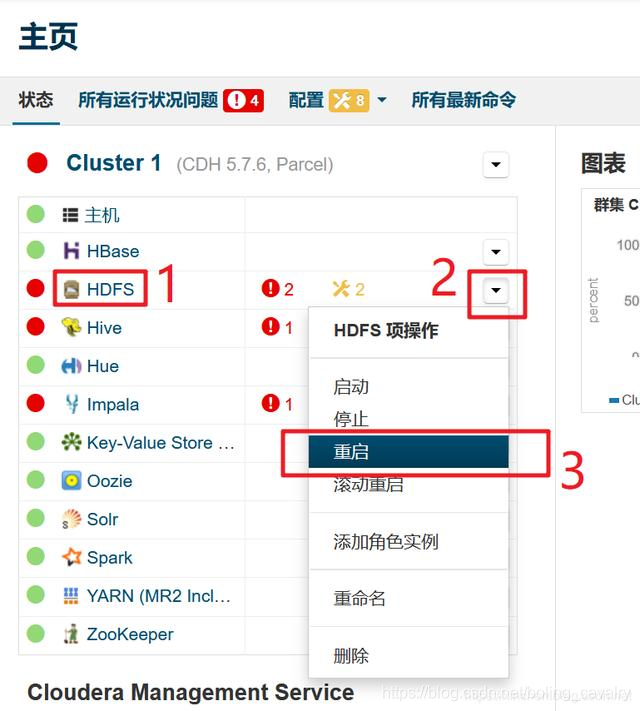
- 等待HDFS服务重启完成后,如下图,可见NFS Gateway问题已经消失:
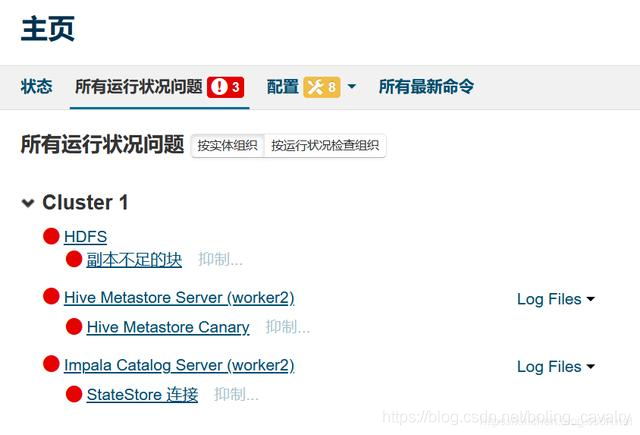
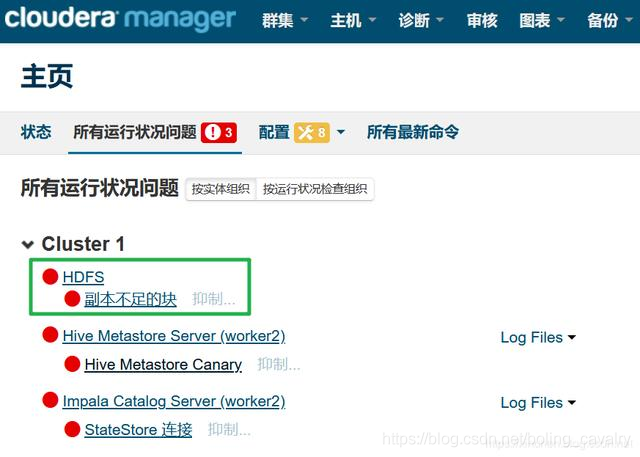
HDFS副本不足的块
- 问题如下图绿框所示:
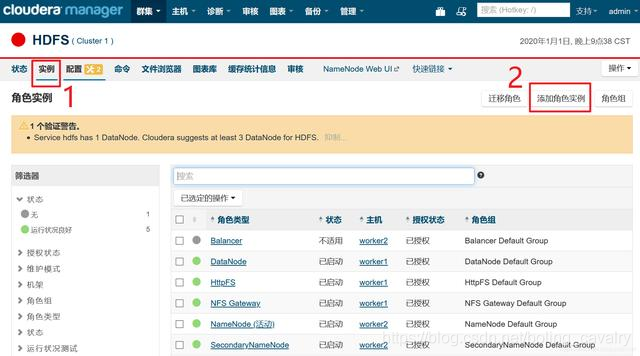
- 目前只有一个datanode,可以增加一个,如下图,进入HDFS的实例页面,点击"添加角色实例":
- 点击下图红框位置,增加一个DataNode:
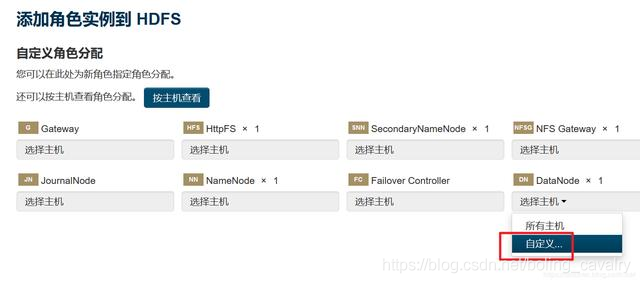
- 如下图,确保worker1和worker2都选上:

- 勾选后,点击红框2中的按钮,在下拉菜单中点击“启动”:
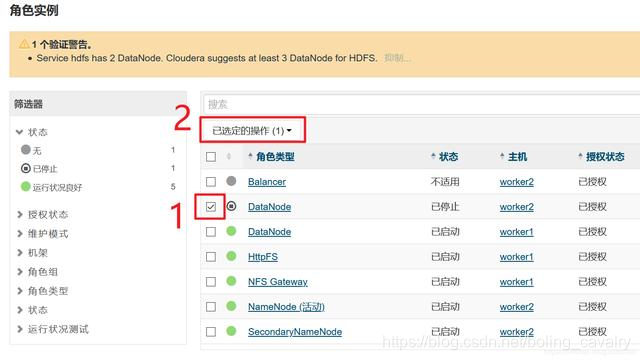
- 现在有了两个DataNode,所以副本数可以设置为2,如下图红框所示,按照顺序找出参数进行设置,记得点击右下角的"保存更改"按钮:
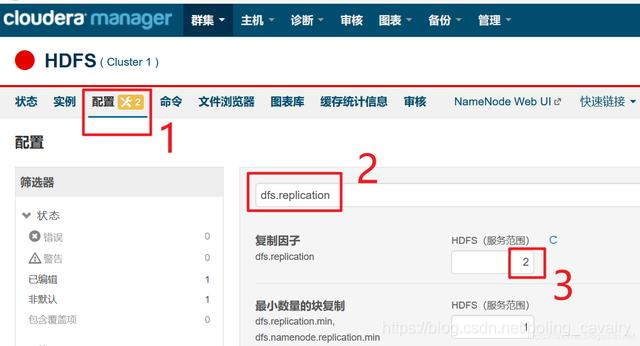
- 上述设置完成后,新写入hdfs的文件副本数为2,如果要将之前已经写入的文件的副本数也调整为2,请SSH登录worker1节点,执行以下命令切换到hdfs账号:
su - hdfs
- 以hdfs账号的身份执行以下命令,即可完成副本数设置:
hadoop fs -setrep -R 2 /
- 返回管理页面,可见HDFS的状态变成了健康:
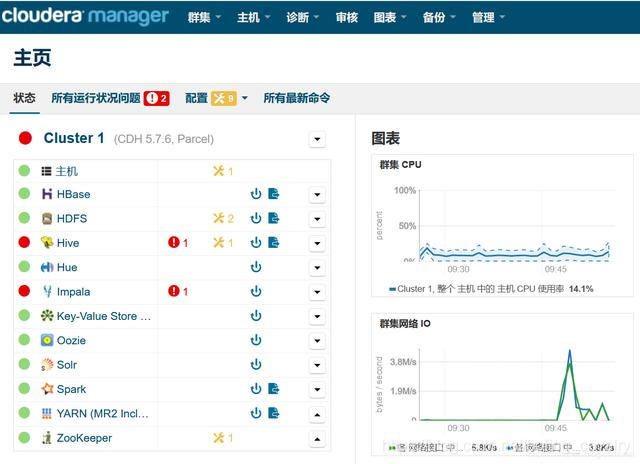
Hive报错
- 如下图红框所示,Hive启动失败,日志中提示Version information not found in metastore
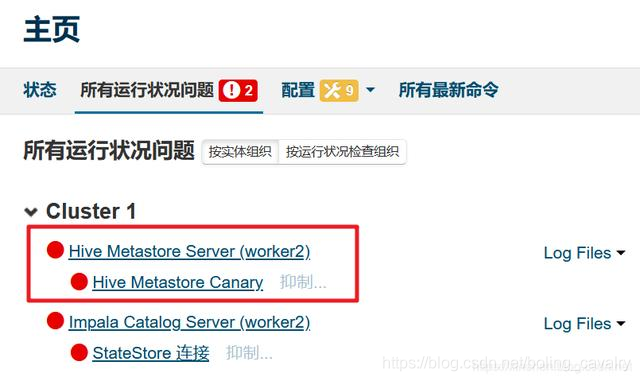
- 从上图可见Hive服务在worker2上,于是SSH登录worker2,将/usr/share/java目录下的mysql-connector-java.jar文件复制到这个目录下:/opt/cloudera/parcels/CDH-5.7.6-1.cdh5.7.6.p0.6/lib/hive/lib/
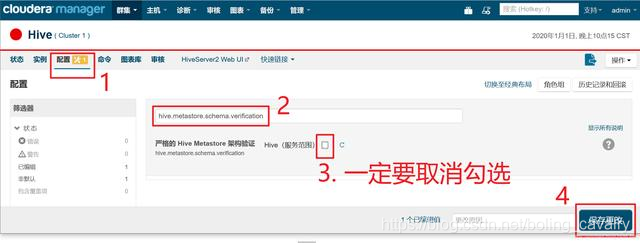
- 在Hive的配置页面,搜索"hive.metastore.schema.verification",如下图,确保红框3中的复选框取消勾选:
- 修改配置datanucleus.autoCreateSchema,如下图,确保红框3中的复选框被选中:
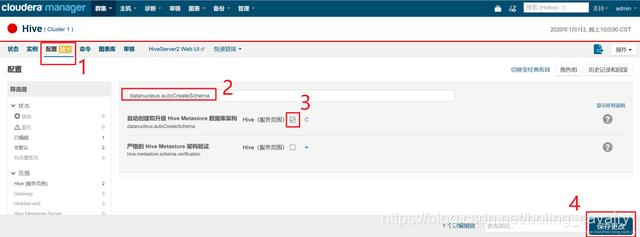
- 重启完成后,Hive状态为健康:
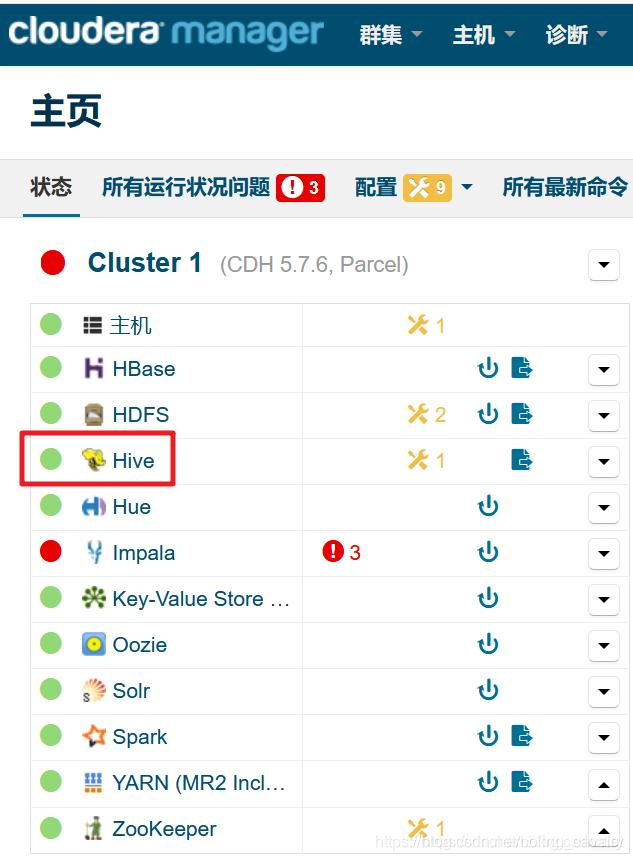
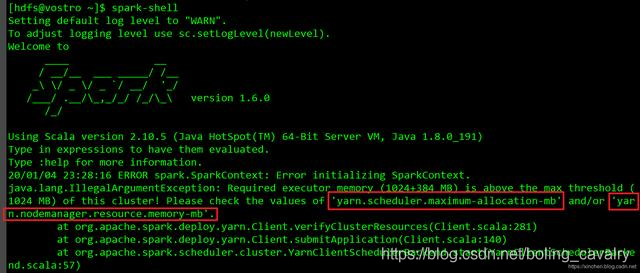
spark-shell执行失败
- 在worker1或者worker2上执行spark-shell命令进入spark控制台时,会产生内存相关的错误,需要调整YARM相关的内存参数:
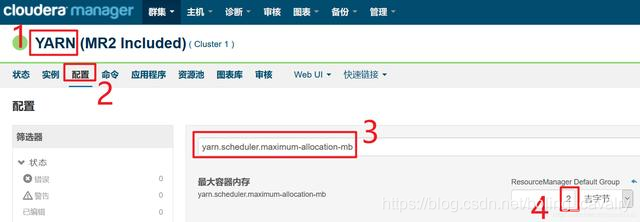
- 在YARN的配置页面,调整yarn.scheduler.maximum-allocation-mb和yarn.nodemanager.resource.memory-mb这两个参数的值,原有的值都是1G,现在都改成2G,如下图:
- 重启YARN;
- 重启Spark;
- 执行spark-shell命令之前,先执行命令su - hdfs切换到hdfs账号;
- 这次终于成功进入spark-shell交互模式:
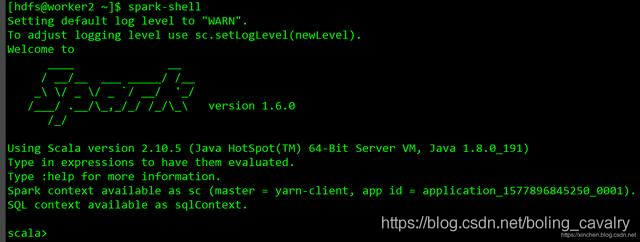
Hue启动失败
- Hue启动失败如下图:
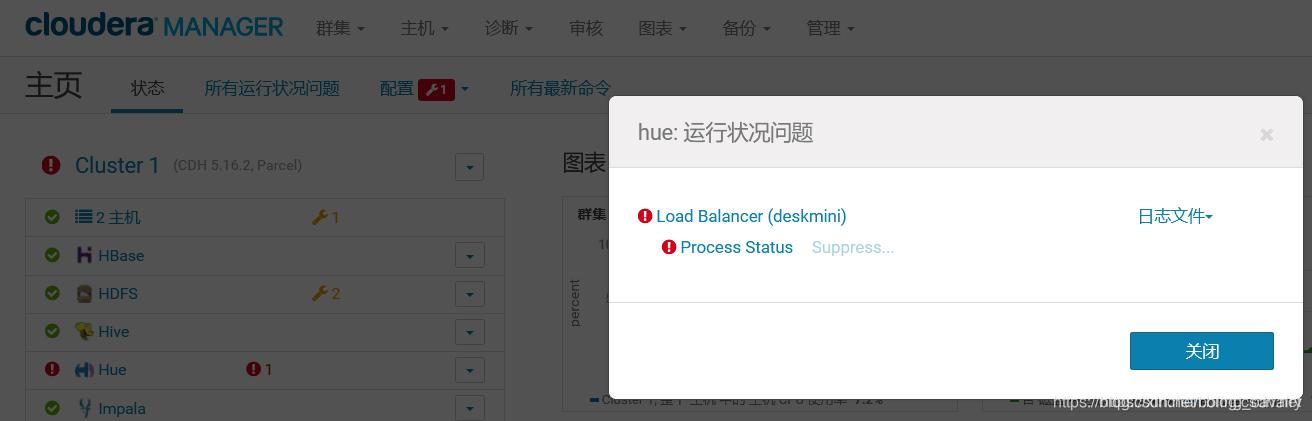
- 上述失败是由于文件夹、文件、httpd服务没有准备好导致的,执行以下命令修复此问题:
mkdir /var/log/hue-httpd/
chown hue:hue /var/log/hue-httpd/
cd /var/log/hue-httpd/
touch error_log
chown hue:hue /var/log/hue-httpd/error_log
yum install -y httpd mod_ssl cyrus-sasl-plain cyrus-sasl-devel cyrus-sasl-gssapi
- 在网页上重启Hue服务,稍后可见服务已经正常:
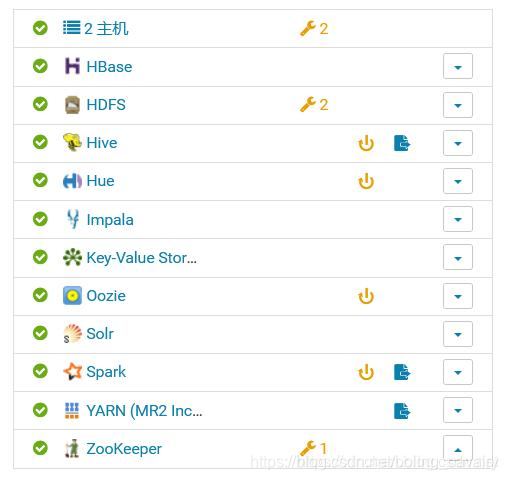
以上就是本次实战过程中遇到的所有问题和解决方法,至此《CDH5部署三部曲》全部完成,如果您正在部署CDH,希望此系列文章能给您一些参考。
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
CDH5部署三部曲之三:问题总结的更多相关文章
- CDH5部署三部曲之一:准备工作
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- CDH5部署三部曲之二:部署和设置
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Docker下实战zabbix三部曲之三:自定义监控项
通过上一章<Docker下实战zabbix三部曲之二:监控其他机器>的实战,我们了解了对机器的监控是通过在机器上安装zabbix agent来完成的,zabbix agent连接上zabb ...
- Flink on Yarn三部曲之三:提交Flink任务
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的DataSource三部曲之三:自定义
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- SQL Server 2008 数据库镜像部署实例之三 配置见证服务器
SQL Server 2008 数据库镜像部署实例之三 配置见证服务器 前面已经完成了镜像数据库的配置,并进行那个了故障转移测试.接下来将部署见证服务器,实现自动故障转移. 一.关于见证服务器 1.若 ...
- kubernetes下的Nginx加Tomcat三部曲之三:实战扩容和升级
本章是<kubernetes下的Nginx加Tomcat三部曲系列>的终篇,今天咱们一起在kubernetes环境对下图中tomcat的数量进行调整,再修改tomcat中web工程的源码, ...
- Docker搭建disconf环境,三部曲之三:细说搭建过程
Docker下的disconf实战全文链接 <Docker搭建disconf环境,三部曲之一:极速搭建disconf>: <Docker搭建disconf环境,三部曲之二:本地快速构 ...
- CoProcessFunction实战三部曲之三:定时器和侧输出
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- Leetcode 全排列专题(更新ing)
总览 涉及到的题目有 题号 名字 难度 Leetcode 60 第k个排列 中等 Leetcode 46 全排列 中等 待更新...... Leetcode 46 全排列 题目 基础题 给定一个 没有 ...
- 藏在Java数组的背后,你可能忽略的知识点
目录 引言 概念 区别于C/C++数组 区别于容器 数组特性 随机访问 Java数组与内存 解惑 数组的本质 Java中的数组是对象吗? Java中数组的类型 Java中数组的继承关系 参考资料 引言 ...
- 工具-Typora常用语法()+自己总结
工具-Typora常用语法 Markdown(MD)作为目前互联网写作相当流行的一种文档撰写语言格式,深受互联网编辑者的喜爱,由此周边一些基于MD的编辑工具也随之油然而生. 作为一款免费的MD编辑器: ...
- 论如何学习Extjs
可能现在学习Extjs相比于Vue,在网上的资料要少很多,不过一些旧的视频还是可以帮助你们了解到Extjs是怎么回事. 这里讲一下自己是如何开始学习Extjs语言的: 1.先从Ext的中文文档中学习怎 ...
- NX二次开发-NX访问MySQL数据库(增删改查)
版本:NX11+VS2013+MySQL5.6(x64)+SQLyog 1.新建一个NX项目(多字节) 2.设置VC++目录(调用MySQL的头文件,dll和lib库文件) 3.设置番茄助手 然后重启 ...
- Mac部署spark2.4.4
环境信息 操作系统:macOS Mojave 10.14.6 JDK:1.8.0_211 (安装位置:/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jd ...
- java基础整理总结篇(1)
>>java数据区域,大致分以下几种 寄存器:位于cpu内部,寄存器的数量有限,所以寄存器根据需求分配.不能直接控制它. 堆栈:位于通用RAM(随机访问存储器)中,通过堆栈指针可以从处理器 ...
- redis入门指南(七)—— 安全、协议、管理工具及命令属性
写在前面 学习<redis入门指南>笔记,结合实践,只记录重要,明确,属于新知的相关内容. 安全 1.可以使用bind参数绑定一个地址,使redis只接受这个地址的连接. 2.使用requ ...
- Java随谈(二)对空指针异常的碎碎念
本文适合对 Java 空指针痛彻心扉的人阅读,推荐阅读时间25分钟. 若有一些Java8 函数式编程的基础可以当成对基础知识的巩固. 一.万恶的null 今天,我们简单谈谈null的问题.因为null ...
- java内存屏障
为什么会有内存屏障 每个CPU都会有自己的缓存(有的甚至L1,L2,L3),缓存的目的就是为了提高性能,避免每次都要向内存取.但是这样的弊端也很明显:不能实时的和内存发生信息交换,分在不同CPU执行的 ...