CDH5部署三部曲之三:问题总结
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
系列文章链接
本文是《CDH5部署三部曲》的终篇,前面两章完成了CDH5集群的部署和启动,本章将实战中遇到的问题做个总结,如果碰巧您也遇到过这些问题,希望本文能给您一些参考;
启动集群服务报错
- 首次启动集群服务报错,如下图:
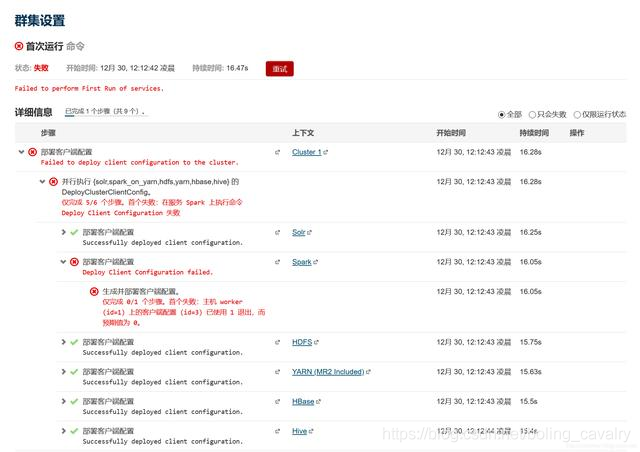
- 上述错误一般是对应节点的/usr/java/default目录下没有JDK所致,假设已将JDK部署在/usr/lib/jvm/jdk1.8.0_191,那么只需执行以下命令建立软链接即可:
mkdir /usr/java &&ln -s /usr/lib/jvm/jdk1.8.0_191 /usr/java/default
- 点击页面上的重试按钮;
NFS Gateway启动失败
- 发现NFS Gateway服务有问题,检查日志:
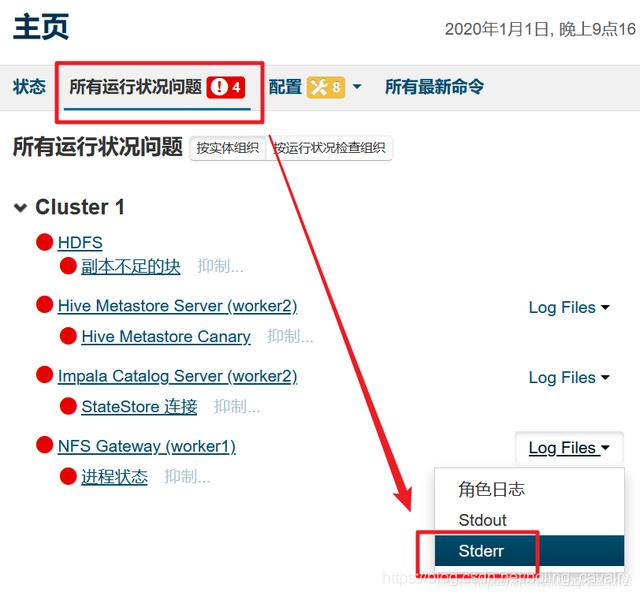
- 日志如下,在worker1节点上,portmap和rpcbind这两个服务不存在导致的:
No portmap or rpcbind service is running on this host. Please start portmap or rpcbind service before attempting to start the NFS Gateway role on this host.
- 于是安装所需服务:
yum install -y nfs-utils rpcbind
- 启动服务:
systemctl start rpcbind
- 再次启动:
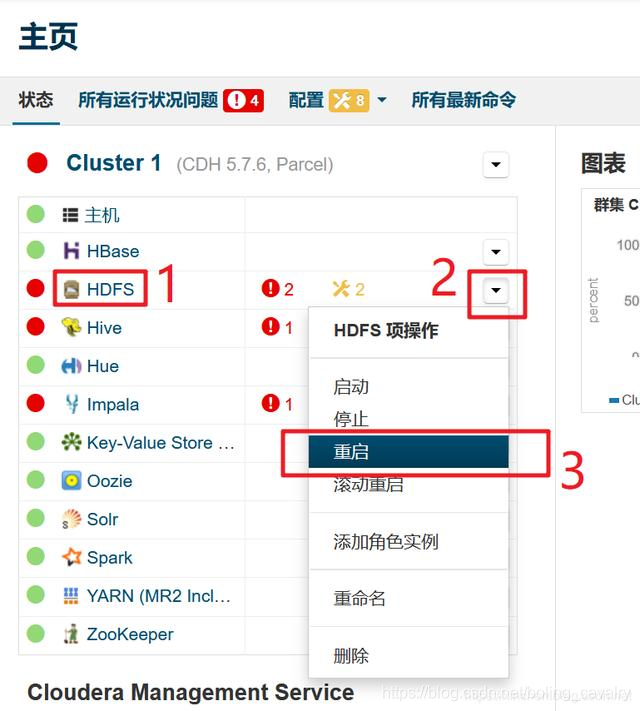
- 等待HDFS服务重启完成后,如下图,可见NFS Gateway问题已经消失:
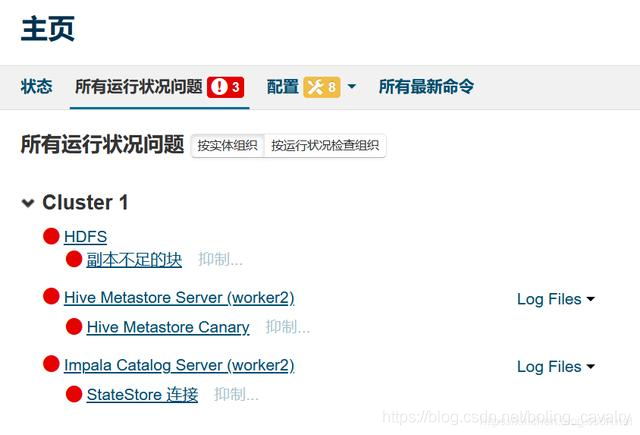
HDFS副本不足的块
- 问题如下图绿框所示:
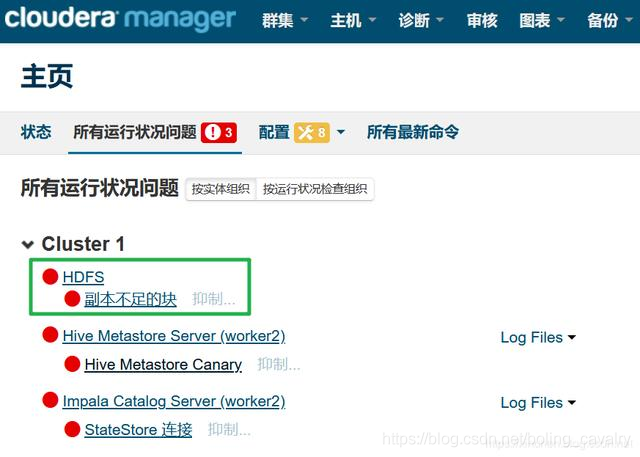
- 目前只有一个datanode,可以增加一个,如下图,进入HDFS的实例页面,点击"添加角色实例":
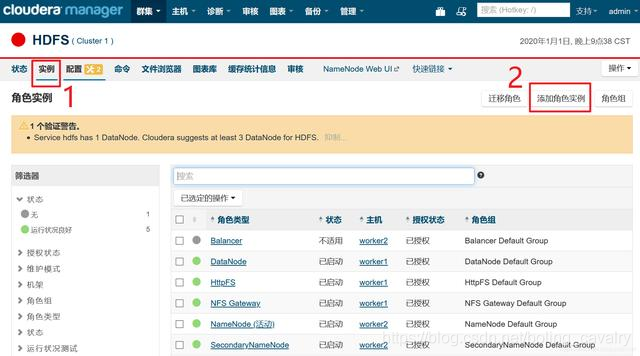
- 点击下图红框位置,增加一个DataNode:
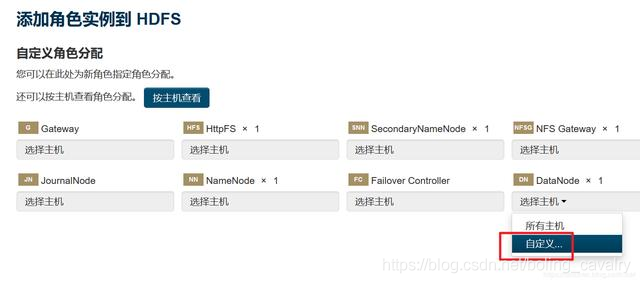
- 如下图,确保worker1和worker2都选上:

- 勾选后,点击红框2中的按钮,在下拉菜单中点击“启动”:
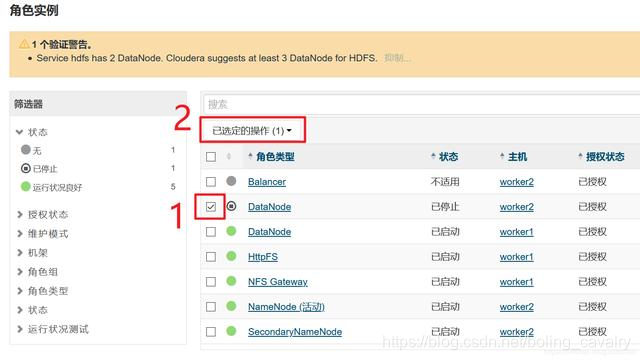
- 现在有了两个DataNode,所以副本数可以设置为2,如下图红框所示,按照顺序找出参数进行设置,记得点击右下角的"保存更改"按钮:
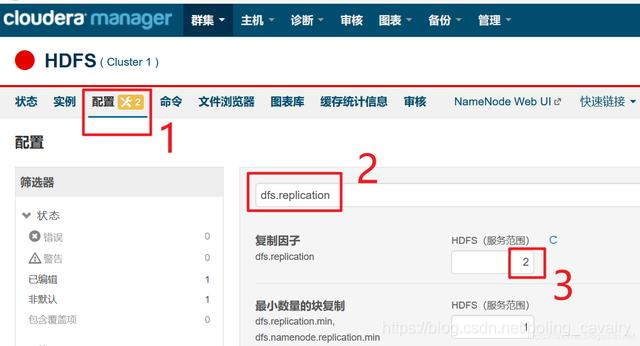
- 上述设置完成后,新写入hdfs的文件副本数为2,如果要将之前已经写入的文件的副本数也调整为2,请SSH登录worker1节点,执行以下命令切换到hdfs账号:
su - hdfs
- 以hdfs账号的身份执行以下命令,即可完成副本数设置:
hadoop fs -setrep -R 2 /
- 返回管理页面,可见HDFS的状态变成了健康:
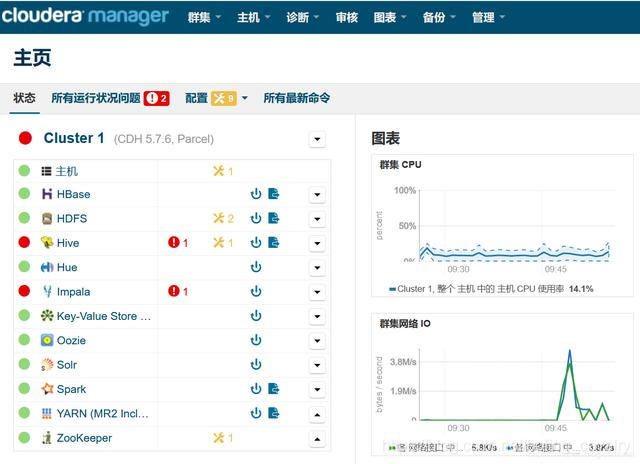
Hive报错
- 如下图红框所示,Hive启动失败,日志中提示Version information not found in metastore
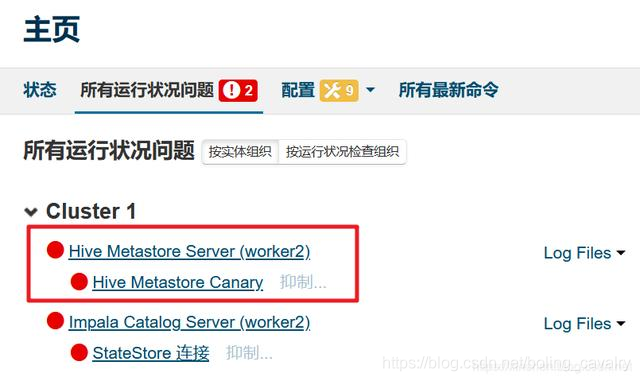
- 从上图可见Hive服务在worker2上,于是SSH登录worker2,将/usr/share/java目录下的mysql-connector-java.jar文件复制到这个目录下:/opt/cloudera/parcels/CDH-5.7.6-1.cdh5.7.6.p0.6/lib/hive/lib/
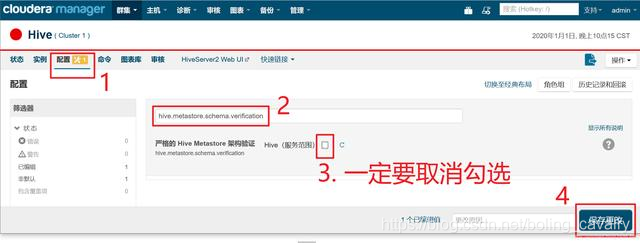
- 在Hive的配置页面,搜索"hive.metastore.schema.verification",如下图,确保红框3中的复选框取消勾选:
- 修改配置datanucleus.autoCreateSchema,如下图,确保红框3中的复选框被选中:
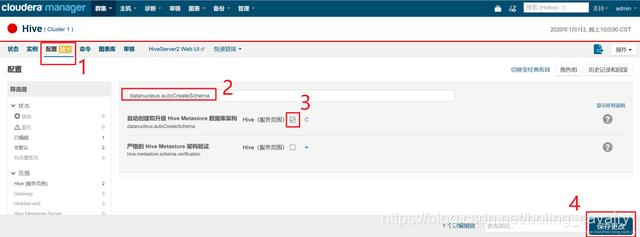
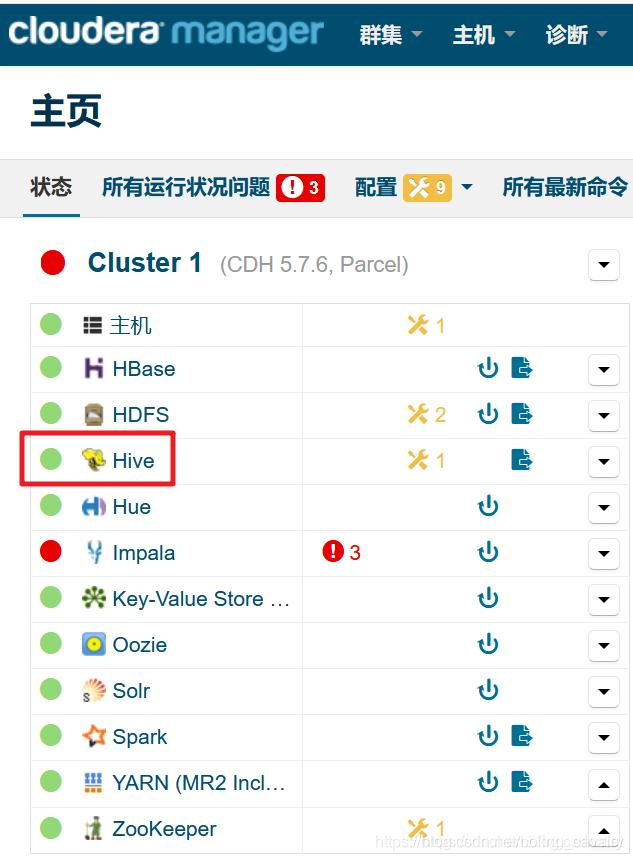
- 重启完成后,Hive状态为健康:
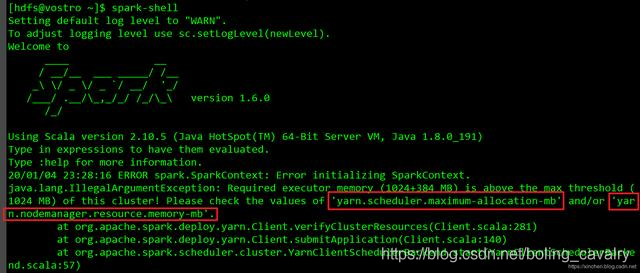
spark-shell执行失败
- 在worker1或者worker2上执行spark-shell命令进入spark控制台时,会产生内存相关的错误,需要调整YARM相关的内存参数:
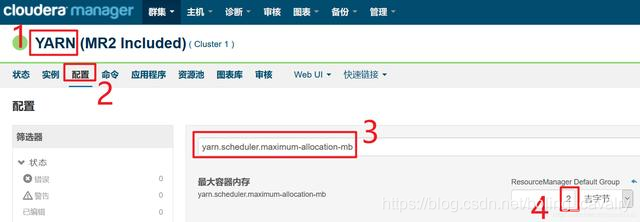
- 在YARN的配置页面,调整yarn.scheduler.maximum-allocation-mb和yarn.nodemanager.resource.memory-mb这两个参数的值,原有的值都是1G,现在都改成2G,如下图:
- 重启YARN;
- 重启Spark;
- 执行spark-shell命令之前,先执行命令su - hdfs切换到hdfs账号;
- 这次终于成功进入spark-shell交互模式:
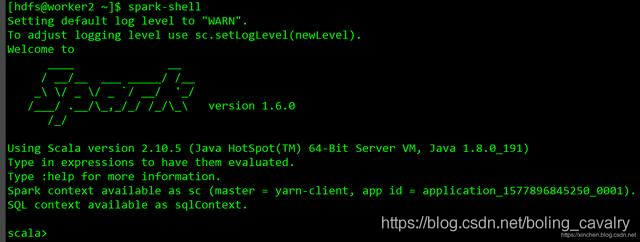
Hue启动失败
- Hue启动失败如下图:
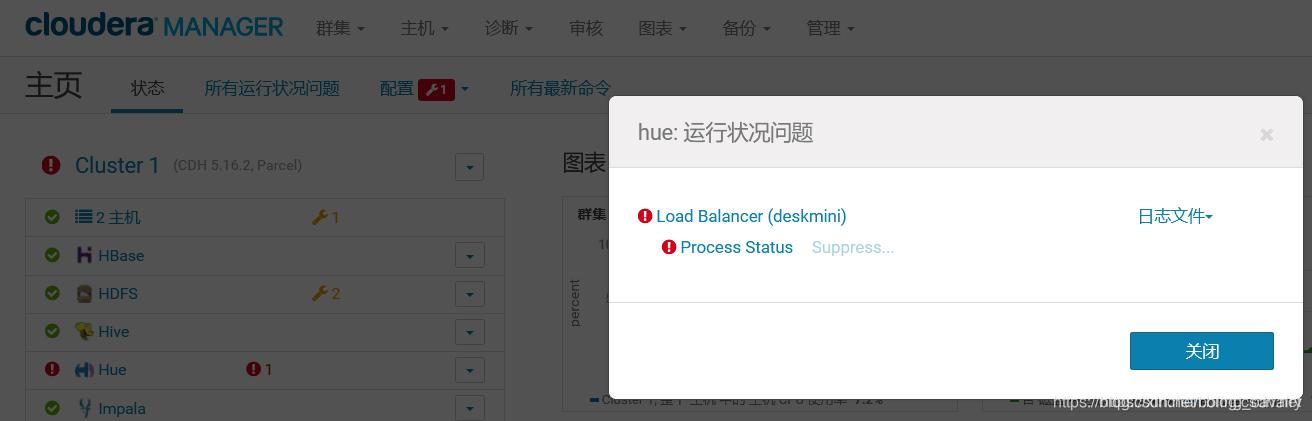
- 上述失败是由于文件夹、文件、httpd服务没有准备好导致的,执行以下命令修复此问题:
mkdir /var/log/hue-httpd/
chown hue:hue /var/log/hue-httpd/
cd /var/log/hue-httpd/
touch error_log
chown hue:hue /var/log/hue-httpd/error_log
yum install -y httpd mod_ssl cyrus-sasl-plain cyrus-sasl-devel cyrus-sasl-gssapi
- 在网页上重启Hue服务,稍后可见服务已经正常:
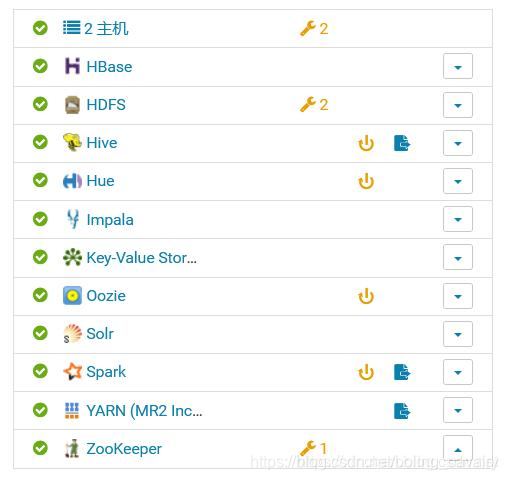
以上就是本次实战过程中遇到的所有问题和解决方法,至此《CDH5部署三部曲》全部完成,如果您正在部署CDH,希望此系列文章能给您一些参考。
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
CDH5部署三部曲之三:问题总结的更多相关文章
- CDH5部署三部曲之一:准备工作
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- CDH5部署三部曲之二:部署和设置
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Docker下实战zabbix三部曲之三:自定义监控项
通过上一章<Docker下实战zabbix三部曲之二:监控其他机器>的实战,我们了解了对机器的监控是通过在机器上安装zabbix agent来完成的,zabbix agent连接上zabb ...
- Flink on Yarn三部曲之三:提交Flink任务
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的DataSource三部曲之三:自定义
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- SQL Server 2008 数据库镜像部署实例之三 配置见证服务器
SQL Server 2008 数据库镜像部署实例之三 配置见证服务器 前面已经完成了镜像数据库的配置,并进行那个了故障转移测试.接下来将部署见证服务器,实现自动故障转移. 一.关于见证服务器 1.若 ...
- kubernetes下的Nginx加Tomcat三部曲之三:实战扩容和升级
本章是<kubernetes下的Nginx加Tomcat三部曲系列>的终篇,今天咱们一起在kubernetes环境对下图中tomcat的数量进行调整,再修改tomcat中web工程的源码, ...
- Docker搭建disconf环境,三部曲之三:细说搭建过程
Docker下的disconf实战全文链接 <Docker搭建disconf环境,三部曲之一:极速搭建disconf>: <Docker搭建disconf环境,三部曲之二:本地快速构 ...
- CoProcessFunction实战三部曲之三:定时器和侧输出
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- MyBatis源码流程分析
mybatis核心流程三大阶段 Mybatis的初始化 建造者模式 建造者模式(Builder Pattern)使用多个简单的对象一步一步构建成一个复杂的对象.这种类型的设计模式属于创建型模式,它提 ...
- 难道主键除了自增就是GUID?支持k8s等分布式场景下的id生成器了解下
背景 主键(Primary Key),用于唯一标识表中的每一条数据.所以,一个合格的主键的最基本要求应该是唯一性. 那怎么保证唯一呢?相信绝大部分开发者在刚入行的时候选择的都是数据库的自增id,因为这 ...
- 局域网内笔记本分屏到android手机上
前提 笔记本电脑1台 安卓/ios手机1部 局域网 spacedesk 预览 参考: https://www.appinn.com/spacedesk https://spacedesk.net/de ...
- Android组件化 + MVP + MVVM
前言 组件化和插件化已经提出了很久了,到现在也是比较稳定的一种架构方案了,在三年前,组件化和插件提出来没多久,前公司就已经在项目中使用了,只是当时还只是菜鸟,没有资格参与到架构的建设中,只是在大佬搭好 ...
- jzoj 3567. 【GDKOI2014】石油储备计划
Problem Description Input Output 对于每组数据,输出一个整数,表示达到"平衡"状态所需的最小代价. Data Constraint 对于20%的数据 ...
- [剑指Offer]65-不用加减乘除做加法
题目 写一个函数,求两个整数之和,要求在函数体内不得使用+.-.*./四则运算符号. 题解 用位运算模拟加法的三步: 无进位加法:异或运算. 进位:与运算再左移一位. 直到进位为0结束. 代码 pub ...
- Windows下使用Nginx+Tomact做负载均衡
前言 今天,王子与大家闲谈一下如何在Windows下使用Nginx+Tomcat做负载均衡的完整步骤,小伙伴们可以试着自己动手实践一下哦. 另外说明一点,本篇文章是纯实操文章,不涉及太多原理的解读,后 ...
- 部署cobbler服务器
部署cobbler服务器 1.准备环境使用nat或者仅主机模式,不要使用桥接模式,方式获取的IP不是自己的 2. 配置yum源[epel]name=epelenabled=1gpgcheck=0bas ...
- vue大型项目高性能优化----想说爱你真的不容易
一.背景 目前公司的电子合同采用表单设计器+合同业务配合实现,做了半年多后终于上线,但是下边员工普遍反映卡顿,甚至卡死,爆栈.尤其是新增和修改合同页面,因为这部分数据量大,逻辑复杂,很容易崩溃,所 ...
- 【JAVA】JAVA相关知识点收集
下面这些链接都是我这段时间(7月-9月)看过的.感觉自己现在处于一个疯狂吸收知识的阶段,如果是文字的方式一点一点搬运到自己的博客既重复又费时间,只有等自己积累到一定程度后才能进行原创性高质量的产出吧. ...