seaborn分类数据可视化:散点图|箱型图|小提琴图|lv图|柱状图|折线图
一、散点图stripplot( ) 与swarmplot()
1.分类散点图stripplot( )
用法stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,jitter=True, dodge=False, orient=None,
color=None, palette=None,size=5, edgecolor="gray", linewidth=0, ax=None, **kwargs)
- x,y 分类字段和分布统计字段
- hue 在x分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- jitter 当点数据重合较多时用该参数做一些调整,可以设置为True或者间距0.1,否则会有重合的点
- dodge 如果有二次分类,二次分类是否拆分显示
tips = sns.load_dataset("tips") #导入系统数据
print(tips.head())
print(tips['day'].value_counts())
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
Sat 87
Sun 76
Thur 62
Fri 19
Name: day, dtype: int64
输出结果
fig = plt.figure(figsize=(15,10))
ax1 = plt.subplot(221)
# 对data数据按day分类,统计total_bill的分布,如果点重合较多适当显示开
sns.stripplot(x="day", y="total_bill", data=tips, jitter = True, size = 5, edgecolor = 'w',linewidth=1, marker = 'o', ax=ax1) ax2 = plt.subplot(222)
# 对data数据按day分类,统计total_bill的分布,并且图表中只显示按day分类的中的Sat和Sun
sns.stripplot(x="day", y="total_bill", data=tips,jitter = True, order = ['Sat','Sun'],ax=ax2) ax3 = plt.subplot(223)
# 对data数据按sex分类后再按day分类,统计total_bill的分布
sns.stripplot(x="sex", y="total_bill", hue="day",data=tips, jitter=True,ax = ax3) ax4 = plt.subplot(224)
# 对data数据按sex分类后再按day分类,统计total_bill的分布,并且不同的day拆分显示
sns.stripplot(x="sex", y="total_bill", hue="day",data=tips, jitter=True,palette="Set2",dodge=True,ax=ax4)
2.分簇散点图swarmplot()
用法swarmplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,dodge=False, orient=None, color=None,
palette=None,size=5, edgecolor="gray", linewidth=0, ax=None, **kwargs)
swarmplot()除了没有jitter参数,其他用法类似stripplot()。
fig = plt.figure(figsize=(20,5))
ax1 = plt.subplot(141)
# 对data数据按day分类,统计total_bill的分布,如果点重合较多适当显示开
sns.swarmplot(x="day", y="total_bill", data=tips, size = 5, edgecolor = 'w',linewidth=1, marker = 'o', ax=ax1) ax2 = plt.subplot(142)
# 对data数据按day分类,统计total_bill的分布,并且图表中只显示按day分类的中的Sat和Sun
sns.swarmplot(x="day", y="total_bill", data=tips, order = ['Sat','Sun'],ax=ax2) ax3 = plt.subplot(143)
# 对data数据按sex分类后再按day分类,统计total_bill的分布
sns.swarmplot(x="sex", y="total_bill", hue="day",data=tips, ax = ax3) ax4 = plt.subplot(144)
# 对data数据按sex分类后再按day分类,统计total_bill的分布,并且不同的day拆分显示
sns.swarmplot(x="sex", y="total_bill", hue="day",data=tips, palette="Set2",dodge=True,ax=ax4)
二、箱型图boxplot()
boxplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,orient=None, color=None, palette=None,
saturation=.75,width=.8, dodge=True, fliersize=5, linewidth=None,whis=1.5, notch=False, ax=None, **kwargs)
- x,y 分类字段和分布统计字段
- hue 在x分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- dodge 如果有二次分类,二次分类是否拆分显示
- width 箱的间隔的比例,值越大间隔越小
- filtersize 异常点大小
- whis 设置IQR
- notch 是否以中值做凹槽
fig = plt.figure(figsize=(12,5)) ax1 = plt.subplot(121)
sns.boxplot(x="day", y="total_bill", data=tips,linewidth = 2, width = 0.8, fliersize = 10, palette = 'hls',whis = 1.5,notch = True)
sns.swarmplot(x="day", y="total_bill", data=tips, color ='g', size = 3, alpha = 0.8) #在箱型图上做分簇散点图 ax2 = plt.subplot(122)
sns.boxplot(x="day", y="total_bill", data=tips, hue = 'smoker', order = ['Sat','Sun'],palette = 'Reds') #根据day分类,再根据smkker分类
三、小提琴图violinplot()
violinplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,bw="scott", cut=2,
scale="area", scale_hue=True, gridsize=100, width=.8, inner="box", split=False, dodge=True,
orient=None,linewidth=None, color=None, palette=None, saturation=.75,ax=None, **kwargs)
- x,y 分类字段和分布统计字段
- hue 在x分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- dodge 如果有二次分类,二次分类的多个小提琴位置是否错开,默认为True,False则多个小提琴会重复 (dodge=True与split=False效果相同)
- split 如果有二次分类,二次分类是否拆分整个提琴,默认为False显示为多个独立的小提琴,True则显示为一个小提琴,左右两侧表示二次分类
- scale = 'area' 设置小提琴图的宽度,area-保持小提琴面积相同,count-按照样本数量决定宽度,width-宽度一样
- gridsize = 100 设置小提琴图边线的平滑度,越高越平滑
- inner = 'box' 设置内部显示类型 → “box”箱型图, “quartile”分位数, “point”点, “stick”, None
- bw = 0.8 # 控制拟合程度,'scott'、'silverman'或者一个浮点数,一般可以不设置
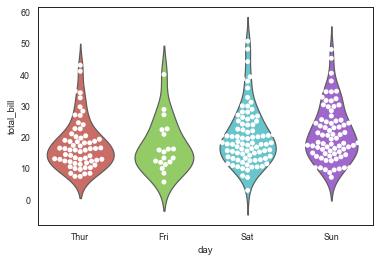
fig = plt.figure(figsize=(20,5)) ax1 = plt.subplot(141)
sns.violinplot(x="day",y="total_bill",data=tips,linewidth=2,width=0.8,palette='hls',scale= 'area',gridsize=50,inner='box') ax2 = plt.subplot(142)
sns.violinplot(x="day",y="total_bill",data=tips,hue = 'smoker',palette="muted",dodge=False,inner="point")#二次分类小提琴位置不错开 ax3 = plt.subplot(143)
sns.violinplot(x="day",y="total_bill",data=tips,hue = 'smoker',palette="muted",split=False,inner="stick")#二次分类不拆分小提琴,显示为多个独立小提琴 ax4 = plt.subplot(144)
sns.violinplot(x="day",y="total_bill",data=tips,hue = 'smoker',palette="muted",split=True,inner="quartile")#二次分类拆分小提琴,左右两侧分别表示二次
小提琴图与分簇散点图结合sns.violinplot()+ sns.swarmplot()
sns.violinplot(x="day", y="total_bill", data=tips, palette = 'hls',alpha=0.5, inner = None)
sns.swarmplot(x="day", y="total_bill", data=tips, color="w")
四、增强箱图boxenplot()
boxenplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,orient=None, color=None,
palette=None, saturation=.75,width=.8,dodge=True, k_depth='proportion', linewidth=None,
scale='exponential', outlier_prop=None, ax=None, **kwargs)
(lv图表使用boxenplot(),lvplot()即将被遗弃)
- x,y 分类字段和分布统计字段
- hue 在x分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- dodge 如果有二次分类,二次分类的多个小提琴位置是否错开,默认为True,False则多个小提琴会重复 (dodge=True与split=False效果相同)
- scale = 'area' 设置lv图的宽度,“linear”、“exonential”、“area” (一般scale和k_depth保持默认就好)
- k_depth = 'proportion', # 设置框的数量 → “proportion”、“tukey”、“trustworthy”
- width 箱之间间隔
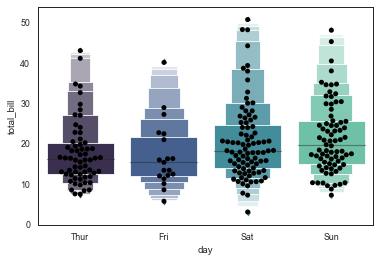
sns.lvplot(x="day", y="total_bill", data=tips, palette="mako", width = 0.8, scale = 'area',k_depth = 'proportion')
sns.swarmplot(x="day", y="total_bill", data=tips, color ='k',size = 5)
五、柱状图barplot()
seaborn中的柱状图不是单纯的表示数量,而是表示了一个统计标准和对应的置信区间。
barplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,estimator=np.mean, ci=95,
n_boot=1000, units=None,orient=None, color=None, palette=None, saturation=.75,errcolor=".26",
errwidth=None, capsize=None, dodge=True,ax=None, **kwargs)
- x,y 分类字段和分布统计字段
- hue 在x分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- estimater 柱状图表示的统计量,默认和常使用均值
- ci 置信区间的误差,0-100之内、或sd标准差,或None,默认为95
- saturation 颜色饱和度
- errcolor与errwidth 误差线颜色与宽度
- capsize 误差线延长宽度
- dodge 如果有二次分类,二次分类的多个多个柱状图位置是否错开
- edgecolor 柱子的边框颜色
#导入泰坦尼克号、小费和汽车事故的3个表的数据结构,在不同窗口显示前5行
titanic = sns.load_dataset("titanic")
titanic.head()
tips = sns.load_dataset('tips') #
tips.head()
crashes = sns.load_dataset("car_crashes")#
crashes.head()

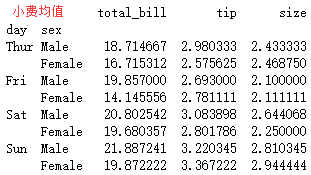
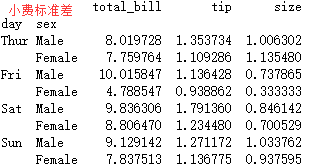
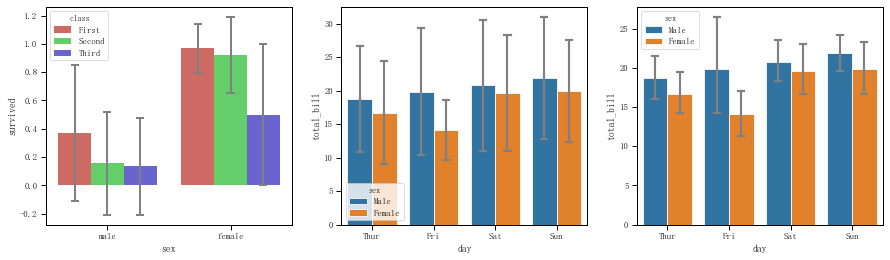
fig = plt.figure(figsize=(15,4))
ax1 = plt.subplot(131) #泰坦尼克,在性别分类的基础上再按舱级别分类,统计生还率
sns.barplot(x="sex",y="survived",hue="class",data=titanic,palette = 'hls',capsize = 0.05,saturation=.8,errcolor = 'gray',errwidth = 2,ci = 'sd')
ax2 = plt.subplot(132) #小费,在日期分类的基础上再按性别分类,统计给的小费,置信区间的误差为标准差
sns.barplot(x="day", y="total_bill", hue="sex", data=tips,edgecolor = 'white',errcolor='gray',capsize=0.1,ci='sd')
ax3 = plt.subplot(133) #小费,同上,置信区间的误差为默认的95
sns.barplot(x="day", y="total_bill", hue="sex", data=tips,edgecolor = 'white',errcolor='gray',capsize=0.1)
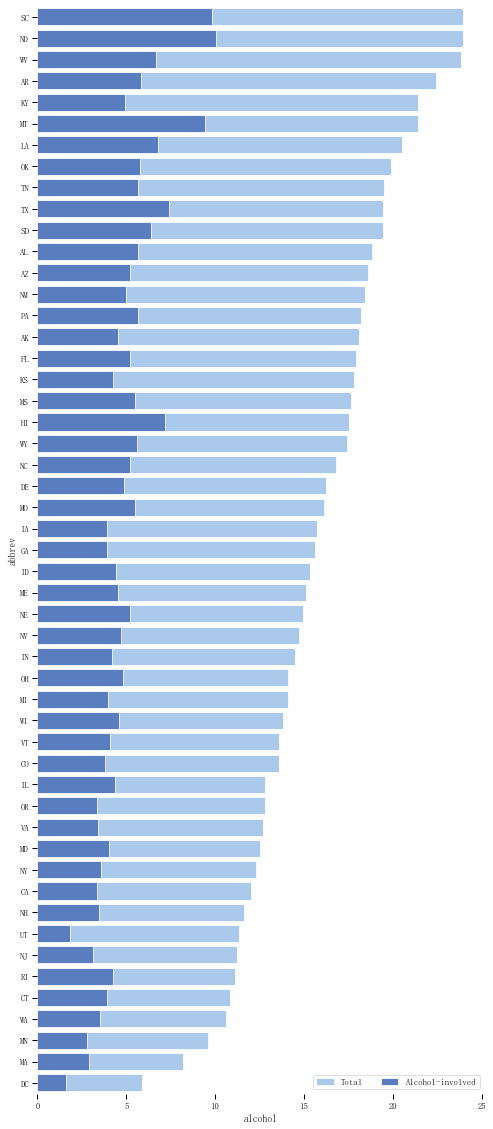
crashes = sns.load_dataset("car_crashes").sort_values("total", ascending=False)
f,ax = plt.subplots(figsize=(8, 20))# 创建图表
sns.set_color_codes("pastel")
sns.barplot(x="total", y="abbrev", data=crashes,label="Total", color='b',edgecolor = 'w')# 设置第一个柱状图
sns.set_color_codes("muted")
sns.barplot(x="alcohol", y="abbrev", data=crashes, label="Alcohol-involved",color='b',edgecolor = 'w')# 设置第二个柱状图
ax.legend(ncol=2, loc="lower right")
sns.despine(left=True, bottom=True)
六、计数柱状图countplot()
countplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,orient=None, color=None,
palette=None, saturation=.75,dodge=True, ax=None, **kwargs)
- x,y 同时表示分类字段和显示方向,即在x轴上或在y轴上对指定的字段进行计数显示
- hue 在x分类或者y分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- dodge 如果有二次分类,二次分类的多个多个柱状图位置是否错开
- edgecolor 柱子的边框颜色
fig = plt.figure(figsize=(12,4))
ax1 = plt.subplot(121)
sns.countplot(x="day", hue="sex", data=tips, palette = 'muted') #竖直显示,在日期分类的基础上再按性别分类
ax2 = plt.subplot(122)
sns.countplot(y="day", hue="sex", data=tips, palette = 'muted') #水平显示
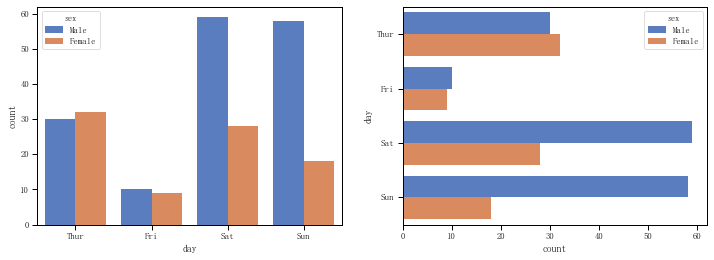
七、折线图pointbar()
折线图pointbar()和barplot()的用法类似,只是barplot()用柱状图表示均值,而pointbar()用一个点表示了均值。
pointplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None,estimator=np.mean, ci=95,
n_boot=1000, units=None,markers="o", linestyles="-", dodge=False, join=True, scale=1,
orient=None, color=None, palette=None, errwidth=None,capsize=None, ax=None, **kwargs)
- x,y 分类字段和分布统计字段
- hue 在x分类的基础上进行二次分类的字段
- data 源数据
- order 图表中显示的分类
- estimater 柱状图表示的统计量,默认和常使用均值
- ci 置信区间的误差,0-100之内、或sd标准差,或None,默认为95
- marker 均值的表示形式
- errwidth 误差线颜色与宽度
- capsize 误差线延长宽度
- dodge 如果有二次分类,二次分类的多个线是否分开
- joint 是否连线
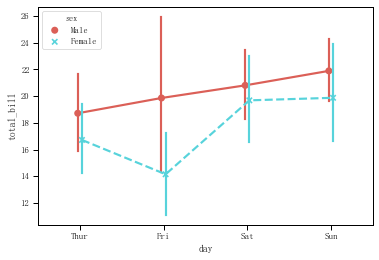
sns.pointplot(x="day",y="total_bill",hue = 'sex',data=tips,palette = 'hls',dodge = True,join = True,markers=["o", "x"],linestyles=["-", "--"])
tips.groupby(['day','sex']).mean()['total_bill']
seaborn分类数据可视化:散点图|箱型图|小提琴图|lv图|柱状图|折线图的更多相关文章
- seaborn分类数据可视化
转载:https://cloud.tencent.com/developer/article/1178368 seaborn针对分类型的数据有专门的可视化函数,这些函数可大致分为三种: 分类数据散点图 ...
- Python图表数据可视化Seaborn:2. 分类数据可视化-分类散点图|分布图(箱型图|小提琴图|LV图表)|统计图(柱状图|折线图)
1. 分类数据可视化 - 分类散点图 stripplot( ) / swarmplot( ) sns.stripplot(x="day",y="total_bill&qu ...
- seaborn教程4——分类数据可视化
https://segmentfault.com/a/1190000015310299 Seaborn学习大纲 seaborn的学习内容主要包含以下几个部分: 风格管理 绘图风格设置 颜色风格设置 绘 ...
- Python数据可视化——散点图
PS: 翻了翻草稿箱. 发现竟然存了一篇去年2月的文章...尽管naive.还是发出来吧... 本文记录了python中的数据可视化--散点图scatter, 令x作为数据(50个点,每一个30维), ...
- C# 绘制统计图(柱状图, 折线图, 扇形图)【转载】
统计图形种类繁多, 有柱状图, 折线图, 扇形图等等, 而统计图形的绘制方法也有很多, 有Flash制作的统计图形, 有水晶报表生成统计图形, 有专门制图软件制作, 也有编程语言自己制作的:这里我们用 ...
- C# 绘制统计图(柱状图, 折线图, 扇形图)
统计图形种类繁多, 有柱状图, 折线图, 扇形图等等, 而统计图形的绘制方法也有很多, 有Flash制作的统计图形, 有水晶报表生成统计图形, 有专门制图软件制作, 也有编程语言自己制作的:这里我们用 ...
- Asp.net 用 Graphics 统计图(柱状图, 折线图, 扇形图)
统计图形种类繁多, 有柱状图, 折线图, 扇形图等等, 而统计图形的绘制方法也有很多, 有Flash制作的统计图形, 有水晶报表生成统计图形, 有专门制图软件制作, 也有编程语言自己制作的:这里我们用 ...
- Excel柱状图折线图组合怎么做 Excel百分比趋势图制作教程
Excel柱状图折线图组合怎么做 Excel百分比趋势图制作教程 用excel作图时候经常会碰到做柱状图和折线图组合,这样的图一般难在折线图的数据很小,是百分比趋势图,所以经常相对前面主数据太小了,在 ...
- seaborn线性关系数据可视化:时间线图|热图|结构化图表可视化
一.线性关系数据可视化lmplot( ) 表示对所统计的数据做散点图,并拟合一个一元线性回归关系. lmplot(x, y, data, hue=None, col=None, row=None, p ...
随机推荐
- el-switch 初始值(默认值)不能正确显示状态问题
<el-table-column align="center" label="状态"> <template slot-scope= ...
- apply()方法和call()介绍
我们发现apply()和call()的真正用武之地是能够扩充函数赖以运行的作用域. 1.call,apply都属于Function.prototype的一个方法,它是JavaScript引擎内在实现的 ...
- Python数据结构-树与树的遍历
树:是一种抽象的数据类型 树的作用:用来模拟树状结构性质的数据集合 树的特点: 每个节点有零个或者多个节点 没有父节点的节点,叫做根节点 每一个根节点有且只有一个父节点 除了根节点外,每个节点可以分成 ...
- Appium移动端自动化测试--搭建模拟器和真机测试环境
详细介绍安装Android Studio及Android SDK.安装Appium Server. 文章目录如下 目录 文章目录如下 模拟器--安装Android Studio及Android SDK ...
- css transparent属性_css 透明颜色transparent的使用
在css中 transparent到底是什么意思呢? transparent 它代表着全透明黑色,即一个类似rgba(0,0,0,0)这样的值. 例如在css属性中定义:background:tran ...
- css div如何隐藏?
在我们平时布局网站的时候,想要把div进行隐藏,但是很多人不知道css控制div显示隐藏?下面我们来讲解一下css如何让div隐藏. 1.使用display:none来隐藏div 我们可以使用disp ...
- 常用API - Scanner、Random、ArrayList
API 概述 API(Application Programming Interface),应用程序编程接口. Java API是一本程序员的 字典 ,是JDK中提供给我们使用的类的说明文档. 这些类 ...
- 冷知识:达夫设备(Duff's Device)效率真的很高吗?
ID:技术让梦想更伟大 作者:李肖遥 wechat链接:https://mp.weixin.qq.com/s/b1jQDH22hk9lhdC9nDqI6w 相信大家写业务逻辑的时候,都是面向if.el ...
- HDU3686 Traffic Real Time Query System 题解
题目 City C is really a nightmare of all drivers for its traffic jams. To solve the traffic problem, t ...
- 使用Python编写的对拍程序
简介 支持数据生成程序模式, 只要有RE或者WA的数据点, 就会停止 支持数据文件模式, 使用通配符指定输入文件, 将会对拍所有文件 结束后将会打印统计信息 第一次在某目录执行,将会通过交互方式获取配 ...