AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法。
1、AdaBoost算法介绍
AdaBoost是Boosting方法中最优代表性的提升算法。该方法通过在每轮降低分对样例的权重,增加分错样例的权重,使得分类器在迭代过程中逐步改进,最终将所有分类器线性组合得到最终分类器,Boost算法框架如下图所示:

图1.1 Boost分类框架(来自PRML)
2、AdaBoost算法过程:
1)初始化每个训练样例的权值,共N个训练样例。
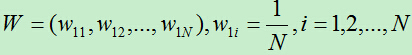
2)共进行M轮学习,第m轮学习过程如下:
A)使用权值分布为Wm的训练样例学习得到基分类器Gm。
B)计算上一步得到的基分类器的误差率:(此公式参考PRML,其余的来自统计学习方法)
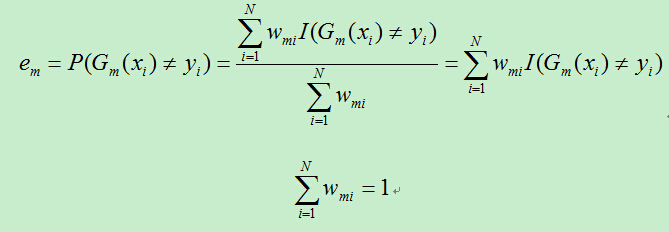
C)计算Gm前面的权重系数:
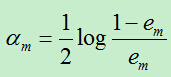
D)更新训练样例的权重系数,
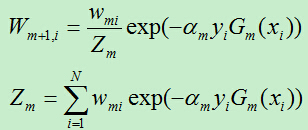
E)重复A)到D)。得到一系列的权重参数am和基分类器Gm
4)将上一步得到的基分类器根据权重参数线性组合,得到最终分类器:
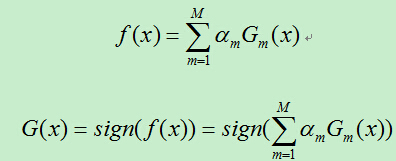
3、算法中的两个权重分析:
1)关于基分类器权重的分析
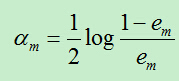
上面计算的am表示基分类器在最终的分类器中所占的权重,am的计算根据em而得到,由于每个基分类器的分类性能要好于随机分类器,故而误差率em<0.5.(对二分类问题)
当em<0.5时,am>0且am随着em的减小而增大,所以,分类误差率越小的基分类器在最终的分类器中所占的权重越大。
注:此处的所有am之后并不为1。
2)训练样例的权重分析
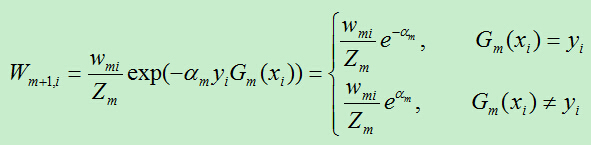
根据公式可知,样例分对和分错,权重相差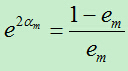 倍(统计学习方法上此公式有误)。
倍(统计学习方法上此公式有误)。
由于am>0,故而exp(-am)<1,当样例被基本分类器正确分类时,其权重在减小,反之权重在增大。
通过增大错分样例的权重,让此样例在下一轮的分类器中被重点关注,通过这种方式,慢慢减小了分错样例数目,使得基分类器性能逐步改善。
4、训练误差分析
关于误差上界有以下不等式,此不等式说明了Adaboost的训练误差是以指数的速度下降的,
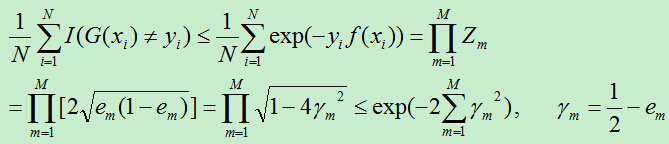
推导过程用到的公式有:
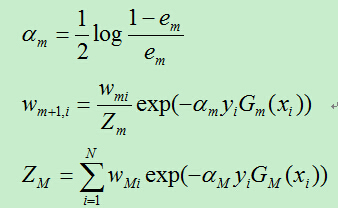
具体推导过程请看统计学习方法课本!
5、AdaBoost算法推导过程
AdaBoost算法使用加法模型,损失函数为指数函数,学习算法使用前向分步算法。
其中加法模型为:
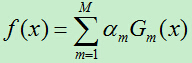
损失函数为指数函数:

我们的目标是要最小化损失函数,通过最小化损失函数来得到模型中所需的参数。而在Adaboost算法中,每一轮都需要更新样例的权重参数,故而在每一轮的迭代中需要将损失函数极小化,然后据此得到每个样例的权重更新参数。这样在每轮的迭代过程中只需要将当前基函数在训练集上的损失函数最小即可。
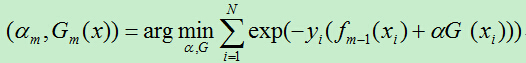
现在我们需要通过极小化上面的损失函数,得到a,G。
设:
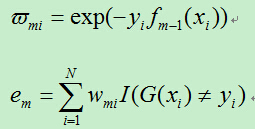
于是有:

为了方便下面推导,我们将:
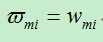
这样,我们就有:

正式推导过程如下:
设: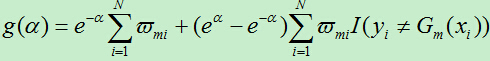
对g(a)求导得:

令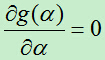 ,得到:
,得到:

其中,在计算过程中用到的em为:
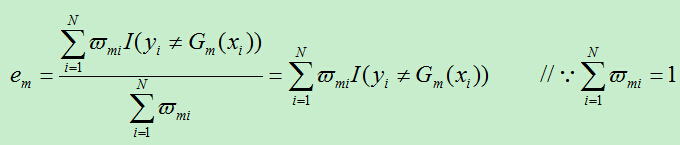
由于 ,所以得到新的损失为:
,所以得到新的损失为:
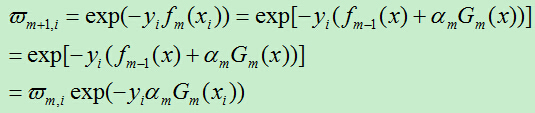
最终的wmi通过规范化得到:
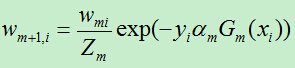
其中规范化因子为:
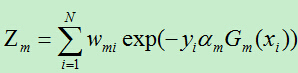
参考文献:
[1] 李航,统计学习方法。
[2] Bishop, Pattern Recognition and Machine Learning
AdaBoost 算法原理及推导的更多相关文章
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- AdaBoost算法原理简介
AdaBoost算法原理 AdaBoost算法针对不同的训练集训练同一个基本分类器(弱分类器),然后把这些在不同训练集上得到的分类器集合起来,构成一个更强的最终的分类器(强分类器).理论证明,只要每个 ...
- 集成学习之Adaboost算法原理
在boosting系列算法中,Adaboost是最著名的算法之一.Adaboost既可以用作分类,也可以用作回归. 1. boosting算法基本原理 集成学习原理中,boosting系列算法的思想:
- 【机器学习】算法原理详细推导与实现(六):k-means算法
[机器学习]算法原理详细推导与实现(六):k-means算法 之前几个章节都是介绍有监督学习,这个章解介绍无监督学习,这是一个被称为k-means的聚类算法,也叫做k均值聚类算法. 聚类算法 在讲监督 ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 机器学习之Adaboost算法原理
转自:http://www.cnblogs.com/pinard/p/6133937.html 在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习 ...
- 基于单层决策树的AdaBoost算法原理+python实现
这里整理一下实验课实现的基于单层决策树的弱分类器的AdaBoost算法. 由于是初学,实验课在找资料的时候看到别人的代码中有太多英文的缩写,不容易看懂,而且还要同时看代码实现的细节.算法的原理什么的, ...
- AdaBoost算法原理及OpenCV实例
备注:OpenCV版本 2.4.10 在数据的挖掘和分析中,最基本和首要的任务是对数据进行分类,解决这个问题的常用方法是机器学习技术.通过使用已知实例集合中所有样本的属性值作为机器学习算法的训练集,导 ...
- 强化学习-学习笔记7 | Sarsa算法原理与推导
Sarsa算法 是 TD算法的一种,之前没有严谨推导过 TD 算法,这一篇就来从数学的角度推导一下 Sarsa 算法.注意,这部分属于 TD算法的延申. 7. Sarsa算法 7.1 推导 TD ta ...
随机推荐
- zf-关于荆州首页鼠标移动到导航栏上去触发的js 显示 问题解决办法
是我copy代码的 时候 这个触发的属性没有修改,导致出现BUG,改成mopen('m2') 就好了
- drawRect 进阶
iOS的绘图操作是在UIView类的drawRect方法中完成的,所以如果我们要想在一个UIView中绘图,需要写一个扩展UIView 的类,并重写drawRect方法,在这里进行绘图操作,程序会自动 ...
- UIView 面面观
原创:转载请注明出处 1.UIView: 一个视图对象控制该区域的渲染,同时也控制内容的交互. 2.UIView的功能就是:展示.渲染.交互 3.UIView 和很多其他视图控件的默认tag值是0,所 ...
- hudson配置教程
Hudson配置教程 hudson是个优 秀的开源工具,可惜是小日本开发的.这点不爽.拿过来用吧.我们公司(Qisda)的用途是 用来晚上定时的抓Android的代码,然后编译,保存img文件,然后根 ...
- PAT (Advanced Level) 1041. Be Unique (20)
简单题. #include<cstdio> #include<cstring> #include<cmath> #include<vector> #in ...
- UML用例图说明
转自:http://www.360doc.com/content/10/1206/23/3123_75672033.shtml 前些时间参加了潘加宇老师的技术讲座,UML建模技术受益匪浅.我也把平时的 ...
- 转html5语义化标签总结一
HTML 5的革新之一:语义化标签一节元素标签. 在HTML 5出来之前,我们用div来表示页面章节,但是这些div都没有实际意义.(即使我们用css样式的id和class形容这块内容的意义).这些标 ...
- Java虚拟机中的内存分配
java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域.这些区域都有各自的用途以及创建和销毁的时间. 栈:存放的是局部变量,包括:1.用来保存基本数据类型的值:2.保存类 ...
- hive第二篇----hive中partition如何使用
一.背景 1.在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作.有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念. 2.分区表指的是在创建表 ...
- 编译安装CoreSeek-4.1
编译安装CoreSeek-4.1 yum -y install expat-devel* wget http://www.coreseek.cn/uploads/csft/4.0/coreseek- ...