AdaBoost算法原理及OpenCV实例
备注:OpenCV版本 2.4.10
在数据的挖掘和分析中,最基本和首要的任务是对数据进行分类,解决这个问题的常用方法是机器学习技术。通过使用已知实例集合中所有样本的属性值作为机器学习算法的训练集,导出一个分类机制后,再使用这个分类机制判别一个新实例的属性,并且可以通过不间断的学习,持续丰富和优化该分类机制,使机器具有像大脑一样的思考能力。
常用的分类方法有决策树分类、贝叶斯分类等。然而这些方法存在的问题是当数据量巨大时,分类的准确率不高。对于这样的困难问题,Boosting及其衍生算法提供了一个理想的解决途径。
Boosting算法是一种把若干个分类器整合为一个分类器的方法,其基本思想是:把一个复杂的分类任务分配给多位专家进行判断。这些专家可能并不是真正的专家,而仅仅是比普通人专业一点,他们称为弱分类器,依据一定机制,综合各位专家的结论,形成强分类器,得到最终的判断。
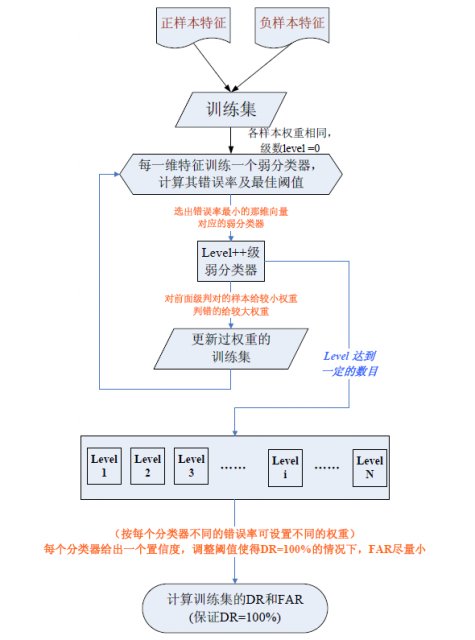
Boosting算法中应用最为广泛也最为有效的是1995年提出的AdaBoost(Adaptive Boosting,自适应增强)方法,其自适应之处在于前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个分类器,每一轮训练都会产生一个弱分类器,直到达到某个预订的足够小的错误率或者达到预先定义的最大迭代次数。
具体来说,整个AdaBoost迭代算法分为3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
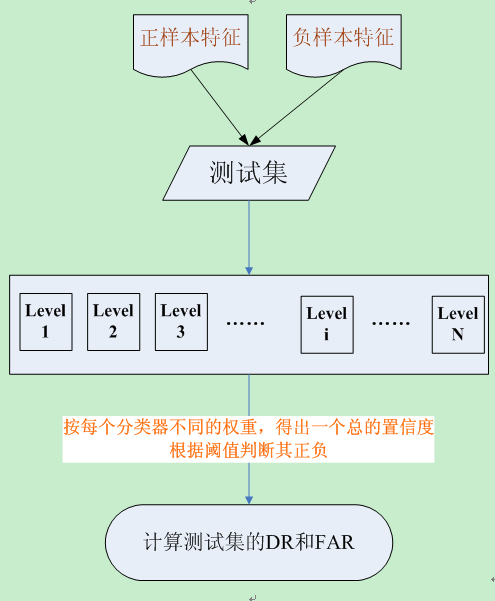
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/ml/ml.hpp"
#include <iostream>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
//训练样本
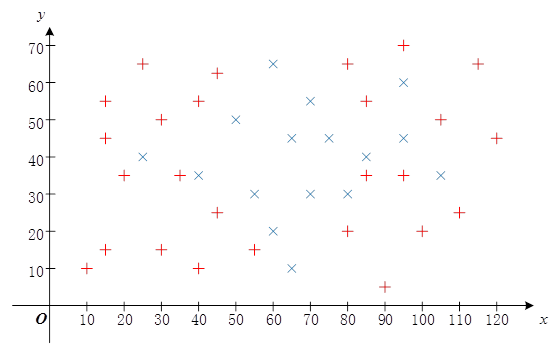
float trainingData[42][2]={ {40, 55},{35, 35},{55, 15},{45, 25},{10, 10},{15, 15},{40, 10},
{30, 15},{30, 50},{100, 20},{45, 65},{20, 35},{80, 20},{90, 5},
{95, 35},{80, 65},{15, 55},{25, 65},{85, 35},{85, 55},{95, 70},
{105, 50},{115, 65},{110, 25},{120, 45},{15, 45},
{55, 30},{60, 65},{95, 60},{25, 40},{75, 45},{105, 35},{65, 10},
{50, 50},{40, 35},{70, 55},{80, 30},{95, 45},{60, 20},{70, 30},
{65, 45},{85, 40} };
Mat trainingDataMat(42, 2, CV_32FC1, trainingData);
//训练样本的响应值
float responses[42] = {'R','R','R','R','R','R','R','R','R','R','R','R','R','R','R','R',
'R','R','R','R','R','R','R','R','R','R',
'B','B','B','B','B','B','B','B','B','B','B','B','B','B','B','B' };
Mat responsesMat(42, 1, CV_32FC1, responses);
float priors[2] = {1, 1}; //先验概率
CvBoostParams params( CvBoost::REAL, // boost_type
10, // weak_count
0.95, // weight_trim_rate
15, // max_depth
false, // use_surrogates
priors // priors
);
CvBoost boost;
boost.train ( trainingDataMat,
CV_ROW_SAMPLE,
responsesMat,
Mat(),
Mat(),
Mat(),
Mat(),
params
);
//预测样本
float myData[2] = {55, 25};
Mat myDataMat(2, 1, CV_32FC1, myData);
double r = boost.predict( myDataMat );
cout<<endl<<"result: "<<(char)r<<endl;
return 0;
} 输出结果为R,即测试坐标点(55,25)被分类为Red。
AdaBoost算法原理及OpenCV实例的更多相关文章
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- AdaBoost算法原理简介
AdaBoost算法原理 AdaBoost算法针对不同的训练集训练同一个基本分类器(弱分类器),然后把这些在不同训练集上得到的分类器集合起来,构成一个更强的最终的分类器(强分类器).理论证明,只要每个 ...
- Python实现的选择排序算法原理与用法实例分析
Python实现的选择排序算法原理与用法实例分析 这篇文章主要介绍了Python实现的选择排序算法,简单描述了选择排序的原理,并结合实例形式分析了Python实现与应用选择排序的具体操作技巧,需要的朋 ...
- 集成学习之Adaboost算法原理
在boosting系列算法中,Adaboost是最著名的算法之一.Adaboost既可以用作分类,也可以用作回归. 1. boosting算法基本原理 集成学习原理中,boosting系列算法的思想:
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 机器学习之Adaboost算法原理
转自:http://www.cnblogs.com/pinard/p/6133937.html 在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习 ...
- 基于单层决策树的AdaBoost算法原理+python实现
这里整理一下实验课实现的基于单层决策树的弱分类器的AdaBoost算法. 由于是初学,实验课在找资料的时候看到别人的代码中有太多英文的缩写,不容易看懂,而且还要同时看代码实现的细节.算法的原理什么的, ...
- AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法. 1.AdaBoost算法介绍 AdaBoost是Boosting方法中最优代表性的提升算法.该方法通过在每轮降低分对样例的权重 ...
- 随机森林算法原理及OpenCV应用
随机森林算法是机器学习.计算机视觉等领域内应用较为广泛的一个算法.它不仅可以用来做分类(包括二分类和多分类),也可用来做回归预测,也可以作为一种数据降维的手段. 在随机森林中,将生成很多的决策树,并不 ...
随机推荐
- aspcms产品详情页调取相关产品
产品详情页调用相关产品最常见的应用就是装饰公司网站,设计师页面要求调取设计师做过的案例.aspcms本身有这个功能,但不能完全符合要求,看代码 {aspcms:content sort={aspcms ...
- LeetCode——Set Matrix Zeroes
Given a m x n matrix, if an element is 0, set its entire row and column to 0. Do it in place. 原题链接:h ...
- thinkphp3.2.3 自动验证 正则验证
<?php namespace Home1\Model; use Think\Model; class ShopYuyueInfoModel extends Model { // protect ...
- 数学分析告诉偶们什么(vamei)
1]人生的痛苦在于追求错误的东西.所谓追求错误的东西,就是你在无限趋近于它的时候,才猛然发现,你和它是不连续的. 2]人和人就像数轴上的有理数点,彼此能够靠得非常近非常近,但你们之间始终存在隔阂. 3 ...
- ImageView一例 分类: H1_ANDROID 2013-10-30 23:02 1812人阅读 评论(0) 收藏
参考自<疯狂android讲义>2.4节 效果如下: 当点击图上某点时,将之附近放大至下图. 布局文件: <LinearLayout xmlns:android="http ...
- 一个神奇的控件——Android CoordinatorLayout与Behavior使用指南
CoordinatorLayout是support.design包中的控件,它可以说是Design库中最重要的控件. 本文通过模仿知乎介绍了自定义Behavior,通过模仿百度地图介绍了BottomS ...
- 【codeforces 742C】Arpa's loud Owf and Mehrdad's evil plan
time limit per test1 second memory limit per test256 megabytes inputstandard input outputstandard ou ...
- source insight totalcmd 中文目录
@echo off for /F "usebackq delims=" %%a in (`echo %1^^^|iconv -f utf-8 -t gb18030`) do ( s ...
- SQLite单表4亿订单,大数据测试
[转载] SQLite单表4亿订单,大数据测试 http://www.cnblogs.com/nnhy/p/BigData.html
- 以Network Dataset(网络数据集)方式实现的最短路径分析
转自原文 以Network Dataset(网络数据集)方式实现的最短路径分析 构建网络有两种方式,分别是网络数据集NetworkDataset和几何网络Geometric Network,这个网络结 ...