selenium爬虫2
无头浏览器简介
无头浏览器(Headless Browser)是一种没有图形用户界面的浏览器,它在后台运行,不会显示任何窗口或界面。无头浏览器通常用于自动化任务,如网页抓取、自动化测试和性能监控等。
爬取票房
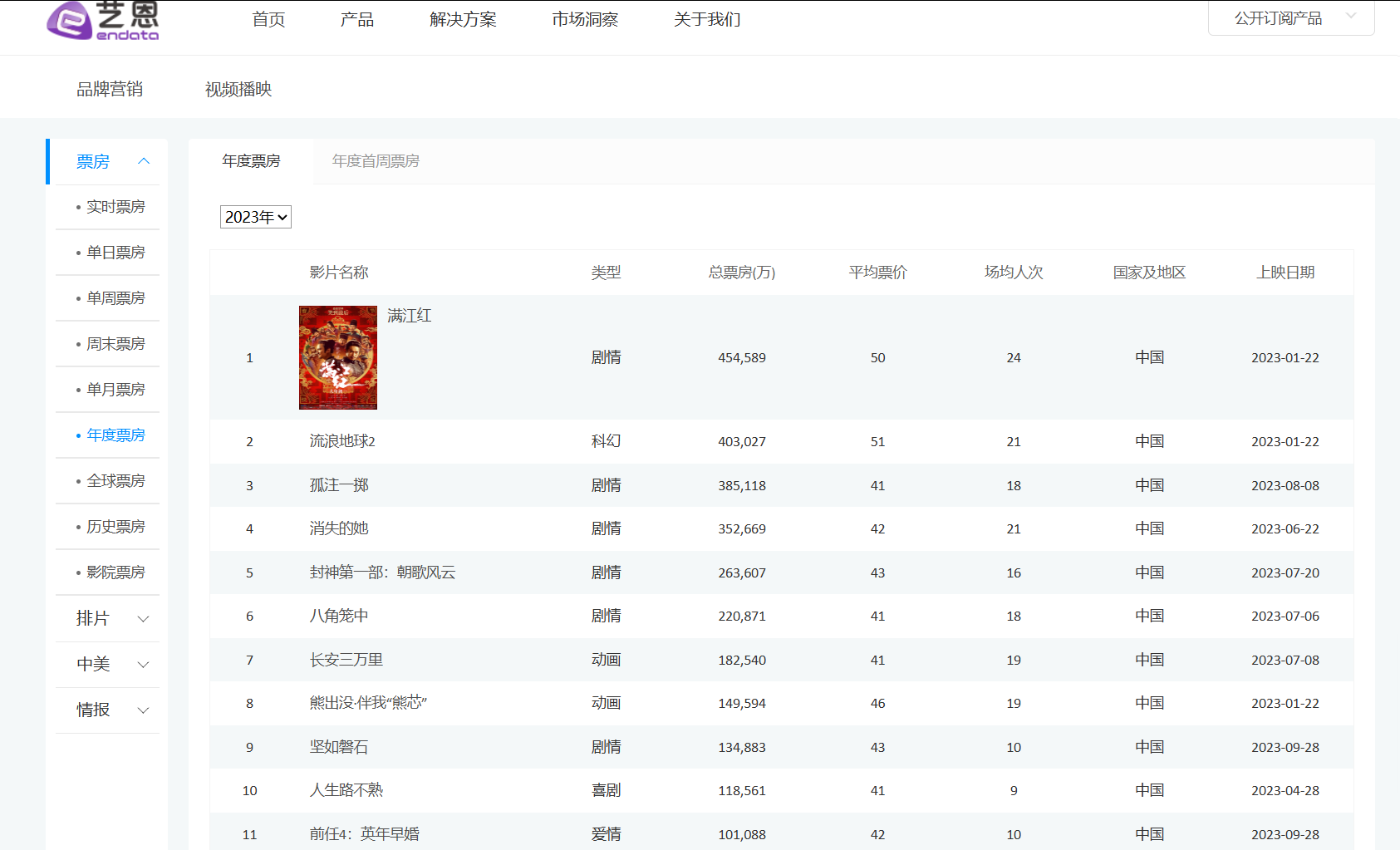
比如我要爬取上图的2008--2024年的热门电影票房排名
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.support.ui import Select
from selenium.webdriver.chrome.options import Options
options = Options()# 添加配置
options.add_argument('--headless')
options.add_argument('--disable-gpu')
# 初始化浏览器驱动
driver = webdriver.Chrome(options=options)
# 打开
driver.get("http://www.endata.com.cn/BoxOffice/BO/Year/index.html")
sel_el=driver.find_element(By.XPATH,'/html/body/section/div/div[2]/div/div/div[1]/select') # 定位select标签
sel=Select(sel_el)
for s in range(len(sel.options)):
sel.select_by_index(s)
time.sleep(1.5)
table=driver.find_element(By.XPATH,'//*[@id="TableList"]/table')
print(table.text)
input("Enter to quit")
driver.quit()
--headless
含义:--headless 选项用于启用无头模式。
作用:当这个选项被添加到浏览器启动参数中时,浏览器将以无头模式运行,即没有图形用户界面(GUI)。这意味着浏览器不会显示任何窗口或界面,但仍然可以执行所有正常的浏览器操作,例如加载页面、执行 JavaScript 等。
用途:无头模式特别适合用于自动化测试、网页抓取和服务器环境下的任务,因为它更高效且不需要显示图形界面。
--disable-gpu
含义:--disable-gpu 选项用于禁用 GPU 硬件加速。
作用:某些情况下,无头模式下的浏览器可能会遇到与 GPU 硬件加速相关的问题。通过禁用 GPU,可以避免这些潜在的问题,确保浏览器在无头模式下稳定运行。
用途:虽然现代浏览器在无头模式下通常会自动处理 GPU 问题,但显式地禁用 GPU 可以增加兼容性,特别是在不同的操作系统和硬件配置上。
关于下拉菜单
2024年
2023年
2022年
2021年
2020年
2019年
2018年
2017年
2016年
2015年
2014年
2013年
2012年
2011年
2010年
2009年
2008年
网页上的下拉菜单的html代码:
<div class="time-sel">
<select id="OptionDate" class="select-time-wrap ml10 mr10">
<option value="2024">2024年</option>
<option value="2023">2023年</option>
<option value="2022">2022年</option>
<option value="2021">2021年</option>
<option value="2020">2020年</option>
<option value="2019">2019年</option>
<option value="2018">2018年</option>
<option value="2017">2017年</option>
<option value="2016">2016年</option>
<option value="2015">2015年</option>
<option value="2014">2014年</option>
<option value="2013">2013年</option>
<option value="2012">2012年</option>
<option value="2011">2011年</option>
<option value="2010">2010年</option>
<option value="2009">2009年</option>
<option value="2008">2008年</option>
</select>
</div>
select_by_index(self,index) #按选项索引选择,从零开始
select_by_value(self,value) #按选项标签的value属性值选择,上面是2008、2009、2010等
select_by_visilbe_text(self,text) #按下拉选项option标签的内容选择,如2022年、2020年
效果
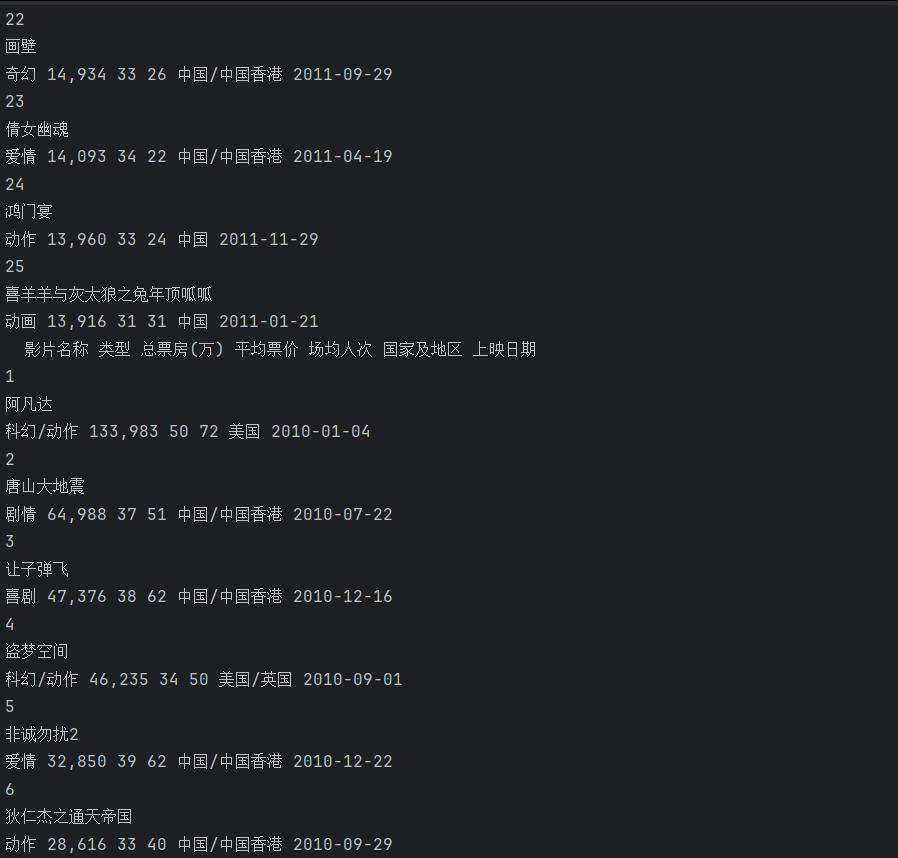
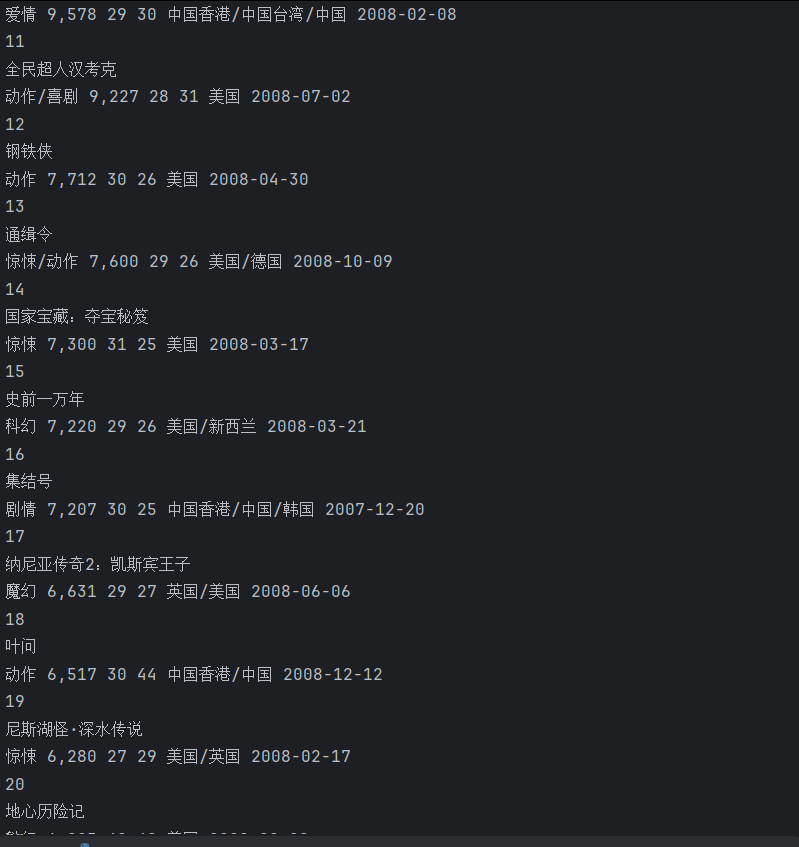
selenium爬虫2的更多相关文章
- Python爬虫之selenium爬虫,模拟浏览器爬取天猫信息
由于工作需要,需要提取到天猫400个指定商品页面中指定的信息,于是有了这个爬虫.这是一个使用 selenium 爬取天猫商品信息的爬虫,虽然功能单一,但是也算是 selenium 爬虫的基本用法了. ...
- python爬虫---单线程+多任务的异步协程,selenium爬虫模块的使用
python爬虫---单线程+多任务的异步协程,selenium爬虫模块的使用 一丶单线程+多任务的异步协程 特殊函数 # 如果一个函数的定义被async修饰后,则该函数就是一个特殊的函数 async ...
- 爬虫(十一):selenium爬虫
1. selenium基础 selenium部分可以去看我写的selenium基础部分,由于链接太多了这里就不发出来了. 代理ip: 有时候频繁爬取一些网页.服务器发现你是爬虫后会封掉你的ip地址.这 ...
- Selenium爬虫实践(踩坑记录)之ajax请求抓包、浏览器退出
上一篇: 使用Selenium截取网页上的图片 前言 最近在搞公司内部系统,累的一批,需要从另一个内部系统导出数据存到数据库做分析,有大量的数据采集工作,又没办法去直接拿到那个系统的接口,太难了,只能 ...
- Ubuntu下的Selenium爬虫的配置
在服务器Ubuntu系统上跑爬虫,爬虫是基于Selenium写的,遇到好几个问题,现在这里记录一下. 1. 安装环境 阿里云,Ubuntu16.04,因为没有界面,所以远程命令行操作.爬虫是基于Sel ...
- Katalon Recorder 自动录制 Selenium 爬虫脚本
相信很多小伙伴都用过 Selenium 来完成爬虫工作,今天就给大家带来一个神器,可以录制你的浏览器动作,然后直接生成 Selenium 脚本,是不是心动了? 1 Selenium 简介 Seleni ...
- selenium爬虫
Web自动化测试工具,可运行在浏览器,根据指令操作浏览器,只是工具,必须与第三方浏览器结合使用,相比于之前学的爬虫只是慢了一点而已.而且这种方法爬取的东西不用在意时候ajax动态加载等反爬机制.因此找 ...
- 使用selenium爬虫抓取数据
写在前面 本来这篇文章该几个月前写的,后来忙着忙着就给忘记了.ps:事多有时候反倒会耽误事.几个月前,记得群里一朋友说想用selenium去爬数据,关于爬数据,一般是模拟访问某些固定网站,将自己关注的 ...
- selenium爬虫入门(selenium+Java+chrome)
selenium是一个开源的测试化框架,可以直接在浏览器中运行,就像用户直接操作浏览器一样,十分方便.它支持主流的浏览器:chrome,Firefox,IE等,同时它可以使用Java,python,J ...
- python selenium爬虫工具
今天seo的同事需要一个简单的爬虫工具, 根据一个url地址,抓取改页面的a连接,然后进入a连接里面的页面再次抓取a连接 1.需要一个全局的set([])集合来保存抓取的url地址 2.由于现在单页面 ...
随机推荐
- U盘或光盘启动的Win7-8-10的PE系统制作步骤
U盘或光盘启动的Win7-8-10的PE系统制作步骤 1.打开http://www.ushendu.com/下载PE制作工具 2.下载完成后安装到我的电脑, 把准备好的U盘插到电脑上,打开U深度PE制 ...
- 【Java并发编程线程池】 ForkJoinPool 线程池是什么 怎么工作的 和传统的ThreadPoolExecutor比较
Java 中的 ForkJoinPool 线程池是什么 怎么工作的 Java 中的 ForkJoinPool 线程池是什么 怎么工作的 相比较于传统的线程池,ForkJoinPool 线程池更适合处理 ...
- 画(HB To Ryby!)
"客人,请描述得具体一点." 他似乎还是很难为情. "呃--就是--一个女孩儿",他又勉强启开嘴,"女孩儿"三个字几乎被咽进嗓子 ...
- CDS标准视图:维护通知数据 I_PMNotifMaintenanceData
视图名称:维护通知数据 I_PMNotifMaintenanceData 视图类型:基础视图 视图代码: 点击查看代码 @EndUserText.label: 'Notification Mainte ...
- Python串口实现dk-51e1单相交直流标准源通信
Python实现dk-51e1单相交直流标准源RS232通信 使用RS232,信号源DK51e1的协议帧格式如下: 注意点 配置串口波特率为115200 Check异或和不需要加上第一个0x81的字段 ...
- h5 页面播放base64编码的audio数据
例子: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8 ...
- 引发类型为“System.Windows.Forms.AxHost+InvalidActiveXStateException”的异常 解决办法
出现题目的异常,多是引用第三方控件引起的. 在NEW时,需要初始化该对象. AxESACTIVEXLib.AxESActiveX ax = new AxESACTIVEXLib.AxESActiveX ...
- 第一二章(Nginx+Lua)开发环境
第一章 安装OpenResty(Nginx+Lua)开发环境 首先我们选择使用OpenResty,其是由Nginx核心加很多第三方模块组成,其最大的亮点是默认集成了Lua开发环境,使得Nginx可以作 ...
- .NET Core GC计划阶段(plan_phase)底层原理浅谈
简介 在mark_phase阶段之后,所有对象都被标记为有用/垃圾对象.此时,垃圾回收器已经拥有启动垃圾回收的所有前置准备工作. 这个时候,垃圾回收期应该执行"清除回收"还是&qu ...
- Collection接口与其子接口实现类-----总复习
数组与集合 1. 集合与数组存储数据概述:集合.数组都是对多个数据进行存储操作的结构,简称Java容器.说明:此时的存储,主要指的是内存层面的存储,不涉及到持久化的存储(.txt,.jpg,.avi, ...