Learning Scrapy笔记(五)- Scrapy登录网站
摘要:介绍了使用Scrapy登录简单网站的流程,不涉及验证码破解
简单登录
很多时候,你都会发现你需要爬取数据的网站都有一个登录机制,大多数情况下,都要求你输入正确的用户名和密码。现在就模拟这种情况,在浏览器打开网页:http://127.0.0.1:9312/dynamic,首先打开调试器,然后点击Elements标签,查看登录表单的源代码

再点击Network标签,然后在用户名框里输入user,在密码框里输入pass,再点击login按钮
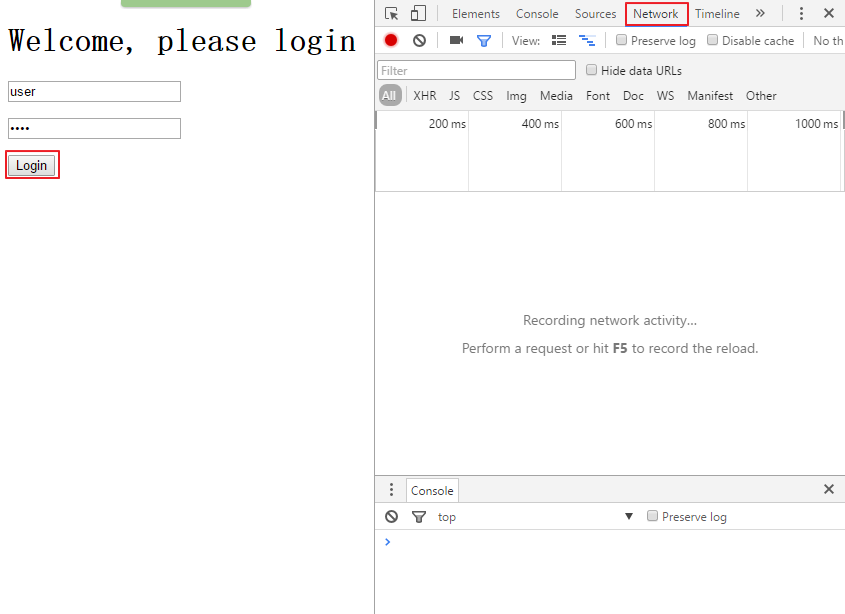
点击调试器里的login页面,观察下面的情况
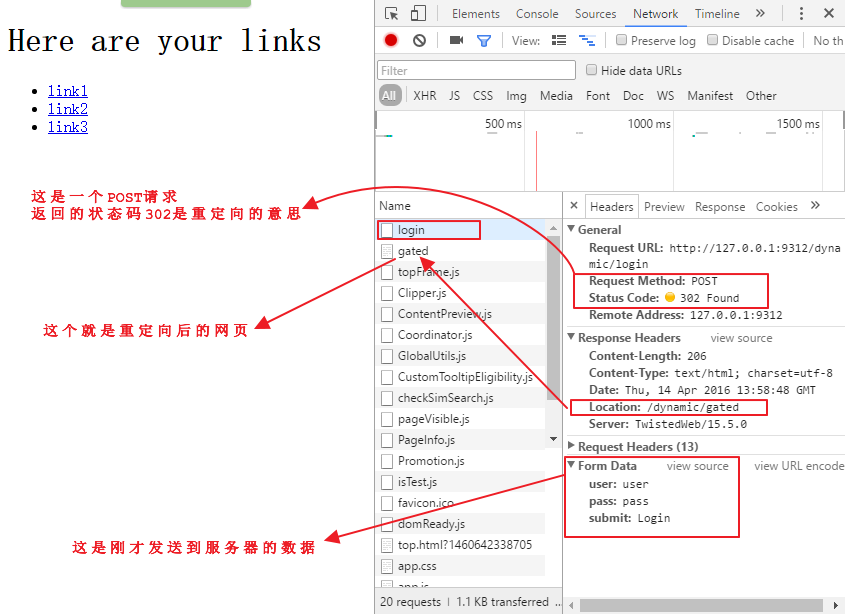
点击调试器里的gated页面,观察下面的情况
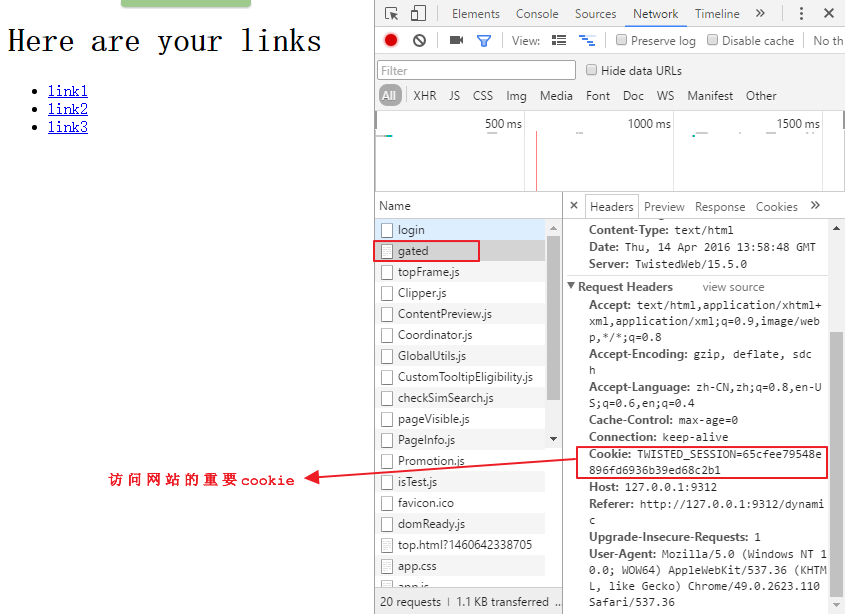
HTTP的cookie是由服务器发送给浏览器,由一些文本和数字组成的字符串,之后浏览器访问服务器的任何请求里都会带着这个cookie来标识你的身份和session,从而能够让你修改在这个网站上的个人信息。
总的来说,一个登录操作会包含几个从浏览器到服务器的往返操作,而Scrapy会自动处理这些操作。
login.py的源代码地址:
继续在上面的名为easy的spider上扩展代码,首先将easy.py复制为login.py,然后做以下修改:
将spider的名称修改为login
这里会使用FormRequest类来登录,这个类与之前的Request类很相似,只是带有额外的formdata参数用来传送登录的表单信息(用户名和密码),为了使用这个类,需要使用以下语句导入:from scrapy.http import FormRequest
然后用startrequests()函数来代替starturls语句,这样做的原因是我们需要定制更多的参数,最后的函数是这样的
# Start with a login request
def start_requests(self):
return [
FormRequest(
"http://web:9312/dynamic/login",
formdata={"user": "user", "pass": "pass"}
#formdata字典里的key名就是第一张图中用红线标注的input标签中的name值
)]
就这么简单,Scrapy会自动为我们处理cookie,只要我们登录成功了,它就会像一个浏览器一样自动传送cookie.
现在运行这个spider:scrapy crawl login
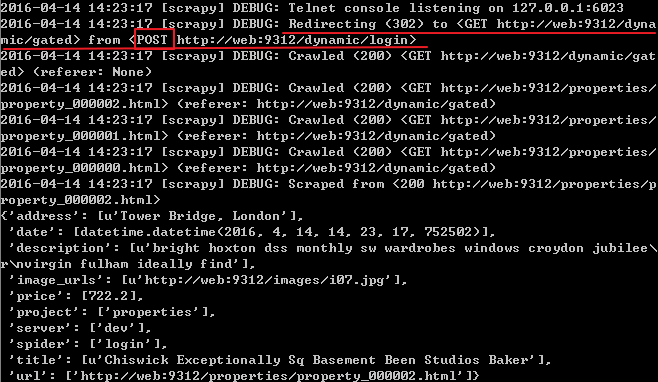
可以看到上面红线处首先向login页面提交了一个POST请求,然后重定向到了gated页面,再用一个GET请求得到了该页面,如果用错了用户名和密码,就会得到错误的结果

上面是一个极其简单的登录机制,大多数网站其实会使用更加复杂的登录机制,下面的这个例子就使用了隐藏数据
带有隐藏数据的登录
在浏览器打开页面:http://127.0.0.1:9312/dynamic/nonce,然后用调试器定位到登录按钮,可以看到如下界面
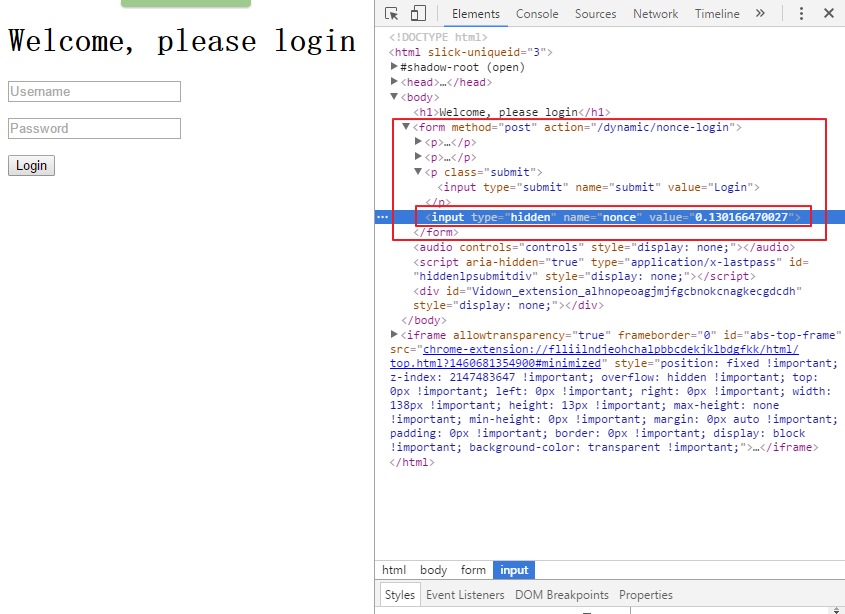
与第一个登录情况不同的是可以看到这个表单有一个叫做nonce的隐藏字段,当你按下Login按钮时,向服务器发送的数据包括用户名和密码,还有这个属性的值。你不可能猜到这个属性的值,因为这是一个一次性的随机数,这意味着你在Scrapy登录时需要两个发送两个请求,首先得到表单里的数据,然后再填充登录数据,Scrapy已经集成了这些功能。
noncelogin.py文件的源代码地址:
将之前的login.py文件复制为noncelogin.py文件,做如下改变:
导入Request:from scrapy.http import Request
将spider的名称修改为noncelogin
将start_request函数修改如下
#这个函数返回了一个Request,在这个Request中已经指定了回调函数为parse_welcome,所以会把response传送到parse_welcome函数上
def start_requests(self):
return [
Request("http://web:9312/dynamic/nonce",
callback=self.parse_welcome)
]
- 增加一个parse_welcome函数如下
#接收到了包含表单全部数据的response(此时用户名和密码都是空,但是已经获取到了隐藏字段nonce的值),然后填充用户名和密码再登录
def parse_welcome(self, response):
return FormRequest.from_response(
response,
formdata={"user": "user", "pass": "pass"}
)
运行该spider:scrapy crawl noncelogin
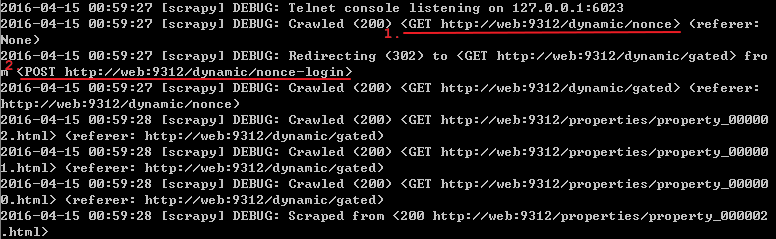
之前所说的登录过程发送了两个请求指的就是上面标记了顺序1和2的两个请求(一个GET,一个POST)
值得注意的是form_response函数
(http://doc.scrapy.org/en/1.0/topics/request-response.html#topics-request-response-ref-request-userlogin),这个函数值得仔细研究,如果在登录页面有多个表单,此时就要用参数来指定究竟把用户名和密码填充到哪个表单上,同时,函数也默认模拟了对登录按钮的点击行为,要是网站使用了javascript来控制登录,此时函数的默认点击行为就可能出错,通过设置dont_click为True来禁止模拟点击.
上面只是使用了两个步骤来登录,但在面对更加复杂的登录方式时就需要组织更多的步骤.
Learning Scrapy笔记(五)- Scrapy登录网站的更多相关文章
- Scrapy笔记12- 抓取动态网站
Scrapy笔记12- 抓取动态网站 前面我们介绍的都是去抓取静态的网站页面,也就是说我们打开某个链接,它的内容全部呈现出来. 但是如今的互联网大部分的web页面都是动态的,经常逛的网站例如京东.淘宝 ...
- 爬虫(十八):Scrapy框架(五) Scrapy通用爬虫
1. Scrapy通用爬虫 通过Scrapy,我们可以轻松地完成一个站点爬虫的编写.但如果抓取的站点量非常大,比如爬取各大媒体的新闻信息,多个Spider则可能包含很多重复代码. 如果我们将各个站点的 ...
- Learning Scrapy笔记(六)- Scrapy处理JSON API和AJAX页面
摘要:介绍了使用Scrapy处理JSON API和AJAX页面的方法 有时候,你会发现你要爬取的页面并不存在HTML源码,譬如,在浏览器打开http://localhost:9312/static/, ...
- Learning Scrapy笔记(零) - 前言
我已经使用了scrapy有半年之多,但是却一直都感觉没有入门,网上关于scrapy的文章简直少得可怜,而官网上的文档(http://doc.scrapy.org/en/1.0/index.html)对 ...
- Scrapy笔记11- 模拟登录
Scrapy笔记11- 模拟登录 有时候爬取网站的时候需要登录,在Scrapy中可以通过模拟登录保存cookie后再去爬取相应的页面.这里我通过登录github然后爬取自己的issue列表来演示下整个 ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- python网络爬虫之使用scrapy自动登录网站
前面曾经介绍过requests实现自动登录的方法.这里介绍下使用scrapy如何实现自动登录.还是以csdn网站为例. Scrapy使用FormRequest来登录并递交数据给服务器.只是带有额外的f ...
- Scrapy框架: 登录网站
一.使用cookies登录网站 import scrapy class LoginSpider(scrapy.Spider): name = 'login' allowed_domains = ['x ...
- Learning Scrapy笔记(三)- Scrapy基础
摘要:本文介绍了Scrapy的基础爬取流程,也是最重要的部分 Scrapy的爬取流程 Scrapy的爬取流程可以概括为一个方程式:UR2IM,其含义如下图所示 URL:Scrapy的运行就从那个你想要 ...
- scrapy笔记集合
细读http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 目录 Scrapy介绍 安装 基本命令 项目结构以及爬虫应用介绍 简单使用示例 选 ...
随机推荐
- Android 在程序中动态添加 View 布局或控件
有时我们需要在程序中动态添加布局或控件等,下面用程序来展示一下相应的方法: 1.addView 添加View到布局容器 2.removeView 在布局容器中删掉已有的View 3.LayoutPar ...
- 性能测试脚本新玩法---fiddler&&Jmeter
飞测说:最近接触移动项目,测试app,需要做移动app的性能测试,想通过代理来录制,但是jmeter的代理录制效果真心不是很好,自己一个个请求来写代码,太浪时间了,那么有没有其他的办法呢? 我们都知道 ...
- Android Studio实用快捷键汇总
以下是平时在Windwos系统上用Android Studio进行开发时常用到的一些快捷键,虽然不多,但是感觉都还蛮实用的,因此记录下来,如果什么时候不小心忘记了可以拿来翻一翻,That would ...
- TCP/IP详解学习笔记(13)-- TCP连接的建立与终止
1.TCP连接的建立 设主机B运行一个服务器进程,它先发出一个被动打开命令,告诉它的TCP要准备接收客户进程的连续请求,然后服务进程就处于听的状态.不断检测是否有客户进程发起连续 ...
- JS实现星级评分
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...
- 【Hibernate 5】继承映射配置及多态查询
一.继承实现的三种策略 1.1,单表继承.每棵类继承树使用一个表(table per class hierarchy) -->本文主要介绍的继承策略 类继承树对应多个类,要把多个类的信息存放在一 ...
- ionic 不同view的數據交互
angular中通過service factory 等服務來對不同的控制器進行數據交互 ,ionic 也一樣... var app = angular.module('ionicApp', ['ion ...
- java根据sessionid获取session
import java.util.HashMap; import java.util.Map; import javax.servlet.http.HttpSession; /** * * Class ...
- Could not resolve this reference. Could not locate the assembly
Rebuild Project 的时候提示找不到NewtonJson 组件,重新添加了Dll(Newtonsoft.Json.dll),依然抛错. 解决办法,将Dll(Newtonsoft.Json. ...
- WWF3状态机工作流<WWF第七篇>
状态机是另外一种常见的工作流类型.它是以状态的变迁为驱动而进行业务流转的,是一定需要人为干预的,而不像顺序类型工作流那样可以按照事先设计好的业务流程一步一步依次执行下去. 一.状态机工作流范例 Sta ...