DLA:动态层级注意力架构,实现特征图的持续动态刷新与交互 | IJCAI'24
论文深入探讨了层级注意力与一般注意力机制之间的区别,并指出现有的层级注意力方法是在静态特征图上实现层间交互的。这些静态层级注意力方法限制了层间上下文特征提取的能力。为了恢复注意力机制的动态上下文表示能力,提出了一种动态层级注意力(
DLA)架构。DLA包括双路径,其中前向路径利用一种改进的递归神经网络块用于上下文特征提取,称为动态共享单元(DSU),反向路径使用这些共享的上下文表示更新特征。最后,注意力机制应用于这些动态刷新后的层间特征图。实验结果表明,所提议的DLA架构在图像识别和目标检测任务中优于其他最先进的方法。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Strengthening Layer Interaction via Dynamic Layer Attention

Introduction
众多研究强调了增强深度卷积神经网络(DCNNs)中层级间交互的重要性,这些网络在各种任务中取得了显著进展。例如,ResNet通过在两个连续层之间引入跳跃连接,提供了一种简单而高效的实现方式。DenseNet通过回收来自所有前置层的信息,进一步改善了层间交互。与此同时,注意力机制在DCNNs中的作用越来越重要。注意力机制在DCNNs中的演变经历了多个阶段,包括通道注意力、空间注意力、分支注意力以及时空注意力。
最近,注意力机制已成功应用于另一个方向(例如,DIANet、RLANet、MRLA),这表明通过注意力机制增强层间交互是可行的。与ResNet和DenseNet中简单的交互方式相比,引入注意力机制使得层间交互变得更加紧密和有效。DIANet在网络的深度上采用了一个参数共享的LSTM模块,以促进层间交互。RLANet提出了一个层聚合结构,用于重用前置层的特征,从而增强层间交互。MRLA首次引入了层级注意力的概念,将每个特征视为一个标记,通过注意力机制从其他特征中学习有用的信息。
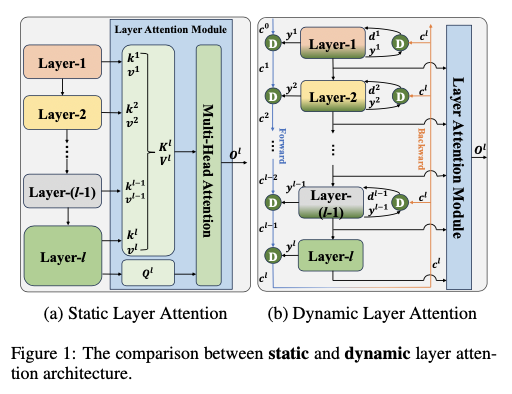
然而,论文发现现有的层级注意力机制存在一个共同的缺点:它们以静态方式应用,限制了层间信息交互。在通道和空间注意力中,对于输入 \(\boldsymbol{x} \in \mathbb{R}^{C \times H \times W}\) ,标记输入到注意力模块,所有这些标记都是从 \(\boldsymbol{x}\) 同时生成的。然而,在现有的层级注意力中,从不同时间生成的特征被视为标记并传入注意力模块,如图1(a)所示。由于早期生成的标记一旦产生就不会改变,因此输入的标记相对静态,这导致当前层与前置层之间的信息交互减少。
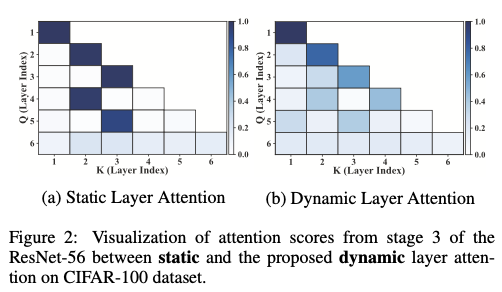
图2(a)可视化了在CIFAR-100上训练的ResNet-56的第3阶段的MRLA注意力分数。当前5层通过静态层级注意力重用来自前置层的信息时,只有一个特定层的关键值被激活,几乎没有其他层被分配注意力。这一观察验证了静态层级注意力削弱了层间信息交互的效率。
为了解决层级注意力的静态问题,论文提出了一种新颖的动态层级注意力(DLA)架构,以改善层间的信息流动,其中前置层的信息在特征交互过程中可以动态修改。如图2(b)所示,在重用前置层信息的过程中,当前特征的注意力从专注于某一特定层逐渐转变为融合来自不同层的信息。DLA促进了信息的更全面利用,提高了层间信息交互的效率。实验结果表明,所提的DLA架构在图像识别和目标检测任务中优于其他最先进的方法。
本文的贡献总结如下:
提出了一种新颖的
DLA架构,该架构包含双路径,其中前向路径使用递归神经网络(RNN)提取层间的上下文特征,而后向路径则利用这些共享的上下文表示在每一层刷新原始特征。提出了一种新颖的
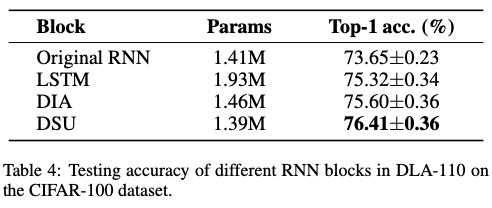
RNN模块,称为动态共享单元(DSU),它被设计为DLA的适用组件。它有效地促进了DLA内部信息的动态修改,并且在逐层信息集成方面表现出色。
Dynamic Layer Attention
首先重新审视当前的层级注意力架构并阐明其静态特性,随后再介绍动态层级注意力(DLA),最后将呈现一个增强型RNN插件模块,称为动态共享单元(DSU),它集成在DLA架构中。
Rethinking Layer Attention
层级注意力由MRLA定义,并如图1(a)所示,其中注意力机制增强了层级间的交互。MRLA致力于降低层级注意力的计算成本,提出了递归层级注意力(RLA)架构。在RLA中,来自不同层的特征被视为标记并进行计算,最终产生注意力输出。
设第 \(l\) 层的特征输出为 \(\boldsymbol{x}^l \in \mathbb{R}^{C \times W \times H}\) 。向量 \(\boldsymbol{Q}^l\) 、 \(\boldsymbol{K}^l\) 和 \(\boldsymbol{V}^l\) 可以按如下方式计算:
\left\{
\begin{aligned}
\boldsymbol{Q}^l &= f^l_q(\boldsymbol{x}^l)\\
\boldsymbol{K}^l &= \text{Concat}\left[f^1_k(\boldsymbol{x}^1), \ldots, f^l_k(\boldsymbol{x}^l)\right] \\
\boldsymbol{V}^l &= \text{Concat}\left[f^1_v(\boldsymbol{x}^1), \ldots, f^l_v(\boldsymbol{x}^l)\right],
\end{aligned}
\right.
\end{equation}
\]
其中 \(f_q\) 是一个映射函数,用于从第 \(l\) 层提取信息,而 \(f_k\) 和 \(f_v\) 是相应的映射函数,分别用于从第 \(1\) 层到第 \(l\) 层提取信息。注意力输出 \(\boldsymbol{o}^l\) 的计算公式如下:
\begin{aligned}
\boldsymbol{o}^l &= \text{Softmax}\left(\frac{\boldsymbol{Q}^l (\boldsymbol{K}^l)^\text{T}}{\sqrt{D_k}}\right) \boldsymbol{V}^l \\
&=\sum^l_{i=1} \text{Softmax}\left(\frac{\boldsymbol{Q}^l \left[f_k^i(\boldsymbol{x}^i)\right]^\text{T}}{\sqrt{D_k}}\right) f_v^i(\boldsymbol{x}^i),
\end{aligned}
\end{equation}
\]
其中 \(D_k\) 作为缩放因子。
为了降低计算成本,轻量级版本的RLA通过递归方式更新注意力输出 \(\boldsymbol{o}^l\) ,具体方法如下:
\boldsymbol{o}^l = \boldsymbol{\lambda}_o^l \odot \boldsymbol{o}^{l-1} + \text{Softmax}\left(\frac{\boldsymbol{Q}^l \left[f_k^l(\boldsymbol{x}^l)\right]^\text{T}}{\sqrt{D_k}}\right) f_v^l(\boldsymbol{x}^l),
\end{equation}
\]
其中 \(\boldsymbol{\lambda}^{l}_o\) 是一个可学习的向量, \(\odot\) 表示逐元素相乘。通过多头结构设计,引入了多头递归层级注意力(MRLA)。
Motivation
MRLA成功地将注意力机制整合进层间交互中,有效地解决了计算成本问题。然而,当MRLA应用于第 \(l\) 层时,前面 \(m\) 层 ( $ m<l $ ) 已经生成了特征输出 \(\boldsymbol{x}^m\) ,且没有后续变化。因此,MRLA处理的信息包括来自前几层的固定特征。相比之下,广泛使用的基于注意力的模型,如通道注意力、空间注意力和Transformers,都会将生成的标记同时传递到注意力模块中。将注意力模块应用于新生成的标记之间,可以确保每个标记始终学习到最新的特征。因此,论文将MRLA归类为静态层注意力机制,限制了当前层与较浅层之间的交互。
在一般的自注意力机制中,特征 \(\boldsymbol{x}^m\) 有两个作用:传递基本信息和表示上下文。当前层提取的基本信息使其与其他层区分开来。同时,上下文表示捕捉特征沿时间轴的变化和演变,这是决定特征新鲜度的关键方面。在一般的注意力机制中,每一层都会生成基本信息,而上下文表示会转移到下一层以计算注意力输出。相比之下,在层注意力中,一旦生成标记,就会用固定的上下文表示计算注意力,这降低了注意力机制的效率。因此,本文旨在建立一种新方法来恢复上下文表示,确保输入层注意力的信息始终保持动态。
Dynamic Layer Attention Architecture
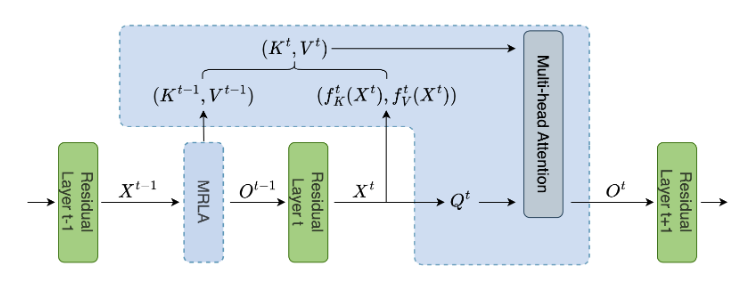
为了解决MRLA的静态问题,论文提出使用动态更新规则来提取上下文表示,并及时更新前面层的特征,从而形成了动态层注意力(DLA)架构。如图1(b) 所示,DLA包括两个路径:前向路径和后向路径。在前向路径中,采用递归神经网络(RNN)进行上下文特征提取。定义RNN块表示为Dyn,初始上下文表示为 \(\boldsymbol{c}^0\) ,其中 \(\boldsymbol{c}^0\) 被随机初始化。给定输入 \(\boldsymbol{x}^m \in \mathbb{R}^{ C\times W\times H}\) ,其中 \(m < l\) ,对 \(m\) 层应用全局平均池化(GAP)以提取全局特征,如下所示:
\boldsymbol{y}^m = \text{GAP}(\boldsymbol{x}^m),\ \boldsymbol{y}^m \in \mathbb{R}^{C}.
\end{equation}
\]
上下文表示的提取方式如下:
\boldsymbol{c}^m = \text{Dyn}(\boldsymbol{y}^m, \boldsymbol{c}^{m-1}; \theta^l).
\end{equation}
\]
其中, \(\theta^l\) 表示Dyn的共享可训练参数。一旦计算出上下文 \(\boldsymbol{c}^l\) ,每一层的特征将在后向路径中同时更新,如下所示:
\left\{
\begin{aligned}
\boldsymbol{d}^m &= \text{Dyn}(\boldsymbol{y}^m, \boldsymbol{c}^l; \theta^l)\\
\boldsymbol{x}^m &\leftarrow \boldsymbol{x}^m \odot \boldsymbol{d}^m
\end{aligned}\right.
\end{equation}
\]
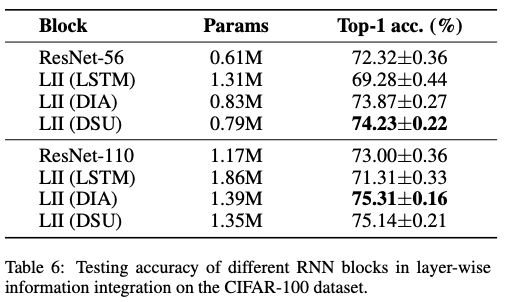
参考公式5,前向上下文特征提取是一个逐步过程,其计算复杂度为 \(\mathcal{O}(n)\) 。与此同时,公式6中的特征更新可以并行进行,计算复杂度为 \(\mathcal{O}(1)\) 。在更新 \(\boldsymbol{x}^m\) 后,DLA的基础版本使用公式2 来计算层注意力,简称DLA-B。对于DLA的轻量级版本,简单地更新 \(\boldsymbol{o}^{l-1}\) ,然后使用公式3来获得DLA-L。
Computation Efficiency
DLA在结构设计上具有几个优点:
- 全局信息被压缩以计算上下文信息,这一功能已经在
Dianet中得到验证。 DLA在RNN模块内使用了共享参数。- 上下文 \(\boldsymbol{c}^l\) 在每一层中以并行的方式单独输入到特征图中,前向和后向路径在整个网络中共享相同的参数并引入了一个高效的
RNN模块用于计算上下文表示。
通过这些高效设计的结构规则,计算成本和网络容量得到了保障。
Dynamic Sharing Unit
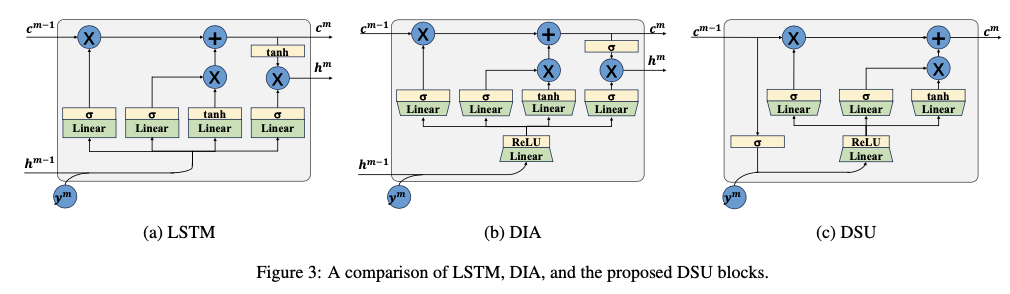
LSTM,如图3(a)所示,设计用于处理序列数据和学习时间特征,使其能够捕捉和存储长序列中的信息。然而,在将LSTM嵌入DLA作为递归块时,LSTM中的全连接线性变换显著增加了网络容量。为了缓解这种容量增加,Dianet提出了一种变体LSTM块,称为DIA单元,如图3(b)所示。在将数据输入网络之前,DIA首先利用线性变换和ReLU激活函数来降低输入维度。此外,DIA在输出层将Tanh函数替换为Sigmoid函数。
LSTM和DIA生成两个输出,包括一个隐藏向量 \(\boldsymbol{h}^m\) 和一个cell状态向量 \(\boldsymbol{c}^m\) 。通常, \(\boldsymbol{h}^m\) 用作输出向量,而 \(\boldsymbol{c}^m\) 作为记忆向量。DLA专注于从不同层中提取上下文特征,其中RNN模块不需要将其内部状态特征传递到外部。因此,论文舍弃了输出门,并通过省略 \(\boldsymbol{h}^m\) 来合并记忆向量和隐藏向量。
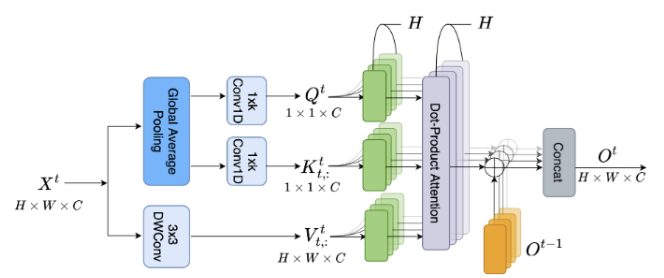
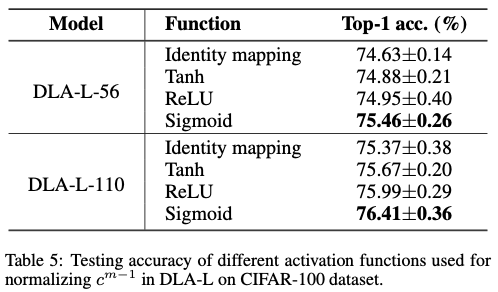
论文提出的简化RNN模块被称为动态共享单元(Dynamic Sharing Unit,DSU),工作流程如图3(c)所示。具体而言,在添加 \(\boldsymbol{c}^{m-1}\) 和 \(\boldsymbol{y}^m\) 之前,首先使用激活函数 \(\sigma(\cdot)\) 对 \(\boldsymbol{c}^{m-1}\) 进行归一化。在这里,选择Sigmoid函数 ( \(\sigma(z) = 1 /(1 + e^{-z})\) )。因此,DSU的输入被压缩如下:
\boldsymbol{s}^m = \text{ReLU}\left(\boldsymbol{W}_1\left[ \sigma(\boldsymbol{c}^{m-1}), \boldsymbol{y}^m \right] \right).
\end{equation}
\]
隐藏变换、输入门和遗忘门可以通过以下公式表示:
\left\{
\begin{aligned}
\boldsymbol{\tilde{c}}^m &= \text{Tanh}(\boldsymbol{W}_2^c \cdot \boldsymbol{s}^m + b^c) \\
\boldsymbol{i}^m &= \sigma(\boldsymbol{W}_2^i \cdot \boldsymbol{s}^m + b^i ) \\
\boldsymbol{f}^m &= \sigma(\boldsymbol{W}_2^f \cdot \boldsymbol{s}^m + b^f )
\end{aligned}
\right.
\end{equation}
\]
随后,得到
\boldsymbol{c}^m = \boldsymbol{f}^m \odot \boldsymbol{c}^{m-1} + \boldsymbol{i}^m \odot \boldsymbol{\tilde{c}}^m
\end{equation}
\]
为了减少网络参数,令 \(\boldsymbol{W}_1\in \mathbb{R}^{\frac{C}{r}\times 2C}\) 和 \(\boldsymbol{W}_2\in \mathbb{R}^{C\times \frac{C}{r}}\) ,其中 \(r\) 是缩减比率。DSU将参数减少到 \(5C^2/r\) ,比LSTM的 \(8C^2\) 和DIA的 \(10C^2/r\) 更少。
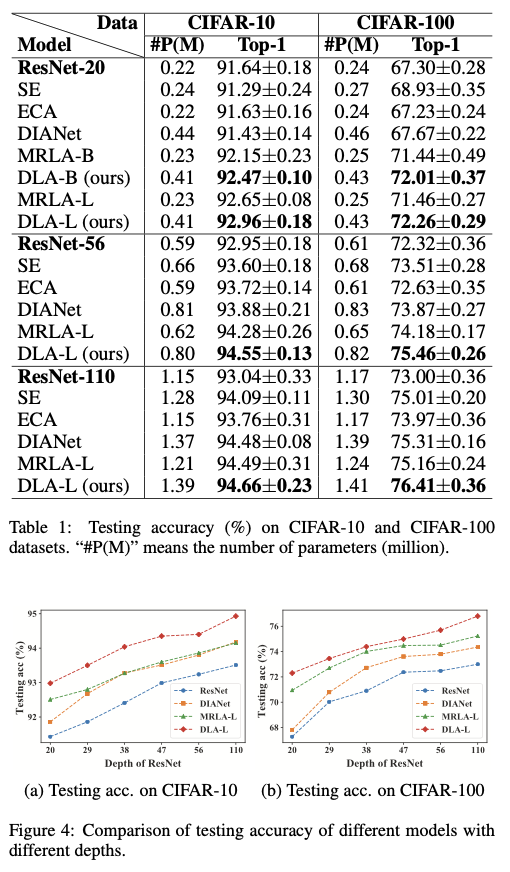
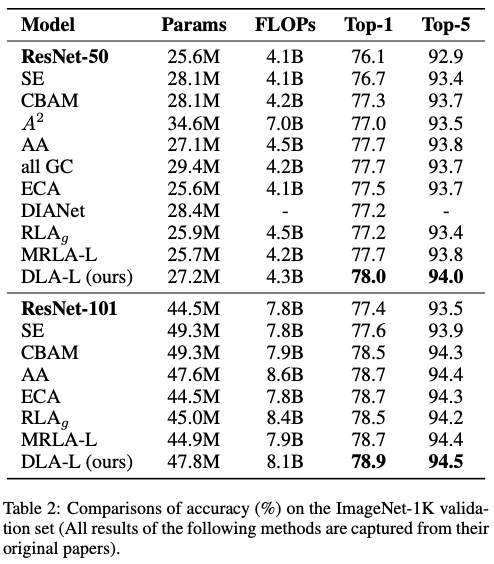
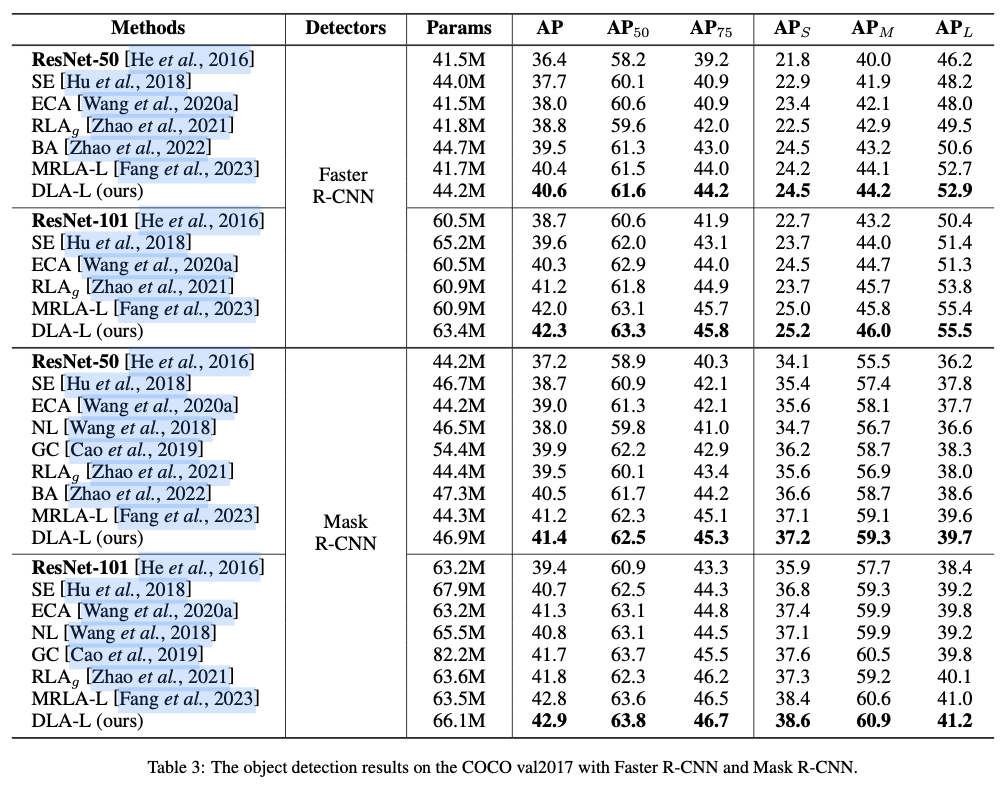
Experiments
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

DLA:动态层级注意力架构,实现特征图的持续动态刷新与交互 | IJCAI'24的更多相关文章
- Java生鲜电商平台-商城后台架构与原型图实战
Java生鲜电商平台-商城后台架构与原型图实战 说明:生鲜电商平台的运营平台,其中需要很多的功能进行管理.目前把架构与原型图实战分享给大家,希望对大家有用. 仪表盘/首页,简单统计,报表页,运营快捷口 ...
- 卷积神经网络特征图可视化(自定义网络和VGG网络)
借助Keras和Opencv实现的神经网络中间层特征图的可视化功能,方便我们研究CNN这个黑盒子里到发生了什么. 自定义网络特征可视化 代码: # coding: utf-8 from keras.m ...
- highcharts 动态生成x轴和折线图
highchart 动态生成x轴和折线图 <!DOCTYPE HTML> <html> <head> <meta charset="utf-8&qu ...
- Keras中间层输出的两种方式,即特征图可视化
训练好的模型,想要输入中间层的特征图,有两种方式: 1. 通过model.get_layer的方式.创建新的模型,输出为你要的层的名字. 创建模型,debug状态可以看到模型中,base_model/ ...
- 卷积网络中的通道(Channel)和特征图
转载自:https://www.jianshu.com/p/bf8749e15566 今天介绍卷积网络中一个很重要的概念,通道(Channel),也有叫特征图(feature map)的. 首先,之前 ...
- SLAM概念学习之特征图Feature Maps
特征图(或者叫地标图,landmark maps)利用参数化特征(如点和线)的全局位置来表示环境.如图1所示,机器人的外部环境被一些列参数化的特征,即二维坐标点表示.这些静态的地标点被观测器(装有传感 ...
- 深度学习之加载VGG19模型获取特征图
1.加载VGG19获取图片特征图 # coding = utf-8 import tensorflow as tf import numpy as np import matplotlib.pyplo ...
- tensroflow中如何计算特征图的输出及padding大小
根据tensorflow中的conv2d函数,我们先定义几个基本符号 1.输入矩阵 W×W,这里只考虑输入宽高相等的情况,如果不相等,推导方法一样,不多解释. 2.filter矩阵 F×F,卷积核 3 ...
- GhostNet: 使用简单的线性变换生成特征图,超越MobileNetV3的轻量级网络 | CVPR 2020
为了减少神经网络的计算消耗,论文提出Ghost模块来构建高效的网络结果.该模块将原始的卷积层分成两部分,先使用更少的卷积核来生成少量内在特征图,然后通过简单的线性变化操作来进一步高效地生成ghost特 ...
- Latex向上\向下取整语法 及卷积特征图高宽计算公式编辑
向下\向上取整 在编辑卷积网络输出特征高宽公式时,需用到向下取整,Mark一下. 向下取整 \(\lfloor x \rfloor\) $\lfloor x \rfloor$ 向上取整 \(\lcei ...
随机推荐
- 二分查找 | C++
以此题为例:P2249 [深基13.例1]查找 二分查找 对于一个单调不降的序列 \(S\),传统查找的复杂度是 \(O(|S|)\),即 \(O(n)\). 有时候序列 \(S\) 中的元素特别多, ...
- Vue 打包后自定义样式无法覆盖elementUI组件原有样式问题
Vue 打包后自定义样式无法覆盖elementUI组件原有样式问题 by:授客 QQ:1033553122 开发环境 Win 10 node-v10.15.3-x64.msi 下载地址 ...
- python中的字符串和列表
name="1" name='1' name="""1""""" name='''1''' #都为正 ...
- Python报错:WARNING conda.models.version:get_matcher(542): Using .* with relational operator is superfluous and deprecated and will be removed in a future version of conda.
参考: https://blog.csdn.net/weixin_45685859/article/details/132916216 报错: [23:59:14](pytorch) devil@OM ...
- DophinScheduler 如何定期删除日志实例?
转载自东华果汁哥 Apache DophinScheduler 运行一段时间后,实例调度日志越来越多,需要定期清理. SQL 错误 [1701] [42000]: Cannot truncate a ...
- 安装RabbitMQ遇到的一些坑
Ubantu18.0正确安装RabbitMQ 1.安装erlang 因为RabbitMQ需要erlang语言的支持,所以我们需要先安装erlang. sudo apt-get install erla ...
- 运维 + AI,你得先搞懂这些
很感谢夜莺提供如此优质的平台能和行业内顶尖技术大佬做面对面的交流,在这个会议中又学习到了很多有趣有深度的内容,给我在未来探索的道路上提供了一些新的指引方向.同时感谢夜莺社区的邀请,在此再做一次关于AI ...
- 不同浏览器input file样式不一样
在开发项目过程中会碰到不同浏览器input file样式不一样. 经过分析,打算都用IE上面的附件上传样式, 方案如下: 1.在IE下截个如上面的上传按钮,并保存. 2.判断浏览器类型,如果是非IE ...
- JavaScript 的优雅编程技巧:Singleton Pattern
JavaScript 的优雅编程技巧:Singleton Pattern 定义 单例模式:保证一个类仅有一个实例,并提供一个访问的全局访问点. 特点 仅有一个实例对象 全局都可访问该实例 主动实例化 ...
- 全网最适合入门的面向对象编程教程:38 Python常用复合数据类型-使用列表实现堆栈、队列和双端队列
全网最适合入门的面向对象编程教程:38 Python 常用复合数据类型-使用列表实现堆栈.队列和双端队列 摘要: 在 Python 中,列表(list)是一种非常灵活的数据结构,可以用来实现堆栈(st ...