第八篇 编写spider爬取jobbole的所有文章
通过scrapy的Request和parse,我们能很容易的爬取所有列表页的文章信息。
PS:parse.urljoin(response.url,post_url)的方法有个好处,如果post_url是完整的域名,则不会拼接response.url的主域名,如果不是完整的,则会进行拼接
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
#这个是python3中的叫法,python2中是直接import urlparse
from urllib import parse class JobboleSpider(scrapy.Spider):
# 爬虫名字
name = 'jobbole'
# 运行爬取的域名
allowed_domains = ['blog.jobbole.com']
# 开始爬取的URL
start_urls = ['http://blog.jobbole.com/tag/linux/']
#start_urls = ['https://javbooks.com/content_censored/169018.htm'] def parse(self,response):
"""
获取文章列表页url
:param response:
:return:
"""
blog_url = response.css(".floated-thumb .post-meta .read-more a::attr(href)").extract()
for post_url in blog_url:
#scrapy内置了根据url来调用“页面爬取模块”的方法Resquest,入参有访问的url和回调函数
yield Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail)
#由于伯乐在线的文章列表页里的href的域名是全称”http://blog.jobbole.com/112535/“
#但存在href只记录112535的情况,这时候需要拼接出完整的url,可以使用urllib库的parse函数
#Request(url=parse.urljoin(response.url,post_url),callback=self.parse_detail)
print(post_url)
#下一页url
next_url = response.css(".next.page-numbers::attr(href)").extract_first()
if next_url:
yield Request(url=parse.urljoin(response.url,next_url),callback=self.parse) def parse_detail(self, response):
"""
获取文章详情页
:param response:
:return:
"""
ret_str = response.xpath('//*[@class="dht_dl_date_content"]')
title = response.css("div.entry-header h1::text").extract_first()
create_date = response.css("p.entry-meta-hide-on-mobile::text").extract_first().strip().replace("·", "").strip()
content = response.xpath("//*[@id='post-112239']/div[3]/div[3]/p[1]")
Items
主要目标是从非结构化来源(通常是网页)提取结构化数据。Scrapy爬虫可以将提取的数据作为Python语句返回。虽然方便和熟悉,Python dicts缺乏结构:很容易在字段名称中输入错误或返回不一致的数据,特别是在与许多爬虫的大项目。
要定义公共输出数据格式,Scrapy提供Item类。 Item对象是用于收集所抓取的数据的简单容器。它们提供了一个类似字典的 API,具有用于声明其可用字段的方便的语法。
各种Scrapy组件使用项目提供的额外信息:导出器查看声明的字段以计算要导出的列,序列化可以使用项字段元数据trackref 定制,跟踪项实例以帮助查找内存泄漏(请参阅使用trackref调试内存泄漏)等。
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class ArticlespiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass class JoBoleArticleItem(scrapy.Item):
#标题
title = scrapy.Field()
#创建日期
create_date = scrapy.Field()
#文章url
url = scrapy.Field()
#url是长度不定的,可以转换成固定长度的md5
url_object_id = scrapy.Field()
#图片url
front_image_url = scrapy.Field()
#图片路径url
front_image_path = scrapy.Field()
#点赞数
praise_num = scrapy.Field()
#评论数
comment_num = scrapy.Field()
#收藏数
fav_num = scrapy.Field()
#标签
tags = scrapy.Field()
#内容
content = scrapy.Field()
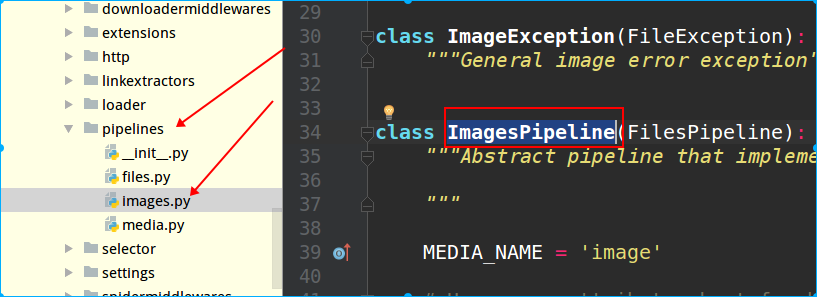
scrapy内置了文件下载、图片下载等方法,可以通过scrapy源码文件查看有哪些:
PS:scrapy存储数据的配置文件是在project目录下的pipelines.py中,而查看内置了哪些下载的类,也在源码的pipelines目录里,如下图所示:
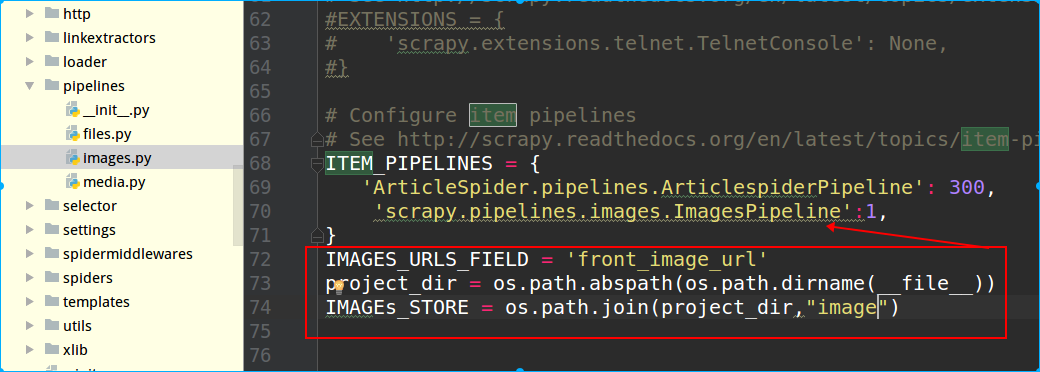
接着在settings.py里配置,在ITEM_PIPELINES字典里配置上这个类,这个字典是scrapy自带的,默认在settings里是注释掉的,后面的数字表示优先级,数值越小,调用时优先级越高。接着配置图片的Item字段
IMAGES_URLS_FIELD = 'front_image_url'
IMAGES_URLS_FIELD是固定写法,front_image_url是item名称
IMAGEs_STORE指定图片存放路径
PS:python保存图片时,需要先安装一个库:pillow
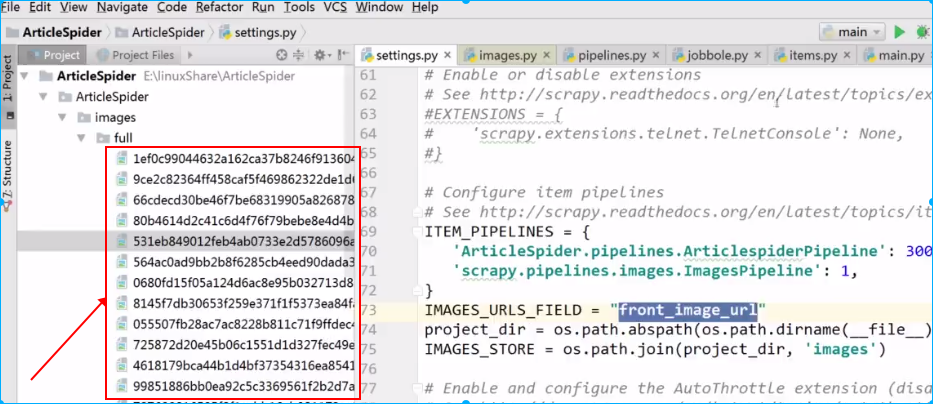
上面的图片保存下来后,发现scrapy会自动给图片命名,如果不想使用这种名称,比如想使用文章的路径名,那可以在pipeline.py文件里进行自定义。
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.pipelines.images import ImagesPipeline class ArticlespiderPipeline(object):
def process_item(self, item, spider):
return item #进行图片下载定制,可以通过继承scrapy内置的imagespipeline来重载某些功能
class ArticleImagePipeline(ImagesPipeline):
#通过查看ImagesPipeline类可以了解是由下面这方法图片命名
def item_completed(self, results, item, info):
pass
上面这个item_completed方法是ImagePipeline里的,这里我们需要对它进行重载,但是关于里面的入参,可以通过pycharm的debug调试查看:
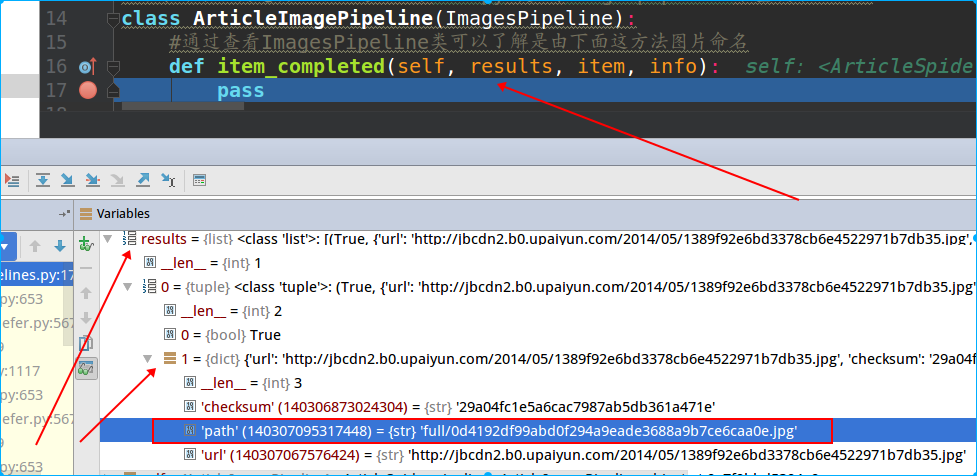
可以看到result是个是个tuple,第一个值是返回状态,第二个是个嵌套dict,其中path是我们想要的。
#进行图片下载定制,可以通过继承scrapy内置的imagespipeline来重载某些功能
class ArticleImagePipeline(ImagesPipeline):
#通过查看ImagesPipeline类可以了解是由下面这方法图片命名
def item_completed(self, results, item, info):
for ok,value in results:
image_file_path = value['path']
item['front_image_url'] = image_file_path
return item
再接着,是把url名称进行md5加密,这样可以让url变成一个唯一的且长度固定的值
可以在项目里单独创建个目录,用来存放这些函数:
# -*- conding:utf-8 -*- import hashlib
def get_md5(url):
if isinstance(url,str):
url = url.encode("utf-8")
m = hashlib.md5()
m.update(url)
return m.hexdigest() if __name__ == "__main__":
print(get_md5("www.baidu.com"))
结果:
dab19e82e1f9a681ee73346d3e7a575e
然后调用这个函数存到item里就行:
article_item["url_object_id"] =get_md5(response.url)
第八篇 编写spider爬取jobbole的所有文章的更多相关文章
- step5: 编写spider爬取
改写parse函数 实现功能: 1.获取文章列表页中的文章url并交给scrapy下载后,交给解析函数进行具体字段的解析2.获取下一页的url并交给scrapy进行下载,下载完成后交给parse 提取 ...
- 爬虫实战——Scrapy爬取伯乐在线所有文章
Scrapy简单介绍及爬取伯乐在线所有文章 一.简说安装相关环境及依赖包 1.安装Python(2或3都行,我这里用的是3) 2.虚拟环境搭建: 依赖包:virtualenv,virtualenvwr ...
- 爬取博主所有文章并保存到本地(.txt版)--python3.6
闲话: 一位前辈告诉我大学期间要好好维护自己的博客,在博客园发布很好,但是自己最好也保留一个备份. 正好最近在学习python,刚刚从py2转到py3,还有点不是很习惯,正想着多练习,于是萌生了这个想 ...
- Node爬取简书首页文章
Node爬取简书首页文章 博主刚学node,打算写个爬虫练练手,这次的爬虫目标是简书的首页文章 流程分析 使用superagent发送http请求到服务端,获取HTML文本 用cheerio解析获得的 ...
- 使用Python爬取微信公众号文章并保存为PDF文件(解决图片不显示的问题)
前言 第一次写博客,主要内容是爬取微信公众号的文章,将文章以PDF格式保存在本地. 爬取微信公众号文章(使用wechatsogou) 1.安装 pip install wechatsogou --up ...
- 洗礼灵魂,修炼python(67)--爬虫篇—cookielib之爬取需要账户登录验证的网站
学完前面的教程,相信你已经能爬取大部分的网站信息了,但是当你爬的网站多了,你应该会发现一个新问题,有的网站需要登录账户才能看到更多的信息对吧?那么这种网站怎么爬取呢?这些登录数据就是今天要说的——co ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- 兴奋与沮丧并存spider爬取拉勾网
兴奋的开发除了爬取拉勾网的爬虫信息,可是当调试都成功了的那一刻,我被拉钩封IP了. 下面是spider的主要内容 import reimport scrapy from bs4 import Beau ...
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
随机推荐
- Mybatis中#{}与${}的使用
含义 #{}:为占位符 ${}:为拼接符 区别: 用法 #{}:为参数占位符?,即sql预编译 ${}为字符串替换, 即字符串拼接 执行流程 #{}:动态解析 --> 预编译 - ...
- 【模板】fread读入优化 & fwrite输出优化
#include <iostream> #include <cstdio> #include <cctype> #define SIZE (1 << 2 ...
- window下eclipse搭建hadoop环境
1 生成插件jar 1.1 安装java,ant运行环境 1.2 下载hadoop-2.5.0.tar.gz并解压到指定目录 1.3 下载hadoop2x-eclipse-plugin-master. ...
- 【Movie】绿皮书
今天和室友一起去看了<绿皮书>,一部获得奥斯卡的电影. 起初我是没什么太大期望的,纯粹是因为特价票10块钱,加上身边一个小姐姐的力荐. 看完我觉得,啊不愧是奥斯卡电影啊.推荐. 以下可能会 ...
- css 深入理解
场景一.边框半透明,背景绿色 默认情况下背景会延伸到边框所在的下边 css2 中我们只能接受 css3 中我们可以通过 background-clip 属性来实现 border: 10px soli ...
- 2018-8-10-win10-uwp-DataContext-
title author date CreateTime categories win10 uwp DataContext lindexi 2018-08-10 19:16:53 +0800 2018 ...
- Codeforces 346D Robot Control DP spfa 01BFS
题意及思路:https://www.cnblogs.com/zjp-shadow/p/9562888.html 这题由于性质特殊,可以用01BFS来进行DP的转移. 代码: #include < ...
- 在AndroidStudio2.3.2下JNI开发的详细步骤(转)
转自:http://blog.csdn.net/luhaoying1111/article/details/72468867 安装NDK 在工具栏点击File->Settings->App ...
- vue中key的作用
1.v-if中用key管理可复用的元素 Vue 会尽可能高效地渲染元素,通常会复用已有元素而不是从头开始渲染.这么做,除了使 Vue 变得非常快之外,还有一些有用的好处.例如,如果你允许用户在不同的 ...
- loj2573[TJOI2018]数字计算
题意:操作1:x=x*m,输出x%mod.2.x/=map[m].m即第m次操作,保证该次操作为1操作,并且每个操作最多只会被删一次.q<=1e5. 线段树维护操作信息的乘积,删除把对应位置的权 ...