手把手视频:万能开源Hawk抓取动态网站
Hawk是沙漠之鹰历时五年开发的开源免费网页抓取工具(爬虫),无需编程,全部可视化。
自从上次发布Hawk 2.0过了小半年,可是还是有不少朋友通过邮件或者微信的方式询问如何使用。看文档还是不如视频教学方便,沙漠君决定录播几段视频来帮助大家~
软件最新的下载地址(或点击原文)

下面是视频内容,在腾讯视频可以开启高清,实测清晰度尚可,当然你也可以在百度云盘中下载以下全部视频。
http://pan.baidu.com/s/1dE5D40h
1. 使用Hawk抓取百度百家新闻
这是抓取百度百家新闻(http://baijia.baidu.com/)完整的例子,你可以了解到:
- 如何抓取动态页面和超级模式
- 如何获取网页正文信息
- 如何导出抓取的数据
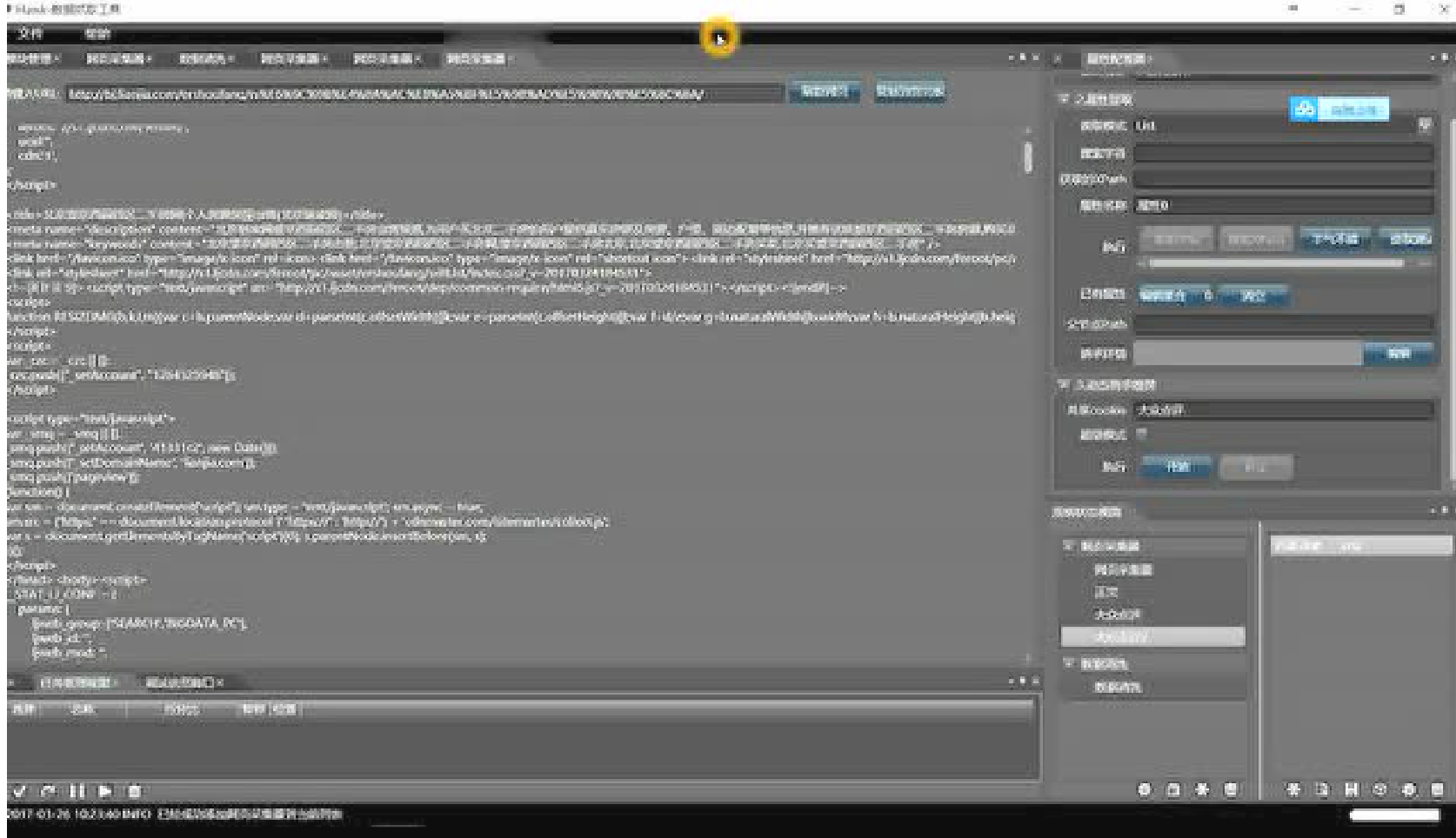
内置的播放器无法调节清晰度。可在PC访问:
2. Hawk答疑
这是一个综述,对大家感兴趣的话题答疑解惑,包括:
- 如何使用手气不错(相比1.0版本优化很多)
- 文档在哪里?
- 如何连接数据库
- 其他一些使用上的问题
可在PC访问:
3. 历史视频
这些视频都是针对1.0在2016年上半年录制的,由于网站改版,或增加了防爬虫(如链家),因此在使用上会有较大区别,仅供各位用户参考。
抓取链家(目前链家防爬虫非常严格,视频仅供参考)
大众点评(没想到播放量高达8.3W)
获取最近地铁站(Hawk的功能可不局限于爬虫)
4. 如何下载工程案例
Hawk本身提供了一系列例子(虽然基本都是2016年上半年的),不少已经过期了。
有些朋友直接用“右键另存为”下载,这样保存的是html页面,有两种方法可以下载:
如果你会用git, 在shell里直接执行
git clone git@github.com:ferventdesert/Hawk-Projects.git
手动下载整个文件夹: 在首页上Download ZIP
4. 欢迎共同改进Hawk
为什么要重提再度改进Hawk呢?
- 高不成低不就: 因为如果一件好用的工具分数是0.8的话,Hawk正好在0.74,因为一些其实很简单的问题,用户就卡在那里无从下手。
- 可用性/UI设计急需提高: 特别需要懂产品/UI的朋友一起协助
- 软件依然有不少bugs
- etlpy(Python版本的Hawk)开发虽完成,但有相当陡峭的学习曲线
万里长征走了9500里,却在最后的一段路上止步不前,给世人留下一个半吊子,终究是不好的。所以2017年一个重要的任务便是进一步完善它,走完剩下的500里。
因此,如果你对Hawk,爬虫或是软件设计感兴趣的话,可以考虑和沙漠君一起改进它。只要你有任何靠谱的建议,都可以告诉我,我会集中起来一起改进。也许你可能获得不了什么经济上的补偿(沙漠君也没有),但总比网络上各种野路子收费软件强很多。我们做了一件能帮助几十万甚至百万人的事情。
虽然工作非常忙,因此各种回复不及时,不过有任何问题依然可以给我发邮件:
最后祝使用Hawk愉快!
手把手视频:万能开源Hawk抓取动态网站的更多相关文章
- 【转】详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等)
转自:http://www.crifan.com/files/doc/docbook/web_scrape_emulate_login/release/html/web_scrape_emulate_ ...
- 使用scrapy-selenium, chrome-headless抓取动态网页
在使用scrapy抓取网页时, 如果遇到使用js动态渲染的页面, 将无法提取到在浏览器中看到的内容. 针对这个问题scrapy官方给出的方案是scrapy-selenium, 这是一个把sel ...
- scrapy和selenium结合抓取动态网页
1.安装python (我用的是2.7版本的) 2.安装scrapy: 详情请参考 http://blog.csdn.net/wukaibo1986/article/details/8167590 ...
- java抓取动态生成的网页
最近在做项目的时候有一个需求:从网页面抓取数据,要求是首先抓取整个网页的html源码(后期更新要使用到).刚开始一看这个简单,然后就稀里哗啦的敲起了代码(在这之前使用过Hadoop平台的分布式爬虫框架 ...
- python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ .此网页中的最新.精华下面的内容是由JavaScript动态生成的.审查网页元素与网页 ...
- selenium抓取动态网页数据
1.selenium抓取动态网页数据基础介绍 1.1 什么是AJAX AJAX(Asynchronouse JavaScript And XML:异步JavaScript和XML)通过在后台与服务器进 ...
- 用php实现一个简单的爬虫,抓取电影网站的视频下载地址
昨天没什么事,先看一下电影,就用php写了一个爬虫在视频网站上进行视频下载地址的抓取,这里总结一下抓取过程中遇到的问题 1:通过访问浏览器来执行php脚本这种访问方式其实并不适合用来爬网页,因为要受到 ...
- scrapy-splash抓取动态数据例子八
一.介绍 本例子用scrapy-splash抓取界面网站给定关键字抓取咨询信息. 给定关键字:个性化:融合:电视 抓取信息内如下: 1.资讯标题 2.资讯链接 3.资讯时间 4.资讯来源 二.网站信息 ...
- Scrapy笔记12- 抓取动态网站
Scrapy笔记12- 抓取动态网站 前面我们介绍的都是去抓取静态的网站页面,也就是说我们打开某个链接,它的内容全部呈现出来. 但是如今的互联网大部分的web页面都是动态的,经常逛的网站例如京东.淘宝 ...
随机推荐
- 用Javascript大批量收集网站数据
最近为了写论文,要大批量收集慕课网的相关用户数据(因为用户个人主页是公开的),故而写了一个插件进行收集.需要在慕课网控制台输入.最后收集了3000多份数据. /* 收集项 收集标准 用户编号 慕课网用 ...
- java poi 从服务器下载模板写入数据再导出
最近写了一个,Excel 的 写入和导出. 需求是这样的. 在新建合同的时候,会有导出合同的数据, 导出的模板是固定的,,需要在模板里面写入合同的信息. first : 下载模板 ...
- NSTimer定时器进阶——详细介绍,循环引用分析与解决
引言 定时器:A timer waits until a certain time interval has elapsed and then fires, sending a specified m ...
- 用css实现3D立方体旋转特效
先来看运行后出来的效果 它是在不停运行的一个立方体 先来看html部分的代码 <div class="rect-wrap"> <!--舞台元素,设置perspec ...
- php 实现购物车功能,以大苹果购物网为例,上图上代码。。。。
首先是几个简单的登录页面 <body> <form action="chuli.php" method="post"> <div ...
- HTML 5入门知识(五)
本地存储Web Storage 使用HTML 5的Web Storage功能,可以在客户端存储更多的数据,而且可以实现数据在多个页面中共享甚至是同步. cookie存储数据的不足 cookie可用于在 ...
- wemall app微信商城系统Android之通用通知接口demo
wemall-mobile是基于WeMall的Android app商城,只需要在原商城目录下上传接口文件即可完成服务端的配置,客户端可定制修改.本文分享Native(原生)支付模式一demo,供技术 ...
- MySQL相关信息(二)
1.修改MySQL提示符 (1)连接客户端时通过参数指定 shell>mysql -u root -p --prompt 提示符 C:\Users\Administrator>mysql ...
- MyBatis极速入门开发手册(2017-2-6更新)
前言: 本篇文章对我的学习内容做一个归纳梳理,同时也记录一些学习过程中遇上的问题及注意事项等等,可以帮助新入门的朋友们消除一些误区与盲区,希望能帮上一些正在学习的朋友们.在编写时会引用一些mybati ...
- java操作txt文本(二):删除文本括号内的内容
想法由来:之前写读书报告时,遇到一些烦人的文献,总喜欢把注释作为括号内容放到正文中,使文章繁琐冗长,所以写了下面这个代码,剔除了括号内的内容. 适用条件:原txt文本中的括号使用正确,即左右括号匹配正 ...