Linear Regression with PyTorch
Linear Regression with PyTorch
Problem Description
初始化一组数据 \((x,y)\),使其满足这样的线性关系 \(y = w x + b\) 。然后基于反向传播法,用均方误差(mean squared error)
\]
去拟合这组数据。
衡量两个分布之间的距离,最直接的方法是用交叉熵。
我们用最简单的一元变量去拟合这组数据,其实一元线性回归的表达式 \(y = wx + b\) 用神经网络的形式可表示成如下图所示
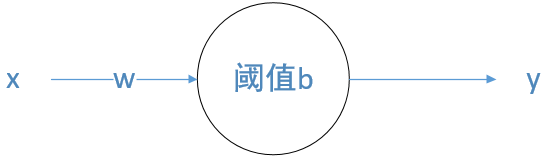
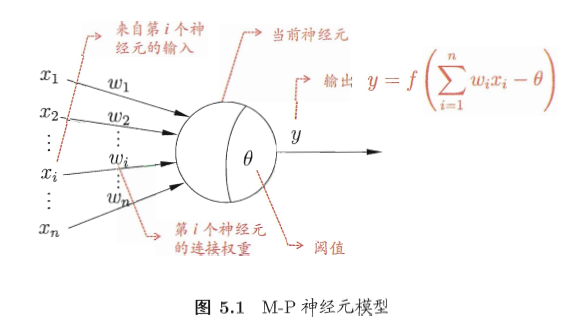
该神经网络有一个输入、一个输出、不使用任何激活函数。这就是一元线性回归的神经网络表示结果。相比较于下图这种神经网络的形式化表示,上图是一种简单的特例。
Key Points
torch.unsqueeze
重塑一个张量的 size,见下面代码
>>> x = torch.tensor([1, 2, 3, 4])
>>> torch.unsqueeze(x, 0)
tensor([[ 1, 2, 3, 4]])
>>> torch.unsqueeze(x, 1)
tensor([[ 1],
[ 2],
[ 3],
[ 4]])
torch.linspace
得到一个在 start 和 end 之间等距的一维张量,见下面代码
>>> torch.linspace(1, 6, steps=3)
tensor([ 1.0000, 3.5000, 6.0000])
torch.rand
返回一个满足 size 维度要求的随机数组,随机数服从0-1均匀分布。
torch.nn.Linear(1,1)
self.prediction = torch.nn.Linear(1, 1)
这一行代码,实际是维护了两个变量,其描述了这样的一种关系:
\]
其中,每个参数都是 \(1\times1\) 维的。
Code
import torch
epoch = 10000
lr = 0.01
w = 10
b = 5
x = torch.unsqueeze(torch.linspace(1, 10, 20), 1)
y = w*x + b + torch.rand(x.size())
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.prediction = torch.nn.Linear(1, 1)
def forward(self, x):
out = self.prediction(x)
return out
net = Net()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
criticism = torch.nn.MSELoss()
for i in range(epoch):
y_pred = net(x)
loss = criticism(y_pred, y) # 先是 y_pred 然后是 y_true 参数顺序不能乱
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("%.5f" % loss.data)
print(net.state_dict()['prediction.weight'])
print(net.state_dict()['prediction.bias'])
输出:
0.08882
tensor([[ 9.9713]])
tensor([ 5.6524])
Results Analysis
输出显示:
- 均方误差(MSE)为 0.0882
- \(weight\) 的拟合结果为 9.9713
- \(bias\) 的拟合结果为 5.6524
分析:
- 因为我主动引入了误差(服从0-1均匀分布),而且是线性拟合,所以 MSE 几乎不能减小到零;
- 9.9713 的拟合值已经非常接近真实值 10 了;5.6524 的拟合值较真实值 5 的距离较大(距离约为自身的 10%)
Linear Regression with PyTorch的更多相关文章
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- 局部加权回归、欠拟合、过拟合(Locally Weighted Linear Regression、Underfitting、Overfitting)
欠拟合.过拟合 如下图中三个拟合模型.第一个是一个线性模型,对训练数据拟合不够好,损失函数取值较大.如图中第二个模型,如果我们在线性模型上加一个新特征项,拟合结果就会好一些.图中第三个是一个包含5阶多 ...
- Multivariance Linear Regression练习
%% 方法一:梯度下降法 x = load('E:\workstation\data\ex3x.dat'); y = load('E:\workstation\data\ex3y.dat'); x = ...
- Kernel Methods (3) Kernel Linear Regression
Linear Regression 线性回归应该算得上是最简单的一种机器学习算法了吧. 它的问题定义为: 给定训练数据集\(D\), 由\(m\)个二元组\(x_i, y_i\)组成, 其中: \(x ...
- Linear regression with multiple variables(多特征的线型回归)算法实例_梯度下降解法(Gradient DesentMulti)以及正规方程解法(Normal Equation)
,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, , ...
- Linear regression with one variable算法实例讲解(绘制图像,cost_Function ,Gradient Desent, 拟合曲线, 轮廓图绘制)_矩阵操作
%测试数据 'ex1data1.txt', 第一列为 population of City in 10,000s, 第二列为 Profit in $10,000s 1 6.1101,17.592 5. ...
- Matlab实现线性回归和逻辑回归: Linear Regression & Logistic Regression
原文:http://blog.csdn.net/abcjennifer/article/details/7732417 本文为Maching Learning 栏目补充内容,为上几章中所提到单参数线性 ...
- Stanford机器学习---第二讲. 多变量线性回归 Linear Regression with multiple variable
原文:http://blog.csdn.net/abcjennifer/article/details/7700772 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Stanford机器学习---第一讲. Linear Regression with one variable
原文:http://blog.csdn.net/abcjennifer/article/details/7691571 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
随机推荐
- 利用TensorFlow实现多元线性回归
利用TensorFlow实现多元线性回归,代码如下: # -*- coding:utf-8 -*- import tensorflow as tf import numpy as np from sk ...
- 还是Go 为了伟大的未来
今天,还是想讲讲Go 我觉得还没讲够,哈哈哈 其实,是想把框架再清晰些,因为上一篇框架没能引入goroutine(协程),感觉比较遗憾 下边,我就用上goroutine,但这里的协程仅是为了演示,没有 ...
- IdentityServer4:Endpoint
Endpoint的概念在IdentityServer里其实就是一些资源操作的url地址:如同Restful API里面的Endpoint是概念: 那么可以通过你自己的授权服务端得到相对应的地址与信息: ...
- 获取 Google USB 驱动程序
获取 Google USB 驱动程序 另请参阅 安装 USB 驱动程序 使用硬件设备 使用任何 Google Nexus 设备进行 ADB 调试时,只有 Windows 需要 Google ...
- LocalStorage存储和cookie存储
localStorage是H5的新特性,主要用来本地存储,一般浏览器支持的大小是5M,不同浏览器会有所不同,解决了cookie存储空间不足的问题. 2.使用: ⑴.存 if(!window.l ...
- 002-一般处理程序(HttpHandler)
一般处理程序(HttpHandler):是一个实现System.Web.IHttpHandler接口的特殊类.任何一个实现了IHttpHandler接口的类,是作为一个外部请求的目标程序的前提.(凡是 ...
- CRUD简单查询
一.查询所有数据 select * from car 二.查询指定列 select code , price from car 三.修改查询出的列名 select code as '代号' , nam ...
- 20171130-2-python orm
https://www.cnblogs.com/pycode/p/mysql-orm.html https://www.cnblogs.com/Hiberniane/archive/2011/01/3 ...
- DX9 顶点缓存案例
// @time 2012.3.5 // @author jadeshu //包含头文件 #include <Windows.h> #include <d3d9.h> #pra ...
- VMWare虚拟机 window文件传递
无论是将虚拟机的文件传到window上或者是将window上文件传到虚拟机上: 都可以选中文件,然后拖动文件到另一个系统上 提前:虚拟机安装了VMWARE Tools 1)window上文件拖到虚拟机 ...