keras 文本分类 LSTM
首先,对需要导入的库进行导入,读入数据后,用jieba来进行中文分词
# encoding: utf-8 #载入接下来分析用的库
import pandas as pd
import numpy as np
import xgboost as xgb
from tqdm import tqdm
from sklearn.svm import SVC
from keras.models import Sequential
from keras.layers.recurrent import LSTM, GRU
from keras.layers.core import Dense, Activation, Dropout
from keras.layers.embeddings import Embedding
from keras.layers.normalization import BatchNormalization
from keras.utils import np_utils
from sklearn import preprocessing, decomposition, model_selection, metrics, pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.decomposition import TruncatedSVD
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.naive_bayes import MultinomialNB
from keras.layers import GlobalMaxPooling1D, Conv1D, MaxPooling1D, Flatten, Bidirectional, SpatialDropout1D
from keras.preprocessing import sequence, text
from keras.callbacks import EarlyStopping
from nltk import word_tokenize text = pd.read_csv('./competeDataForA.csv',sep = '\t', encoding ='utf-8')
test = pd.read_csv('./evaluationDataForA.csv',sep = '\t', encoding ='utf-8')
# print(text['id'].head())
# print(text['ocr'].head())
# print(text['label'].head()) print (text.info()) print (text.label.unique()) import jieba
# jieba.enable_parallel() #并行分词开启
text['文本分词'] = text['ocr'].apply(lambda i:jieba.cut(i) )
text['文本分词'] =[' '.join(i) for i in text['文本分词']] test['文本分词'] = test['ocr'].apply(lambda i:jieba.cut(i) )
test['文本分词'] =[' '.join(i) for i in test['文本分词']] print (text.head()) lbl_enc = preprocessing.LabelEncoder()
y = lbl_enc.fit_transform(text.label.values) xtrain, xvalid, ytrain, yvalid = train_test_split(text.文本分词.values, y,
stratify=y,
random_state=42,
test_size=0.1, shuffle=True)
print (xtrain.shape)
print (xvalid.shape) xtest = test.文本分词.values X=text['文本分词'] X=[i.split() for i in X]
X[:2]
然后调用Keras对文本进行序列化:
设置最大长度为500,多余值填0;
# ################## LSTM 尝试 ##############################
# # 使用 keras tokenizer
from keras.preprocessing import sequence, text
token = text.Tokenizer(num_words=None)
max_len = 500 token.fit_on_texts(list(xtrain) + list(xvalid))
xtrain_seq = token.texts_to_sequences(xtrain)
xvalid_seq = token.texts_to_sequences(xvalid)
xtest_seq = token.texts_to_sequences(xtest) #对文本序列进行zero填充
xtrain_pad = sequence.pad_sequences(xtrain_seq, maxlen=max_len)
xvalid_pad = sequence.pad_sequences(xvalid_seq, maxlen=max_len)
xtest_pad = sequence.pad_sequences(xtest_seq, maxlen=max_len) word_index = token.word_index
import gensim model = gensim.models.Word2Vec(X,min_count =5,window =8,size=100) # X是经分词后的文本构成的list,也就是tokens的列表的列表
embeddings_index = dict(zip(model.wv.index2word, model.wv.vectors)) print('Found %s word vectors.' % len(embeddings_index)) print (len(word_index))
embedding_matrix = np.zeros((len(word_index) + 1, 100))
for word, i in tqdm(word_index.items()):
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
# 基于前面训练的Word2vec词向量,使用1个两层的LSTM模型
ytrain_enc = np_utils.to_categorical(ytrain)
yvalid_enc = np_utils.to_categorical(yvalid) model = Sequential()
model.add(Embedding(len(word_index) + 1,
100,
weights=[embedding_matrix],
input_length=max_len,
trainable=False))
model.add(SpatialDropout1D(0.3))
model.add(LSTM(100, dropout=0.3, recurrent_dropout=0.3)) model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.8)) model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.8)) model.add(Dense(2))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam') #在模型拟合时,使用early stopping这个回调函数(Callback Function)
earlystop = EarlyStopping(monitor='val_loss', min_delta=0, patience=3, verbose=0, mode='auto')
model.fit(xtrain_pad, y=ytrain_enc, batch_size=512, epochs=35,
verbose=1, validation_data=(xvalid_pad, yvalid_enc), callbacks=[earlystop]) pred_lstm_2 = model.predict_classes(xtest_pad)
pred_lstm_2 = pd.DataFrame(pred_lstm_2)
pred_lstm_2_res = pd.concat([test['id'],pred_lstm_2], axis=1)
pred_lstm_2_res.rename(columns={0:'label'},inplace=True)
pred_lstm_2_res.to_csv('pred_lstm_2_res.csv',sep = ',', index = False, encoding = 'utf-8')
LSTM有三种dropout:
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2))
第一个dropout是x和hidden之间的dropout,第二个是hidden-hidden之间的dropout
第三个是层-层之间的dropout
model.add(Embedding(top_words, embedding_vecor_length, input_length=max_review_length))
model.add(Dropout(0.2))
model.add(LSTM(100))
model.add(Dropout(0.2))
Keras分词器Tokenizer
0. 前言
Tokenizer是一个用于向量化文本,或将文本转换为序列(即单个字词以及对应下标构成的列表,从1算起)的类。是用来文本预处理的第一步:分词。结合简单形象的例子会更加好理解些。
1. 语法
官方语法如下1:
Code.1.1 分词器Tokenizer语法
keras.preprocessing.text.Tokenizer(num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~\t\n',
lower=True,
split=" ",
char_level=False)
1.1 构造参数
num_words:默认是None处理所有字词,但是如果设置成一个整数,那么最后返回的是最常见的、出现频率最高的num_words个字词。
filters:过滤一些特殊字符,默认上文的写法就可以了。
lower:全部转为小写
split:字符串,单词的分隔符,如空格
1.2 返回值
字符串列表
1.3 类方法
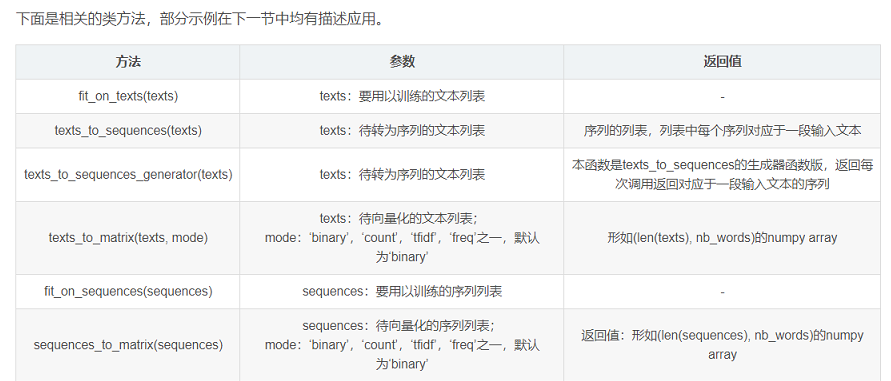
下面是相关的类方法,部分示例在下一节中均有描述应用。
1.4 属性
- document_count 处理的文档数量
- word_index 一个dict,保存所有word对应的编号id,从1开始
- word_counts 一个dict,保存每个word在所有文档中出现的次数
- word_docs 一个dict,保存每个word出现的文档的数量
- index_docs 一个dict,保存word的id出现的文档的数量
- word_counts:字典,将单词(字符串)映射为它们在训练期间出现的次数。仅在调用fit_on_texts之后设置。
- word_docs: 字典,将单词(字符串)映射为它们在训练期间所出现的文档或文本的数量。仅在调用fit_on_texts之后设置。
- word_index: 字典,将单词(字符串)映射为它们的排名或者索引。仅在调用fit_on_texts之后设置。
- document_count: 整数。分词器被训练的文档(文本或者序列)数量。仅在调用fit_on_texts或fit_on_sequences之后设置。
2. 简单示例
Code.2.1 简单示例
>>>from keras.preprocessing.text import Tokenizer
Using TensorFlow backend. # 创建分词器 Tokenizer 对象
>>>tokenizer = Tokenizer() # text
>>>text = ["今天 北京 下 雨 了", "我 今天 加班"] # fit_on_texts 方法
>>>tokenizer.fit_on_texts(text) # word_counts属性
>>>tokenizer.word_counts
OrderedDict([('今天', 2),
('北京', 1),
('下', 1),
('雨', 1),
('了', 2),
('我', 1),
('加班', 1)]) # word_docs属性
>>>tokenizer.word_docs
defaultdict(int, {'下': 1, '北京': 1, '今天': 2, '雨': 1, '了': 2, '我': 1, '加班': 1}) # word_index属性
>>>tokenizer.word_index
{'今天': 1, '了': 2, '北京': 3, '下': 4, '雨': 5, '我': 6, '加班': 7} # document_count属性
>>>tokenizer.document_count
2
3. 常用示例
还以上面的tokenizer对象为基础,经常会使用texts_to_sequences()方法 和 序列预处理方法 keras.preprocessing.sequence.pad_sequences一起使用
有关pad_sequences用法见python函数——序列预处理pad_sequences()序列填充
Code.3.1 常用示例
>>>tokenizer.texts_to_sequences(["下 雨 我 加班"])
[[4, 5, 6, 7]] >>>keras.preprocessing.sequence.pad_sequences(tokenizer.texts_to_sequences(["下 雨 我 加班"]), maxlen=20)
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 4, 5, 6, 7]],dtype=int32)
Keras基本使用方法:
https://blog.csdn.net/qq_41185868/article/details/84067803
Python中利用LSTM模型进行时间序列预测分析
http://www.cnblogs.com/arkenstone/p/5794063.html
参考:https://blog.csdn.net/wcy23580/article/details/84885734
https://zhuanlan.zhihu.com/p/50657430
keras 文本分类 LSTM的更多相关文章
- 文本分类:Keras+RNN vs传统机器学习
摘要:本文通过Keras实现了一个RNN文本分类学习的案例,并详细介绍了循环神经网络原理知识及与机器学习对比. 本文分享自华为云社区<基于Keras+RNN的文本分类vs基于传统机器学习的文本分 ...
- Keras lstm 文本分类示例
#基于IMDB数据集的简单文本分类任务 #一层embedding层+一层lstm层+一层全连接层 #基于Keras 2.1.1 Tensorflow 1.4.0 代码: '''Trains an LS ...
- [深度应用]·Keras实现Self-Attention文本分类(机器如何读懂人心)
[深度应用]·Keras实现Self-Attention文本分类(机器如何读懂人心) 配合阅读: [深度概念]·Attention机制概念学习笔记 [TensorFlow深度学习深入]实战三·分别使用 ...
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- 文本分类实战(七)—— Adversarial LSTM模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- tensorflow实现基于LSTM的文本分类方法
tensorflow实现基于LSTM的文本分类方法 作者:u010223750 引言 学习一段时间的tensor flow之后,想找个项目试试手,然后想起了之前在看Theano教程中的一个文本分类的实 ...
- 一文详解如何用 TensorFlow 实现基于 LSTM 的文本分类(附源码)
雷锋网按:本文作者陆池,原文载于作者个人博客,雷锋网已获授权. 引言 学习一段时间的tensor flow之后,想找个项目试试手,然后想起了之前在看Theano教程中的一个文本分类的实例,这个星期就用 ...
- 基于keras中IMDB的文本分类 demo
本次demo主题是使用keras对IMDB影评进行文本分类: import tensorflow as tf from tensorflow import keras import numpy a ...
- 基于深度学习的文本分类案例:使用LSTM进行情绪分类
Sentiment classification using LSTM 在这个笔记本中,我们将使用LSTM架构在电影评论数据集上训练一个模型来预测评论的情绪.首先,让我们看看什么是LSTM? LSTM ...
随机推荐
- C语言 提取double的每一位
#include<stdio.h> int main() { double x = 256.141592654; ; //整数部分 while(n) //整数部分输出 { ; n /= ; ...
- 类 __new__方法实现单例
继承了单例的类,子类也是单例模式
- 《Gradle权威指南》--Gradle任务
No1: 多种方式创建任务 def Task ex41CreateTask1 = task(ex41CreateTask1) ex41CreateTask1.doLast{ println " ...
- 015.Linux系统删根数据恢复
重要声明: 本文档所有思路来自于誉天教育,由本人(木二)在实验环境验证通过: 您应当通过誉天邹老师或本人提供的其他授权通道下载.获取本文档,且仅能用于自身的合法合规的业务活动: 本文档的内容仅供学习交 ...
- Spring框架学习10——JDBC Template 实现数据库操作
为了简化持久化操作,Spring在JDBC API之上提供了JDBC Template组件. 1.添加依赖 添加Spring核心依赖,MySQL驱动 <!--Spring核心基础依赖--> ...
- VUE3.0升级与配置(跨域、全局scss变量等)
1.检查本机vue版本 vue -V 2.升级vue3.0命令 npm install -g @vue/cli 3.创建完项目后,在项目根目录新增vue.config.js文件,插入代码(简洁) mo ...
- Linux笔记 rm -rf 嘻嘻
学习目标:常用linux命令的使用 JAVAEE :后台应用都会涉及到linux系统,应用程序的部署,运维,分布式集群,大数据,云计算 虚拟机:虚拟出来的计算机 虚拟机软件:用来产生虚拟机的一个软件 ...
- 如何成为java高手
成为Java高手是每个Java学习者的梦想,但目前Java知识分支众多,我们该如何学习?本文介绍成为Java高手需要注意的25个学习目标,希望对正在成为Java高手的您有所帮助. 1.你需要精通面向对 ...
- 洛谷 P2574 XOR的艺术(线段树 区间异或 区间求和)
To 洛谷.2574 XOR的艺术 题目描述 AKN觉得第一题太水了,不屑于写第一题,所以他又玩起了新的游戏.在游戏中,他发现,这个游戏的伤害计算有一个规律,规律如下 1. 拥有一个伤害串为长度为n的 ...
- swoole深入学习 3. upd Server和udp Client
前面主要讲了tcp得server和client的业务处理,tcp有三次握手,有连接的概览,而UDP服务器与TCP服务器不同,UDP没有连接的概念.启动Server后,客户端无需Connect,直接可以 ...