DensePose: Dense Human Pose Estimation In The Wild(理解)
0 - 背景
Facebook AI Research(FAIR)开源了一项将2D的RGB图像的所有人体像素实时映射到3D模型的技术(DensePose)。支持户外和穿着宽松衣服的对象识别,支持多人同时识别,并且实时性良好。
本研究的目的是通过建立从人体的2D图像到基于表面的3D表征的密集对应(dense correspondence)来进一步推进机器对图像的理解。该任务涉及到其他一些问题,如物体检测、姿态估计、作为特例或前提的部位和实例分割。在图形处理、增强现实或者人机交互等不只需要平面关键特征位置标记的问题中,这一任务的解决将能够实现很多应用,并还能助力实现通用型的基于3D的物体理解。
1 - 贡献
- 通过收集SMPL模型和COCO数据集中的人体外观之间的密对应对应而为该任务引入第一个人工收集的真实数据集(利用3D表面信息的全新标注流程实现)
- 通过在任何图像像素对人体表面坐标进行回归,我们使用所得到的数据集训练了可以得到自然环境中密集对应的基于CNN的系统(全卷积网络、mask R-CNN、级联)
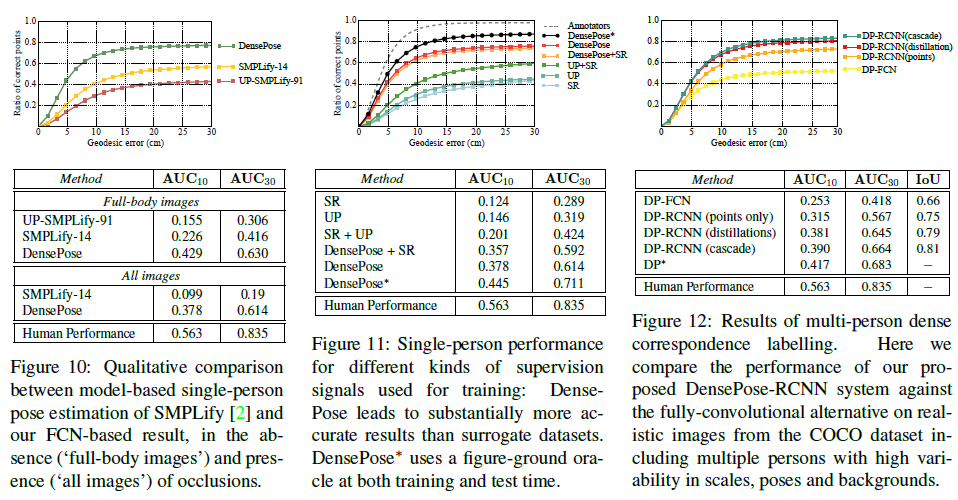
- 我们探索了利用我们构建的真实信息的不同方法,我们使用了在每个训练样本中随机选择的图像像素子集上定义的稀疏监督信号来训练一个教师网络(“teacher”),可以修补图像其余区域的监督信号
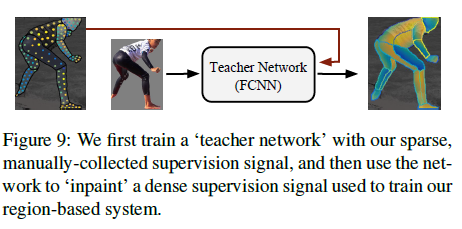
2 - 思路
采用一种全面的监督学习方法并收集了人体的图像与详细准确的参数表面模型之间的真实对应数据。
2.1 - 标注数据集
对于一般的姿态识别(骨骼追踪),能够识别出一二十个点便可以构成一个人体姿态,但如果要构造出一个平滑的3D模型,则需要更多的关键点,DensePose需要336个(24个部位,每个部位14个点)。
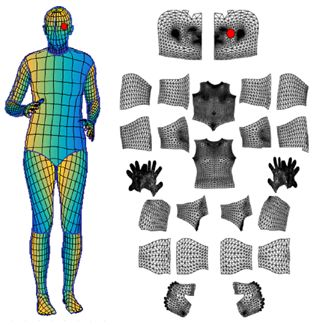


同时要求注释者在标记的时候要标出被衣物掩盖住的部位,比如宽松的裙子。

上述工作进行之后,研究人员对每一个展开部位区域进行采样,会获得6个不同视角的标记图,提供二维坐标图使标记者更直观的判断哪个标记是正确的。

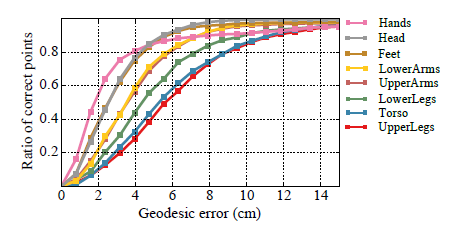
最后将平面重新组合成3D模型,进行最后一步校准。这样下来,可以以高效准确的方式获得准确标记的数据集。各部位错误率如下,可以看到在躯干、背部和臀部存在较大误差。
2.2 - 模型
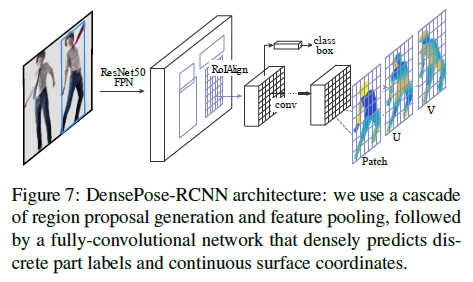
2.2.1 - Fully-convolutional dense pose regression

2.2.2 - Region-based Dense Pose Regression

2.3 - 效果
3 - 参考资料
https://mp.ofweek.com/3dprint/a045673622216
http://www.sohu.com/a/222047678_129720
DensePose: Dense Human Pose Estimation In The Wild(理解)的更多相关文章
- 对DensePose: Dense Human Pose Estimation In The Wild的理解
研究方法 通过完全卷积学习从图像像素到密集模板网格的映射.将此任务作为一个回归问题,并利用手动注释的面部标注来训练我们的网络.使用这样的标注,在三维对象模板和输入图像之间,建立密集的对应领域,然后作为 ...
- (转)Awesome Human Pose Estimation
Awesome Human Pose Estimation 2018-10-08 11:02:35 Copied from: https://github.com/cbsudux/awesome-hu ...
- 论文阅读理解 - Stacked Hourglass Networks for Human Pose Estimation
http://blog.csdn.net/zziahgf/article/details/72732220 keywords 人体姿态估计 Human Pose Estimation 给定单张RGB图 ...
- Towards Accurate Multi-person Pose Estimation in the Wild 论文阅读
论文概况 论文名:Towards Accurate Multi-person Pose Estimation in the Wild 作者(第一作者)及单位:George Papandreou, 谷歌 ...
- 论文笔记 Stacked Hourglass Networks for Human Pose Estimation
Stacked Hourglass Networks for Human Pose Estimation key words:人体姿态估计 Human Pose Estimation 给定单张RGB ...
- Deep High-Resolution Representation Learning for Human Pose Estimation
Deep High-Resolution Representation Learning for Human Pose Estimation 2019-08-30 22:05:59 Paper: CV ...
- Learning Feature Pyramids for Human Pose Estimation(理解)
0 - 背景 人体姿态识别是计算机视觉的基础的具有挑战性的任务,其中对于身体部位的尺度变化性是存在的一个显著挑战.虽然金字塔方法广泛应用于解决此类问题,但该方法还是没有很好的被探索,我们设计了一个Py ...
- human pose estimation
2D Pose estimation主要面临的困难:遮挡.复杂背景.光照.真实世界的复杂姿态.人的尺度不一.拍摄角度不固定等. 单人姿态估计 传统方法:基于Pictorial Structures, ...
- paper 154:姿态估计(Hand Pose Estimation)相关总结
Awesome Works !!!! Table of Contents Conference Papers 2017 ICCV 2017 CVPR 2017 Others 2016 ECCV 20 ...
随机推荐
- EF Core 遇到“可能会导致循环或多重级联路径”
在ef core中你可能会设计这样一个实体: public class Customer : Entity,IMustHaveTenant, IHasCreationTime { public Cus ...
- 检测web界面不能访问后重启
检测并重启脚本:checkAndRestart.sh #!/bin/bash nowpath=$(cd ")";pwd) source $nowpath/omcparam.prop ...
- Java Scanner用法详解
一.Scanner类简介 Java 5添加了java.util.Scanner类,这是一个用于扫描输入文本的新的实用程序.它是以前的StringTokenizer和Matcher类之间的某种结合.由于 ...
- 一本通 1223:An Easy Problem
\[传送门qwq\] [题目描述] 给定一个正整数N,求最小的.比N大的正整数M,使得M与N的二进制表示中有相同数目的1. 举个例子,假如给定的N为78,其二进制表示为1001110,包含4个1,那么 ...
- iOS开发基础-九宫格坐标(5)
继续在iOS开发基础-九宫格坐标(4)的基础上进行优化. 一.改进思路 1)iOS开发基础-九宫格坐标(4)中 viewDidLoad 方法中的第21.22行对控件属性的设置能否拿到视图类 WJQAp ...
- Django rest framework 源码分析 (1)----认证
一.基础 django 2.0官方文档 https://docs.djangoproject.com/en/2.0/ 安装 pip3 install djangorestframework 假如我们想 ...
- 《Effective C++》继承与面对对象设计:条款32-条款40
条款32:确定你的public继承塑模出is-a关系 public继承意味着is-a.适用于base class身上的每一个函数也一定适用于derived class. 条款33:避免遮掩继承而来的名 ...
- SQLiteOpenHelper+ContentProvider的使用
效果图: PetDbHelper package com.example.admin.pets; import android.content.Context;import android.datab ...
- c语言第三次课
一.const的使用1)const声明变量为只读 ; a = ; //error ] = "abcdef"; const char *p = buf; char const *p ...
- css3 box-shadow阴影(外阴影与外发光)讲解
基础说明: 外阴影:box-shadow: X轴 Y轴 Rpx color; 属性说明(顺序依次对应): 阴影的X轴(可以使用负值) 阴影的Y轴(可以使用负值) 阴影 ...