python requests模拟登陆正方教务管理系统,并爬取成绩
最近模拟带账号登陆,查看了一些他人的博客,发现正方教务已经更新了,所以只能自己探索了。
登陆:
通过抓包,发现需要提交的值
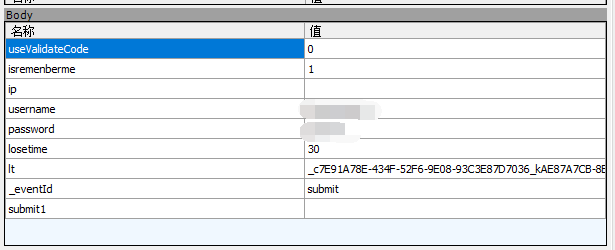
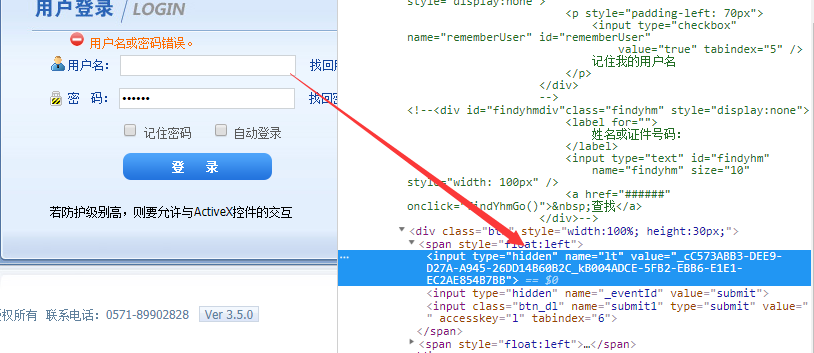
需要值lt,这是个啥,其实他在访问登陆页面时就产生了
session=requests.Session()
response = session.get(login_url, headers=header)
cookies = response.cookies
for c in cookies:
cookie = c.name + '=' + c.value
print('cookie-get:' + cookie)
selector = etree.HTML(response.text)
token = selector.xpath('//input[@name="lt"]/@value')[] # 解析出登陆所需的lt信息
print(token)
得到lt的值,加入到自己创建的表单中
根据上面抓包工具中需要的值,创建所需表单
login_data={
'useValidateCode': '',
'isremenberme': '',
'ip':'',
'username': username,
'password': password,
'losetime': '',
'lt': token,
'_eventId': 'submit',
'submit1':''
}
post请求登陆:
response = session.post(login_url, data=login_data, headers=header) print(response.status_code)
我们成功了,哈哈哈,很开心!

进入了主页面:
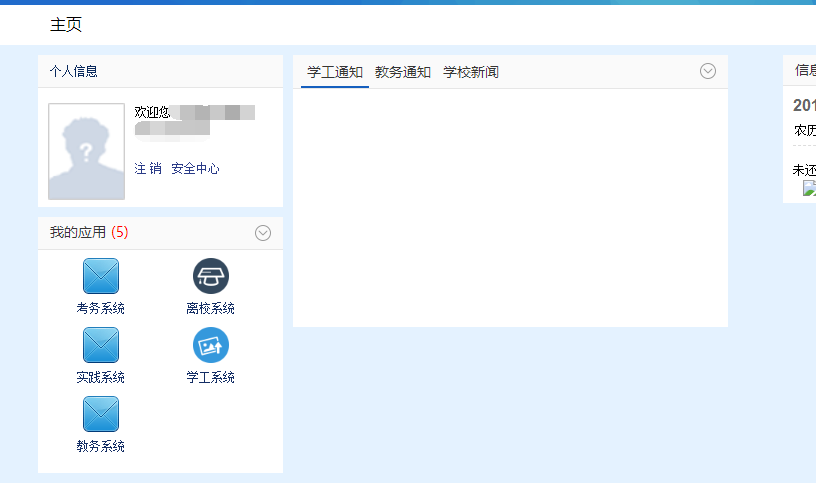
这是我们登进的页面,要爬取成绩,成绩在教务系统中,细心观察
get下链接:http://******/xs_main.aspx?xh=***&type=1
response = session.get(main_url, headers=header)
print(response.cookies)
print(response.status_code)
print(BeautifulSoup(response.text, 'lxml'))
response.status_code返回200,以为成功了?打印一下

额!难受,鬼刀一开,看不见........他竟然返回的是登陆界面?
究竟是什么问题呢,我怀疑是cookie:
因为
print(response.cookies)打印的值是: <RequestsCookieJar[]>
浏览器访问抓包看下
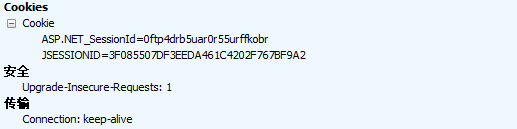
啊嘞嘞,why?
查看其他请求,在Cookie中竟然都没有创建过ASP.NET_SessionID
那怎么办呢?
那我自己写一个吧:
requests.utils.add_dict_to_cookiejar(session.cookies,{"ASP.NET_SessionId":"0ftp4drb5uar0r55urffkobr"})
哎呀,成功了。开心,不过似乎ASP.NET_SessionId有时效性。
不管了,也不知道为啥Session.Cookies得不到所需要的Cookie,先不管了,各位大佬,发现问题的话,或者有啥好的解决办法麻烦告诉下!拜谢
代码地址:https://github.com/JackyWjx/HNCU下的HNCU.py
****************************************第二次更新********************************************************************************************************************************* 这个做法有问题呀:所以:我又来了。。。
经过学习cookie,意识到自己以前的一些错误,特来改正:
上篇对于ASP.NET_SessionId值不知道如何解决,只能自己添加
解决原理:既然ASP.NET_SessionId是一个cookie值,那么有一个请求的作用就是服务器设置ASP.NET_SessionId给浏览器,那么我们就直接拿到这个请求不就迎刃而解了
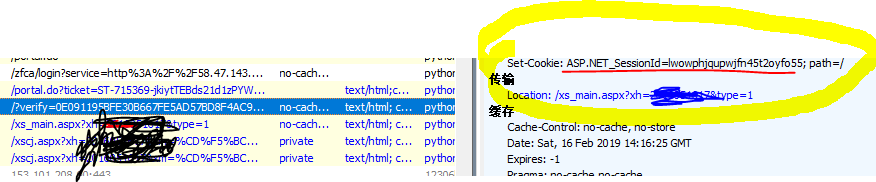
请求就知道了,那么请求这个请求就解决了,有由于我们的项目使用的requests那么也不需要设置啥了
代码地址:
https://github.com/JackyWjx/HNCU 下的HNCU-neW.py
python requests模拟登陆正方教务管理系统,并爬取成绩的更多相关文章
- python+requests模拟登陆 学校选课系统
最近学校让我们选课,每天都有不同的课需要选....然后突发奇想试试用python爬学校选课系统的课程信息 先把自己的浏览器缓存清空,然后在登陆界面按f12 如图: 可以看到登陆时候是需要验证码的,验证 ...
- python requests 模拟登陆网站,抓取数据
抓取页面数据的时候,有时候我们需要登陆才可以获取页面资源,那么我们需要登陆以后才可以跳转到对应的资源页面,那么我们需要通过模拟登陆,登陆成功以后再次去抓取对应的数据. 首先我们需要通过手动方式来登陆一 ...
- 【小白学爬虫连载(10)】–如何用Python实现模拟登陆网站
Python如何实现模拟登陆爬取Python实现模拟登陆的方式简单来说有三种:一.采用post请求提交表单的方式实现.二.利用浏览器登陆网站记录登陆成功后的cookies,采用get的请求方式,传入c ...
- python爬虫模拟登陆
python爬虫模拟登陆 学习了:https://www.cnblogs.com/chenxiaohan/p/7654667.html 用的这个 学习了:https://www.cnblogs.co ...
- Python脚本模拟登陆DVWA
目录 requests模拟登陆 Selenium自动化测试登陆 环境:python3.7 windows requests模拟登陆 我们登陆DVWA的时候,看似只有一步:访问网站,输入用户名和密码,登 ...
- Python requests模拟登录
Python requests模拟登录 #!/usr/bin/env python # encoding: UTF-8 import json import requests # 跟urllib,ur ...
- Python实现模拟登陆
大家经常会用Python进行数据挖掘的说,但是有些网站是需要登陆才能看到内容的,那怎么用Python实现模拟登陆呢?其实网路上关于这方面的描述很多,不过前些日子遇到了一个需要cookie才能登陆的网站 ...
- Requests模拟登陆
requests模拟登陆知乎网站 实例 # -*- coding: utf-8 -*- __author__ = 'CQ' import requests try: import cookielib ...
- python网络爬虫之解析网页的BeautifulSoup(爬取电影图片)[三]
目录 前言 一.BeautifulSoup的基本语法 二.爬取网页图片 扩展学习 后记 前言 本章同样是解析一个网页的结构信息 在上章内容中(python网络爬虫之解析网页的正则表达式(爬取4k动漫图 ...
随机推荐
- Spring MVC 使用介绍(十六)数据验证 (三)分组、自定义、跨参数、其他
一.概述 除了依赖注入.方法参数,Bean Validation 1.1定义的功能还包括: 1.分组验证 2.自定义验证规则 3.类级别验证 4.跨参数验证 5.组合多个验证注解 6.其他 二.分组验 ...
- 思维导图读PMbok第6版 - 项目整合管理(21张全讲)
“ 3个月,800多页书,一大堆工作,复习时间不够呀?老师用思维导图解析PMP,思维导图解析PMP梳理PMbok第6版逻辑结构,帮你您全局掌握PMP知识,重点掌握PMbok难点.快速记忆PMP知识,思 ...
- Windows10搭建FTP服务
1.启用Windows10 Ftp服务 打开控制面板->程序和功能->启用或关闭windows功能然后如图: 2.配置FTP用户 我的电脑->右击点击管理->本地用户和组 在A ...
- 0426JavaSE01day02.txt=========正则、Object、包装类详解
正则表达式 基本正则表达式:正则表达式简介.分组(). "^"和"$" String正则API:matches方法.split方法.replaceAll方法 O ...
- (六)循环和控制语句及列表迭代(enumerate)
一.pythoh中while.for.if的循环 嗯.........这个好像没什么好说的,简单粗暴来几个游戏! 1.来玩儿个猜数字游戏,需求:只能猜3次,小了提示小,大了提示大,猜对了游戏结束 3次 ...
- 最短路径(Dijkstra算法)
算法局限性:边的权值不能为负. 需要两个辅助数组dist[],path[],分别记录起点到各点的最短距离和最短路径 算法步骤: 1.根据起点v0初始化dist[]和path[]数组. 2.在剩下的点中 ...
- luogu P5304 [GXOI/GZOI2019]旅行者
传送门 所以这个\(5s\)是SMG 暴力是枚举每一个点跑最短路,然后有一个很拿衣服幼稚的想法,就是把所有给出的关键点当出发点,都丢到队列里,求最短路的时候如果当前点\(x\)某个相邻的点\(y\)是 ...
- 一个老鸟发的公司内部整理的 Android 学习路线图
基础工具部分: 中文手册,我猜测是Maven中文手册,可是我并没有找到这样的资源,欢迎知道的朋友告诉我: Android部分有 『第三方库集合』,我没能找到资源地址: 书籍我大多是给的豆瓣链接,如果觉 ...
- Linux二进制安装apache2.4.25
Linux二进制安装apache2.4.25 安装环境:CentOS 6.2 先检查是否安装了Apache 如通是通过rpm包安装的话直接用下面的命令:rpm -q httpd 也可以使用如下两种方法 ...
- PyCharm的使用教程
1.1 安装 首先去下载最新的pycharm ,进行安装.可以直接在官网下载. 1.2 首次使用 1,点击Create New Project. 2, 输入项目名.路径.选择python解释器.如果没 ...