Hive学习之路 (十三)Hive分析窗口函数(一) SUM,AVG,MIN,MAX
数据准备
数据格式
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
创建数据库及表
create database if not exists cookie;
use cookie;
drop table if exists cookie1;
create table cookie1(cookieid string, createtime string, pv int) row format delimited fields terminated by ',';
load data local inpath "/home/hadoop/cookie1.txt" into table cookie1;
select * from cookie1;
玩一玩SUM
查询语句
select
cookieid,
createtime,
pv,
sum(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1,
sum(pv) over (partition by cookieid order by createtime) as pv2,
sum(pv) over (partition by cookieid) as pv3,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4,
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5,
sum(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from cookie1;
查询结果
说明
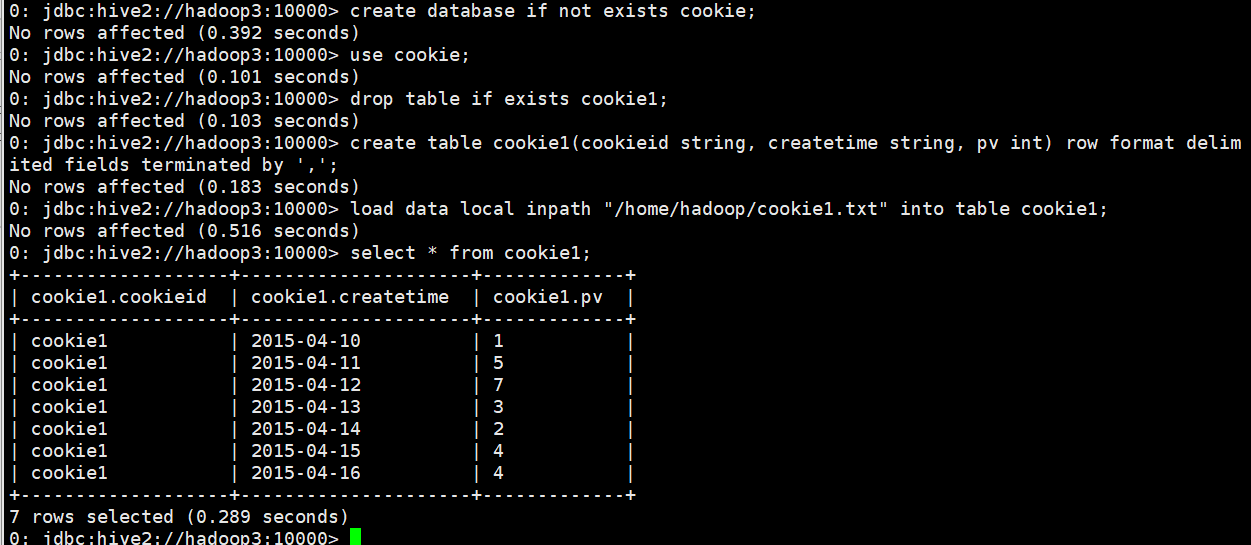
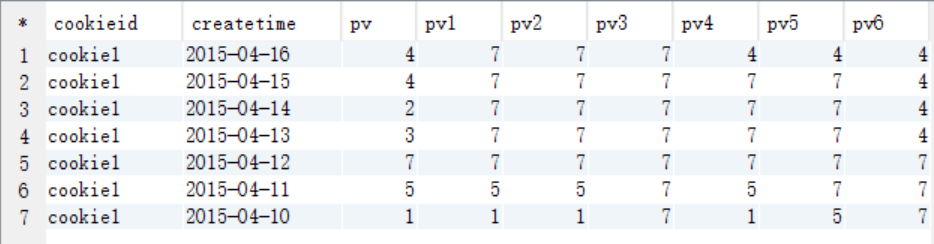
pv1: 分组内从起点到当前行的pv累积,如,11号的pv1=10号的pv+11号的pv, 12号=10号+11号+12号
pv2: 同pv1
pv3: 分组内(cookie1)所有的pv累加
pv4: 分组内当前行+往前3行,如,11号=10号+11号, 12号=10号+11号+12号, 13号=10号+11号+12号+13号, 14号=11号+12号+13号+14号
pv5: 分组内当前行+往前3行+往后1行,如,14号=11号+12号+13号+14号+15号=5+7+3+2+4=21
pv6: 分组内当前行+往后所有行,如,13号=13号+14号+15号+16号=3+2+4+4=13,14号=14号+15号+16号=2+4+4=10
如果不指定ROWS BETWEEN,默认为从起点到当前行;
如果不指定ORDER BY,则将分组内所有值累加;
关键是理解ROWS BETWEEN含义,也叫做WINDOW子句:
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点,
UNBOUNDED PRECEDING 表示从前面的起点,
UNBOUNDED FOLLOWING:表示到后面的终点
–其他AVG,MIN,MAX,和SUM用法一样。
玩一玩AVG
查询语句
select
cookieid,
createtime,
pv,
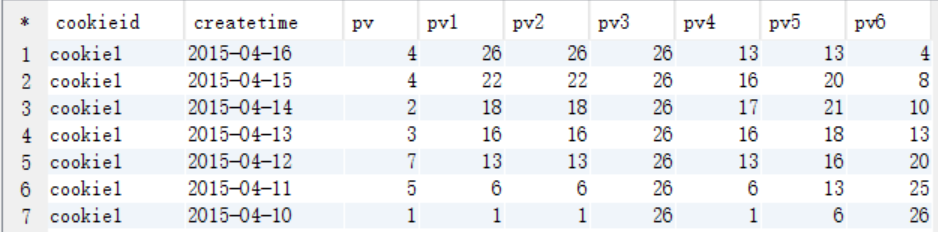
avg(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1, -- 默认为从起点到当前行
avg(pv) over (partition by cookieid order by createtime) as pv2, --从起点到当前行,结果同pv1
avg(pv) over (partition by cookieid) as pv3, --分组内所有行
avg(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4, --当前行+往前3行
avg(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5, --当前行+往前3行+往后1行
avg(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6 --当前行+往后所有行
from cookie1;
查询结果
玩一玩MIN
查询语句
select
cookieid,
createtime,
pv,
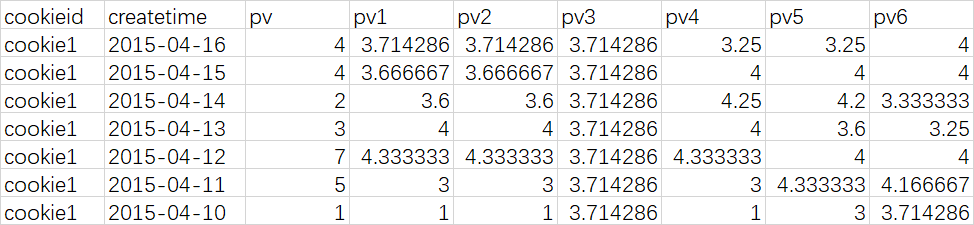
min(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1, -- 默认为从起点到当前行
min(pv) over (partition by cookieid order by createtime) as pv2, --从起点到当前行,结果同pv1
min(pv) over (partition by cookieid) as pv3, --分组内所有行
min(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4, --当前行+往前3行
min(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5, --当前行+往前3行+往后1行
min(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6 --当前行+往后所有行
from cookie1;
查询结果
玩一玩MAX
查询语句
select
cookieid,
createtime,
pv,
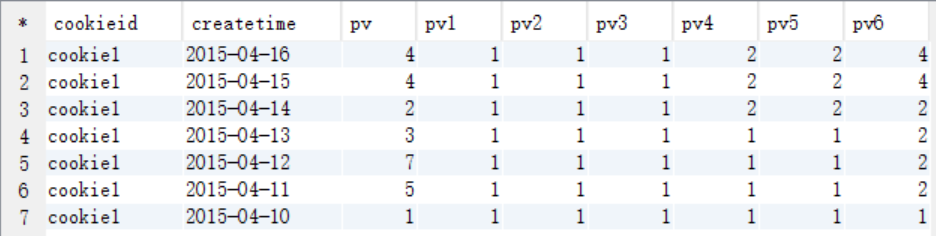
max(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1, -- 默认为从起点到当前行
max(pv) over (partition by cookieid order by createtime) as pv2, --从起点到当前行,结果同pv1
max(pv) over (partition by cookieid) as pv3, --分组内所有行
max(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4, --当前行+往前3行
max(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5, --当前行+往前3行+往后1行
max(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6 --当前行+往后所有行
from cookie1;
查询结果
Hive学习之路 (十三)Hive分析窗口函数(一) SUM,AVG,MIN,MAX的更多相关文章
- Hive分析窗口函数(一) SUM,AVG,MIN,MAX
Hive分析窗口函数(一) SUM,AVG,MIN,MAX Hive分析窗口函数(一) SUM,AVG,MIN,MAX Hive中提供了越来越多的分析函数,用于完成负责的统计分析.抽时间将所有的分析窗 ...
- Hive函数:SUM,AVG,MIN,MAX
转自:http://lxw1234.com/archives/2015/04/176.htm,Hive分析窗口函数(一) SUM,AVG,MIN,MAX 之前看到大数据田地有关于max()over(p ...
- [转帖]Hive学习之路 (一)Hive初识
Hive学习之路 (一)Hive初识 https://www.cnblogs.com/qingyunzong/p/8707885.html 讨论QQ:1586558083 目录 Hive 简介 什么是 ...
- Hive学习之路 (二十)Hive 执行过程实例分析
一.Hive 执行过程概述 1.概述 (1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等 (2)操作符 Opera ...
- Hive学习之路 (一)Hive初识
Hive 简介 什么是Hive 1.Hive 由 Facebook 实现并开源 2.是基于 Hadoop 的一个数据仓库工具 3.可以将结构化的数据映射为一张数据库表 4.并提供 HQL(Hive S ...
- Hive学习之路 (二十一)Hive 优化策略
一.Hadoop 框架计算特性 1.数据量大不是问题,数据倾斜是个问题 2.jobs 数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次 汇总,产生十几个 jobs,耗时很长.原 ...
- Hive学习之路 (十一)Hive的5个面试题
一.求单月访问次数和总访问次数 1.数据说明 数据字段说明 用户名,月份,访问次数 数据格式 A,, A,, B,, A,, B,, A,, A,, A,, B,, B,, A,, A,, B,, B ...
- Hive 学习之路(八)—— Hive 数据查询详解
一.数据准备 为了演示查询操作,这里需要预先创建三张表,并加载测试数据. 数据文件emp.txt和dept.txt可以从本仓库的resources目录下载. 1.1 员工表 -- 建表语句 CREAT ...
- Hive学习之路 (二)Hive安装
Hive的下载 下载地址http://mirrors.hust.edu.cn/apache/ 选择合适的Hive版本进行下载,进到stable-2文件夹可以看到稳定的2.x的版本是2.3.3 Hive ...
随机推荐
- 撩课-Web大前端每天5道面试题-Day26
1.vuejs与angularjs以及react的区别? .与AngularJS的区别 相同点: 都支持指令:内置指令和自定义指令. 都支持过滤器:内置过滤器和自定义过滤器. 都支持双向数据绑定. 都 ...
- GC详解及Minor GC和Full GC触发条件总结
GC,即就是Java垃圾回收机制.目前主流的JVM(HotSpot)采用的是分代收集算法.与C++不同的是,Java采用的是类似于树形结构的可达性分析法来判断对象是否还存在引用.即:从gcroot开始 ...
- python函数之调用函数
调用函数 python中内置了许多函数,我们可以直接调用,但需要注意的是参数的个数和类型一定要和函数一致,有时候不一致时,可以进行数据类型转换 1.abs()函数[求绝对值的函数,只接受一个参数] # ...
- 分享泛微公司OA系统用于二次开发的sql脚本
本单位用的oa系统就是泛微公司的oa协同办公平台,下面是我对他进行二次开发统计用到的写数据库脚本,只做开发参考使用,对于该系统的二次开发技术交流可以加我q:2050372586 [仪表盘]格式sql编 ...
- 强网杯2018 pwn复现
前言 本文对强网杯 中除了 2 个内核题以外的 6 个 pwn 题的利用方式进行记录.题目真心不错 程序和 exp: https://gitee.com/hac425/blog_data/blob/m ...
- 一步一步pwn路由器之radare2使用全解
前言 本文由 本人 首发于 先知安全技术社区: https://xianzhi.aliyun.com/forum/user/5274 radare2 最近越来越流行,已经进入 github 前 25了 ...
- ExpandableListView控件实现二级列表
效果图如下: 二级列表附有点击事件. 1.布局文件: 此处加了一个自定义的导航RelativeLayout,记得注activity的时候添加 android:theme="@style/Th ...
- Pig脚本 .pig
pig脚本就是一个文件,保存了多条pig命令,通常后缀是.pig(不强制). 多行注释:/**/ 单行注释:-- 下面是一个名字是test.pig的脚本的例子: /* ...
- canvas交互部分
mousemove let mouse = { x: undefined, y: undefined, } // 鼠标监听事件,获取鼠标移动的相应坐标 window.addEventListener( ...
- Oracle数据库日期格式转换操作
1. 日期转化为字符串 (以2016年10月20日为例) select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') strDateTime from dual; ...