大数据-Hadoop 本地运行模式
Grep案例
1. 创建在hadoop-2.7.2文件下面创建一个input文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir input
2. 将Hadoop的xml配置文件复制到input
[atguigu@hadoop101 hadoop-2.7.2]$ cp etc/hadoop/*.xml input

3. 执行share目录下的MapReduce程序(执行)
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'(要正常的运行,必须要保证output删除,没有才能运行)

4. 查看输出结果
[atguigu@hadoop101 hadoop-2.7.2]$ cat output/*

WordCount案例
1. 创建在hadoop-2.7.2文件下面创建一个wcinput文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir wcinput
2. 在wcinput文件下创建一个wc.input文件
[atguigu@hadoop101 hadoop-2.7.2]$ cd wcinput
[atguigu@hadoop101 wcinput]$ touch wc.input
3. 编辑wc.input文件
[atguigu@hadoop101 wcinput]$ vi wc.input
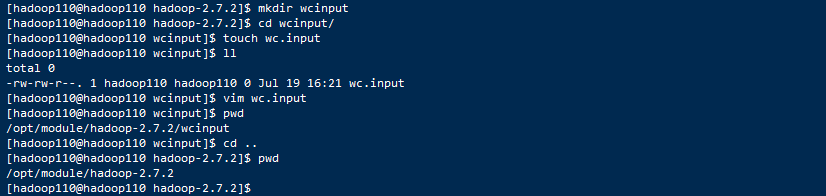
保存退出::wq
4. 回到Hadoop目录/opt/module/hadoop-2.7.2
5. 执行程序
[atguigu@hadoop101 hadoop-2.7.2]$ hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput

6. 查看结果
[atguigu@hadoop101 hadoop-2.7.2]$ cat wcoutput/part-r-00000

大数据-Hadoop 本地运行模式的更多相关文章
- hadoop本地运行模式调试
一:简介 最近学习hadoop本地运行模式,在运行期间遇到一些问题,记录下来备用:以运行hadoop下wordcount为例子. hadoop程序是在集群运行还是在本地运行取决于下面两个参数的设置,第 ...
- 大数据Hadoop入门视频教程:Hadoop的快如入门
最新在学习hadoop .storm大数据相关技术,发现网上hadoop .storm 相关学习视频少之又少,这里整理了传智播客段海涛老师的hadoop学习视频,出来给大家学习交流. 视频下载地址:h ...
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- Hadoop大数据学习视频教程 大数据hadoop运维之hadoop快速入门视频课程
Hadoop是一个能够对大量数据进行分布式处理的软件框架. Hadoop 以一种可靠.高效.可伸缩的方式进行数据处理适用人群有一定Java基础的学生或工作者课程简介 Hadoop是一个能够对大量数据进 ...
- Hadoop之运行模式
Hadoop运行模式包括:本地模式.伪分布式以及完全分布式模式. 一.本地运行模式 1.官方Grep案例 1)在hadoop-2.7.2目录下创建一个 input 文件夹 [hadoop@hadoop ...
- spark之scala程序开发(本地运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- hadoop本地运行与集群运行
开发环境: windows10+伪分布式(虚拟机组成的集群)+IDEA(不需要装插件) 介绍: 本地开发,本地debug,不需要启动集群,不需要在集群启动hdfs yarn 需要准备什么: 1/配置w ...
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
随机推荐
- DOCKER学习_013:Dockerfile配置指令ENTRYPOINT详解
前面已经介绍了一些Dockerfile的一些指令,对于ENTRYPOINT和CMD也有介绍实验 一 ENTRYPOINT和CMD配置使用 ENTRYPOINT相当于CMD,是配置容器后的一个指令,但是 ...
- C++ short/int/long/long long 等数据类型大小
表 1 整型数据类型 数据类型 字节大小 数值范围 short int (短整型) 2 字节 -32 768 〜+32 767 unsigned short int(无符号短整型) 2 字节 0 〜+ ...
- gpgj - 06.估值分析举例
06.估值分析举例 1.举个栗子-贵州茅台的护城河 品牌效益高 只有高档产品 不卖中低档,不会拉低公司收入 { "question": "我们来复习一下护城河要如何分 ...
- BASE理论之思考
一.什么是BASE理论? BASE理论是对CAP中一致性和可用性权衡的结果,它的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性. BASE理论 ...
- 深入探索Glide图片加载框架:做了哪些优化?如何管理生命周期?怎么做大图加载?
前言 Glide可以说是最常用的图片加载框架了,Glide链式调用使用方便,性能上也可以满足大多数场景的使用,Glide源码与原理也是面试中的常客. 但是Glide的源码内容比较多,想要学习它的源码往 ...
- 深入浅出Promise
Abstract Promise的意思是承诺(在红宝书中翻译为期约),新华字典:(动)对某项事务答应照办. Promise最早出现在Commn JS,随后形成了Promise/A规范. Promise ...
- 部署通用基础设施, 满足顶级 SLA 要求
部署通用基础设施, 满足顶级 SLA 要求 Telefónica 使用基于英特尔 至强 可扩展处理器和英特尔 傲腾 数据中心级固态盘 的 VMware 虚拟存储区域网络 (vSAN)* 架构,完成对高 ...
- 与现代传感器的接口:轮询ADC驱动程序
与现代传感器的接口:轮询ADC驱动程序 Interfacing with modern sensors: Polled ADC drivers 我们研究了在现代嵌入式应用程序中,开发人员应该如何创建一 ...
- mybatis——解决属性名和数据库字段名不一致问题
首先说一下,我的数据库名字叫mybatis,里边有一张user表,表中有三个字段,id.name.pwd:然后实体类中对应三个属性id.name.password(id和name跟数据库字段名一致,但 ...
- JUC下工具类CountDownLatch用法以及源码理解
CountDownLoatch是JUC下一个用于控制计数的计数器,比如我需要从6开始计数,每个线成运行完之后计数减一,等计数器到0时候开始执行其他任务. public static void main ...