教你如何使用FusionInsight SqoopShell
摘要:Sqoop-shell是一个Loader的shell工具,其所有功能都是通过执行脚本“sqoop2-shell”来实现的。
本文分享自华为云社区《FusionInsight SqoopShell使用案例》,作者:Jia装大佬。
1 SqoopShell使用简介
sqoop-shell是一个Loader的shell工具,其所有功能都是通过执行脚本“sqoop2-shell”来实现的。
sqoop-shell工具提供了如下功能:
- 支持创建和更新连接器
- 支持创建和更新作业
- 支持删除连接器和作业
- 支持以同步或异步的方式启动作业
- 支持停止作业
- 支持查询作业状态
- 支持查询作业历史执行记录
- 支持复制连接器和作业
- 支持创建和更新转换步骤
- 支持指定行、列分隔符
sqoop-shell工具支持如下模式:
- 交互模式
通过执行不带参数的“sqoop2-shell”脚本,进入Loader特定的交互窗口,用户输入脚本后,工具会返回相应信息到交互窗口。
- 批量模式
通过执行“sqoop2-shell”脚本,带一个文件名作为参数,该文件中按行存储了多条命令,sqoop-shell工具将会按顺序执行文件中所有命令;或者在“sqoop2-shell”脚本后面通过“-c”参数附加一条命令,一次只执行一条命令。
2 SqoopShell配置
2.1 配置Loader客户端
1. 使用“PuTTY”工具,使用安装客户端的用户登录客户端所在节点。
2. 执行以下命令,防止超时退出。
TMOUT=0
3. 执行以下命令,进入Loader客户端安装目录。例如,Loader客户端安装目录为“/opt/hadoopclient/Loader”。
cd /opt/hadoopclient/Loader
4. 执行以下命令,配置环境变量。
source /opt/hadoopclient/bigdata_env
5. 执行以下命令解压“loader-tools-1.99.3.tar”。
tar -xvf loader-tools-1.99.3.tar
解压后的新文件保存在“loader-tools-1.99.3”目录。
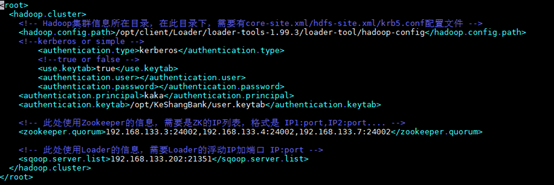
6. 执行以下命令修改工具授权配置文件“login-info.xml”,并保存退出。
vi loader-tools-1.99.3/loader-tool/job-config/login-info.xml
2.2 配置sqoopshell 配置文件
- 使用“PuTTY”工具,使用安装客户端的用户登录Loader客户端所在节点。
- 执行以下命令,进入sqoop-shell工具的“conf”目录。例如,Loader客户端安装目录为“/opt/hadoopclient/Loader”。
cd /opt/hadoopclient/Loader/loader-tools-1.99.3/sqoop-shell/conf
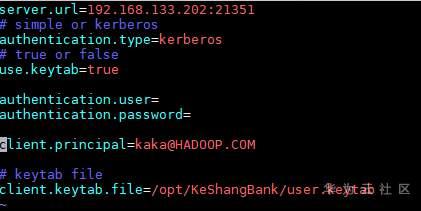
- 执行以下命令,配置认证信息。
vi client.properties
3 Sqoopshell使用示例
3.1 交互模式
1. 执行以下命令,进入交互模式(客户端以/opt/hadoopclient为例)。
source /opt/hadoopclient/bigdata_env
cd /opt/hadoopclient/Loader/loader-tools-1.99.3/sqoop-shell
./sqoop2-shell
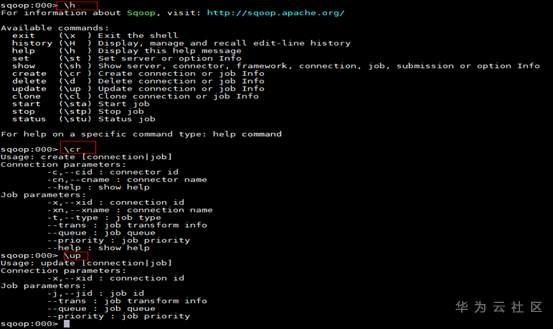
2. 获取帮助信息(\h获取帮助信息,\cr获取create的帮助信息,\up获取更新的帮助信息,以此类推)
3. 查看连接器

以此类推,可以查看framework、job、connection等信息

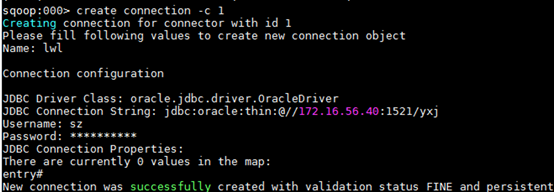
4. 创建连接器
根据show connector信息选择对应的连接器,根据create帮助信息创建connection,然后根据命令行提示,输入对应信息,假如提示的参数无需设置,可按enter直接跳过
5. 创建作业
根据show connection出来的信息选择对应链接,根据create帮助信息创建Job,然后根据命令行提示,输入对应信息,假如提示的参数无需设置,可按enter直接跳过
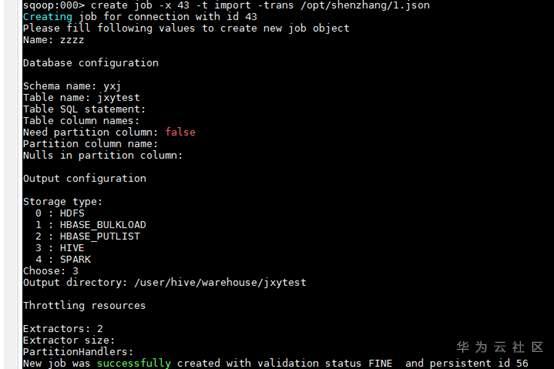
也可以使用—help查看创建job的选项信息

Json获取方法
1) 登录loader原生页面,创建一个相同类型的作业(如TaiPingTab)。

2) 导出作业的配置json文件,复制json文件中,hops的内容(包括大括号),保存为新的json文件

3) 根据业务需要调整json文件。
3.2 批量模式
批量模式有两种方式,一种是./sqoop2-shell+脚本的方式,脚本中配置待执行的命令
另一种是./sqoop2-shell -c “待执行的命令”方式
获取帮助:
./sqoop2-shell -c "create connection -cn generic-jdbc-connector --help"获取创建connection的帮助信息
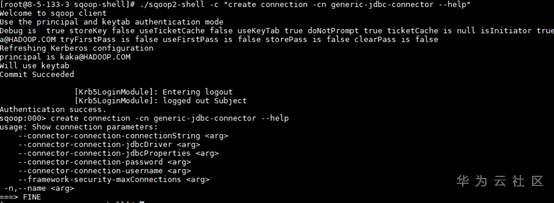
./sqoop2-shell -c "create job -xn mysql -t import --help"查看创建Job帮助信息
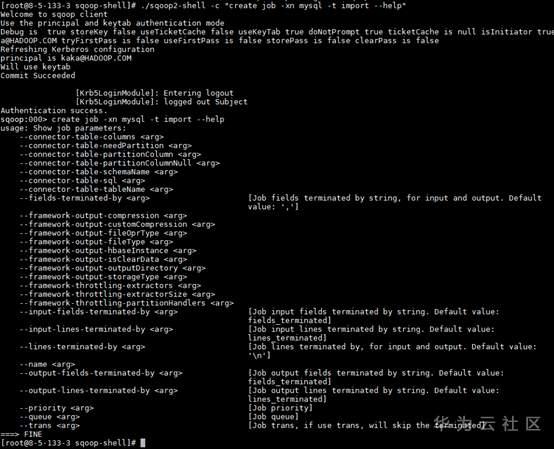
1. 脚本方式
cd /opt/hadoopclient/Loader/loader-tools-1.99.3/sqoop-shell
vi batchCommand.sh
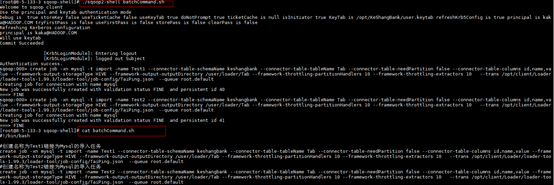

更新作业
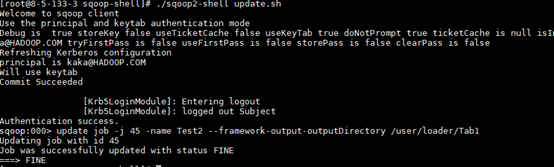
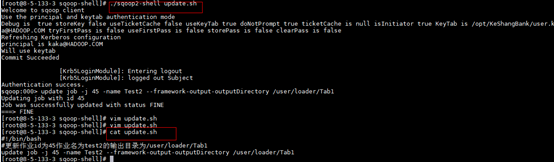
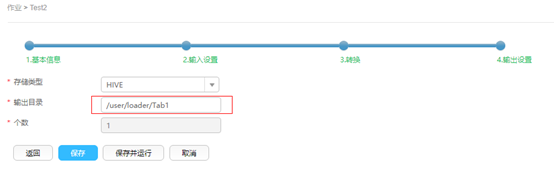
2. –c 方式(使用-c参数附带一条命令,sqoop-shell可以一次只执行附带的这一条命令)
创建链接为mysql名称为TaiPingTab的导入任务
./sqoop2-shell -c "create job -xn mysql -t import -name TaiPingTab --connector-table-schemaName keshangbank --connector-table-tableName Tab --connector-table-needPartition false --connector-table-columns id,name,value --framework-output-storageType HIVE --framework-output-outputDirectory /user/loader/Tab --framework-throttling-partitionHandlers 10 --framework-throttling-extractors 10 --trans /opt/client/Loader/loader-tools-1.99.3/loader-tool/job-config/TaiPing.json --queue root.default"

启动:./sqoop2-shell -c "start job -n TaiPingTab -s"
删除:./sqoop2-shell -c "delete job -n TaiPingTab"
更新:./sqoop2-shell -c 'update job -j 37 -name update-test --connector-table-sql "select * from keshangbank.update_test where time < "2020-2-2" and ${CONDITIONS}" '
注: 1. sqoop-shell目录中createConnection createJob helpCmd startCmd中详细描述了各个参数的含义
2. Json文件的获取及参考方式均一样,批量模式中Json文件的获取跟方式请参考交互模式中json的获取方式
3. 此文档中并未对参数详细介绍,参数部分可参考产品文档sqoop-shell章节
4. 更新的参数和创建的参数保持一致
- 附件:SqoopShell使用案例.docx743.88KB
- 附件:Json.rar
教你如何使用FusionInsight SqoopShell的更多相关文章
- FusionInsight MRS:你的大数据“管家”
摘要:4月24日-26日,HDC.Cloud2021在深圳大学城成功举办,华为云FusionInsight MRS云原生数据湖带来最懂行的大数据解决方案,为政企客户提供湖仓一体.云原生的大数据解决方案 ...
- 手把手教你做个人 app
我们都知道,开发一个app很大程度依赖服务端:服务端提供接口数据,然后我们展示:另外,开发一个app,还需要美工协助切图.没了接口,没了美工,app似乎只能做成单机版或工具类app,真的是这样的吗?先 ...
- CRL快速开发框架系列教程一(Code First数据表不需再关心)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
- 手把手教从零开始在GitHub上使用Hexo搭建博客教程(四)-使用Travis自动部署Hexo(2)
前言 前面一篇文章介绍了Travis自动部署Hexo的常规使用教程,也是个人比较推荐的方法. 前文最后也提到了在Windows系统中可能会有一些小问题,为了在Windows系统中也可以实现使用Trav ...
- 手把手教从零开始在GitHub上使用Hexo搭建博客教程(三)-使用Travis自动部署Hexo(1)
前言 前面两篇文章介绍了在github上使用hexo搭建博客的基本环境和hexo相关参数设置等. 基于目前,博客基本上是可以完美运行了. 但是,有一点是不太好,就是源码同步问题,如果在不同的电脑上写文 ...
- 手把手教从零开始在GitHub上使用Hexo搭建博客教程(二)-Hexo参数设置
前言 前文手把手教从零开始在GitHub上使用Hexo搭建博客教程(一)-附GitHub注册及配置介绍了github注册.git相关设置以及hexo基本操作. 本文主要介绍一下hexo的常用参数设置. ...
- 手把手教从零开始在GitHub上使用Hexo搭建博客教程(一)-附GitHub注册及配置
前言 有朋友问了我关于博客系统搭建相关的问题,由于是做开发相关的工作,我给他推荐的是使用github的gh-pages服务搭建个人博客. 推荐理由: 免费:github提供gh-pages服务是免费的 ...
- 手把手教你用FineBI做数据可视化
前些日子公司引进了帆软商业智能FineBI,在接受了简单的培训后,发现这款商业智能软件用作可视分析只用一个词形容的话,那就是“轻盈灵动”!界面简洁.操作流畅,几个步骤就可以创建分析,获得想要的效果.此 ...
- 教你怎么半天搞定Docker
首先,不要把docker想的那么高大,它不就是先做个镜像,然后通过docker像虚拟机一样跑起来嘛...docker其实在真实业务场景中还是非常有局限性的.Dockerfile脚本也没那么好写,有些应 ...
随机推荐
- 根据所处位置提取单元格内容的函数(left、right、mid)和查找字符串位于单元格内容第几位的函数(find)
1.从左到右提取:left(value,num_chars) 注释:value为操纵单元格,num_chars表示截取的字符的数量 2.从右往左提取:right(value,num_chars) 注释 ...
- Redis的flushall/flushdb误操作
Redis的flushall/flushdb命令可以做数据清除,对于Redis的开发和运维人员有一定帮助,然而一旦误操作,它的破坏性也是很明显的.怎么才能快速恢复数据,让损失达到最小呢? 假设进行fl ...
- 11、gitlab和Jenkins整合(1)
1.在jenkins上安装git: 因为jenkins需要在gitlab上拉取代码: 具体的git安装,参考"4.git和gitlab的配置--4.2.git编译安装:": 2.在 ...
- C# 获取电脑Mac地址
private string getMAC() { try { NetworkInterface[] interfaces = NetworkInterface.GetAllNetworkInterf ...
- POJ 2002 二分 计算几何
根据正方形对角的两顶点求另外两个顶点公式: x2 = (x1+x3-y3+y1)/2; y2 = (x3-x1+y1+y3)/2; x4= (x1+x3+y3-y1)/2; y4 = (-x3+x1+ ...
- POJ 1556 计算几何 判断线段相交 最短路
题意: 在一个左下角坐标为(0,0),右上角坐标为(10,10)的矩形内,起点为(0,5),终点为(10,5),中间会有许多扇垂直于x轴的门,求从起点到终点在能走的情况下的最短距离. 分析: 既然是求 ...
- Spring Boot和Feign中使用Java 8时间日期API(LocalDate等)的序列化问题
LocalDate.LocalTime.LocalDateTime是Java 8开始提供的时间日期API,主要用来优化Java 8以前对于时间日期的处理操作.然而,我们在使用Spring Boot或使 ...
- 保存TextBox中的文字为Path功能
保存TextBox中的文字为Path功能 今天再设计一个我自己程序的Icon时使用了Path+textbox做了图形,我不想导出为PNG,因为颜色比较单一,我又想通过代码控制颜色,所以我想完整的保存为 ...
- 关于kong | API Gateway
目录 为什么需要 API 网关(more) kong的概念 为什么使用Kong Kong 的管理方式 高可扩展性的背后-插件机制 [前言]: Kong是一个云原生,高效,可扩展的分布式 API 网关. ...
- 常见内部排序算法对比分析及C++ 实现代码
内部排序是指在排序期间数据元素全部存放在内存的排序.外部排序是指在排序期间全部元素的个数过多,不能同时存放在内存,必须根据排序过程的要求,不断在内存和外存之间移动的排序.本次主要介绍常见的内部排序算法 ...