Python 爬虫从入门到进阶之路(四)
之前的文章我们做了一个简单的例子爬取了百度首页的 html,我们用到的是 urlopen 来打开请求,它是一个特殊的opener(也就是模块帮我们构建好的)。但是基本的 urlopen() 方法不支持代理、cookie等其他的HTTP/HTTPS高级功能,所以我们需要用到 Python 的 opener 来自定义我们的请求内容。
具体步骤:
- 使用相关的
Handler处理器来创建特定功能的处理器对象; - 然后通过
build_opener()方法使用这些处理器对象,创建自定义opener对象; - 使用自定义的opener对象,调用
open()方法发送请求。
我们先来回顾一下使用 urlopen 获取百度首页的 html 代码实例:
# 导入urllib 库
import urllib.request # url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request("http://www.baidu.com")
# Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
# 类文件对象支持 文件对象的操作方法,如read()方法读取文件全部内容,返回字符串
html = response.read().decode("utf-8")
# 打印字符串
print(html)
接下来我们看一下使用 opener 的处理方式:
from urllib import request # 构建一个HTTPHandler 处理器对象,支持处理HTTP请求
http_handler = request.HTTPHandler() # 构建一个HTTPSHandler 处理器对象,支持处理HTTPS请求
# http_handler = request.HTTPSHandler() # 调用 request.build_opener()方法,创建支持处理HTTP请求的opener对象
opener = request.build_opener(http_handler) # 构建 Request请求
request = request.Request("http://www.baidu.com/") # 调用自定义opener对象的open()方法,发送request请求
response = opener.open(request) # 获取服务器响应内容
html = response.read().decode("utf-8") # 打印字符串
print(html)
在上面的第一段代码中,我们是通过直接 import urllib.request 来导入我们需要的包,这样当我们要使用时需要 urllib.request 来使用,第二段代码我们是通过 from urllib import request 来导入我们需要的包,这样当我们使用时直接 request 来使用就可以了。
第一段代码在前面的文章中我们已经说过了,这里就不多做解释了。
第二段代码中,我们使用了 opener 的方法来处理我们的请求,这样我们就可以对代理,cookie 等做进一步的操作,后续文章会讲到。最终结果如下:
在 http_handler = request.HTTPHandler() 中,我们还可以添加一个 debuglevel=1 参数,会将 Debug Log 打开,这样程序在执行的时候,会把收包和发包的报头在屏幕上自动打印出来,方便调试,有时可以省去抓包的工作。
代码如下:
from urllib import request # 构建一个HTTPHandler 处理器对象,支持处理HTTP请求
http_handler = request.HTTPHandler(debuglevel=1) # 构建一个HTTPHandler 处理器对象,支持处理HTTPS请求
# http_handler = request.HTTPSHandler(debuglevel=1) # 调用 request.build_opener()方法,创建支持处理HTTP请求的opener对象
opener = request.build_opener(http_handler) # 构建 Request请求
request = request.Request("http://www.baidu.com/") # 调用自定义opener对象的open()方法,发送request请求
response = opener.open(request) # 获取服务器响应内容
html = response.read().decode("utf-8") # 打印字符串
print(html)
输出结果如下:
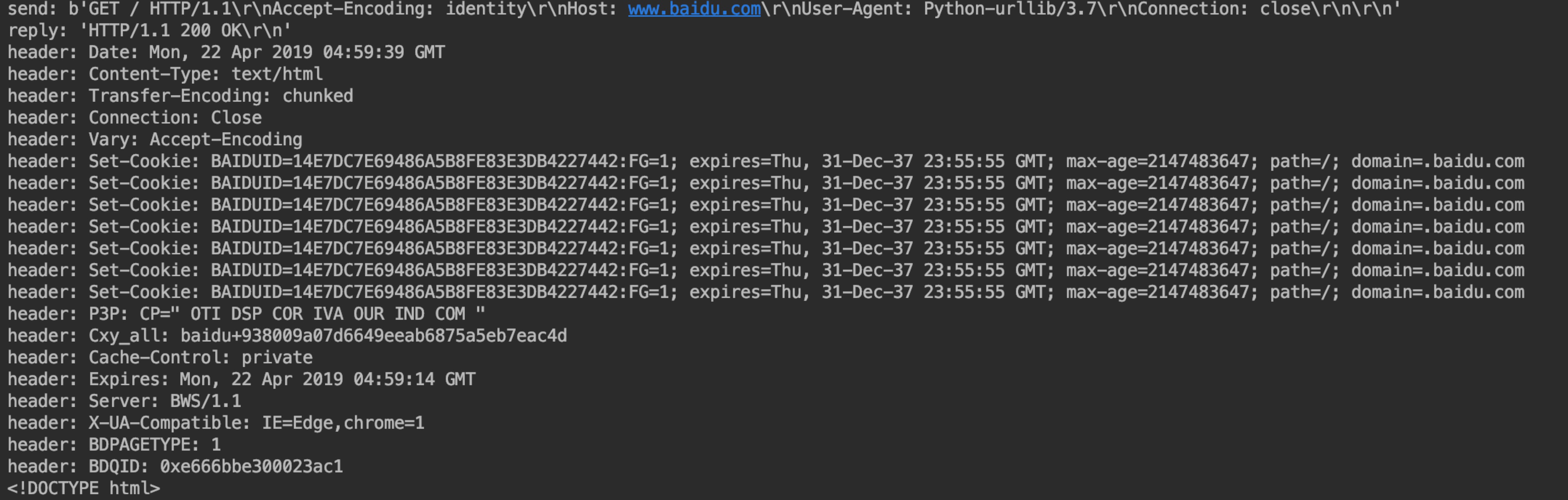
可以看出在响应结果的时候会为我们打印输出一些请求信息。
Python 爬虫从入门到进阶之路(四)的更多相关文章
- Python 爬虫从入门到进阶之路(八)
在之前的文章中我们介绍了一下 requests 模块,今天我们再来看一下 Python 爬虫中的正则表达的使用和 re 模块. 实际上爬虫一共就四个主要步骤: 明确目标 (要知道你准备在哪个范围或者网 ...
- Python 爬虫从入门到进阶之路(二)
上一篇文章我们对爬虫有了一个初步认识,本篇文章我们开始学习 Python 爬虫实例. 在 Python 中有很多库可以用来抓取网页,其中内置了 urllib 模块,该模块就能实现我们基本的网页爬取. ...
- Python 爬虫从入门到进阶之路(六)
在之前的文章中我们介绍了一下 opener 应用中的 ProxyHandler 处理器(代理设置),本篇文章我们再来看一下 opener 中的 Cookie 的使用. Cookie 是指某些网站服务器 ...
- Python 爬虫从入门到进阶之路(九)
之前的文章我们介绍了一下 Python 中的正则表达式和与爬虫正则相关的 re 模块,本章我们就利用正则表达式和 re 模块来做一个案例,爬取<糗事百科>的糗事并存储到本地. 我们要爬取的 ...
- Python 爬虫从入门到进阶之路(十二)
之前的文章我们介绍了 re 模块和 lxml 模块来做爬虫,本章我们再来看一个 bs4 模块来做爬虫. 和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也 ...
- Python 爬虫从入门到进阶之路(十五)
之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取<糗事百科>的糗事进行丰富和完善. 在 Xpath 模块的爬取糗百的案例中我 ...
- Python 爬虫从入门到进阶之路(十六)
之前的文章我们介绍了几种可以爬取网站信息的模块,并根据这些模块爬取了<糗事百科>的糗百内容,本章我们来看一下用于专门爬取网站信息的框架 Scrapy. Scrapy是用纯Python实现一 ...
- Python 爬虫从入门到进阶之路(十七)
在之前的文章中我们介绍了 scrapy 框架并给予 scrapy 框架写了一个爬虫来爬取<糗事百科>的糗事,本章我们继续说一下 scrapy 框架并对之前的糗百爬虫做一下优化和丰富. 在上 ...
- Python 爬虫从入门到进阶之路(五)
在之前的文章中我们带入了 opener 方法,接下来我们看一下 opener 应用中的 ProxyHandler 处理器(代理设置). 使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的. 很 ...
- Python 爬虫从入门到进阶之路(七)
在之前的文章中我们一直用到的库是 urllib.request,该库已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Hum ...
随机推荐
- 深入理解this原理(JavaScript)
文章目录 JavaScript中this的原理 一.问题的由来 二.内存的数据结构 三.函数 四.环境变量 JavaScript中this的原理 一.问题的由来 学懂 JavaScript 语言,一个 ...
- Goodbye 2019,Welcome 2020 | 沉淀 2020
引言 时间如梭,娃都可以打酱油了. 转眼间第一个五年计划,已过了一半. 年终总结是个打脸的好地方,曾经夸下的海口,有的真的成了海口. 所幸,一切都在按好的方向发展.但乐观背后容易忽略潜在的问 ...
- SSM整合框架(基于IDEA的配置)
Pom文件 <?xml version="1.0" encoding="UTF-8"?><project xmlns="http:/ ...
- 微信小程序 存储数据到本地以及本地获取数据
1.wx存储数据到本地以及本地获取数据 存到本地就是存到你的手机 wx.setStorageSync与wx.setStorage 1.1 wx.setStorageSync(string key, a ...
- Docker从入门到掉坑(四):上手k8s避坑指南
在之前的几篇文章中,主要还是讲解了关于简单的docker容器该如何进行管理和操作,在接下来的这篇文章开始,我们将开始进入对于k8s模块的学习 不熟悉的可以先回顾之前的章节,Docker教程系列文章将归 ...
- 微信公众号:Mysticbinary
愿你有绝对自由.每周会写一篇哲学类文章.
- num2str(A, format)
str = num2str(A, format)A: 数值类型的数组或者是单个的数值format:指定数字转换为字符串的格式,通常’%11.4g’是默认的.也可以指定转换为几位的字符串,不足用0填充, ...
- webpack-dev-server工具
webpack-dev-server来实现自动打包编译功能 // 1.npm install webpack-dev-server -D//2.和webpakc命令用法一样// 3.是本地安装的,无法 ...
- c代码中while循环的一个死机问题引发的思考
前记 c语言已经是一门经常吃饭的本领,本来是要有种看一眼,就知道哪儿出问题了才行,没想到,遇到实际问题的时候,才知道自己的修为不到家.还没有达到那种炉火纯青的境界.看来,不是这个世界没有机会,是自 ...
- C语言程序设计100例之(25):确定进制
例25 确定进制 问题描述 6*9 = 42 对于十进制来说是错误的,但是对于13进制来说是正确的.即 6(13)* 9(13)= 42(13),因为,在十三进制中,42 = 4 * 13 + ...