python 爬虫时遇到问题及解决
源代码:
#unicoding=utf-8
import re
import urllib
def gethtml(url):
html=urllib.urlopen(url)
page=html.read()
return page
def img(page):
reg=r'src="(.+?\jpg)" alt'
imgre=re.compile(reg)
imglist=re.findall(imgre,page)
x=0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
#page=gethtml("http://www.51tietu.net/tp/")
page=gethtml("http://mm.51tietu.net/qingchun/90/")
img(page)
这样执行的话,会出现IOError 大致意思时文件操作时,出现错误
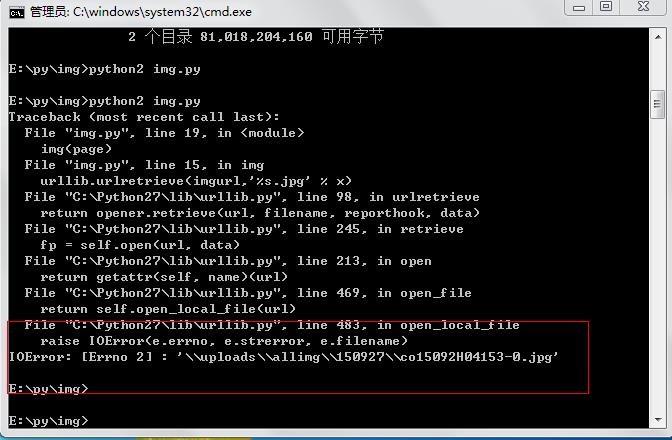
在这里可以看到IOError后跟着你抓取到的jip文件的路径,但是这个路径不是整个url的路径,所以才会在urlretrieve调用imgurl的时候报错。
去网站查看整个URL

因此可以根据图中的url进行修改代码, 想法:可以在urlretrieve中把url补完整,之后代码如下
#unicoding=utf-8
import re
import urllib
def gethtml(url):
html=urllib.urlopen(url)
page=html.read()
return page
def img(page):
reg=r'src="(.+?\jpg)" alt'
imgre=re.compile(reg)
imglist=re.findall(imgre,page)
x=0
for imgurl in imglist:
urllib.urlretrieve('http://mm.51tietu.net'+imgurl,'%s.jpg' % x)
x+=1
#page=gethtml("http://www.51tietu.net/tp/")
page=gethtml("http://mm.51tietu.net/qingchun/90/")
img(page)
之后再进行运行的话,就可以将图片爬取到本地了。
效果如下:

python 爬虫时遇到问题及解决的更多相关文章
- Python爬虫老是被封的解决方法【面试必问】
在爬取的过程中难免发生 ip 被封和 403 错误等等,这都是网站检测出你是爬虫而进行反爬措施,在这里为大家总结一下 Python 爬虫动态 ip 代理防止被封的方法. PS:另外很多人在学习Pyth ...
- python爬虫时,解决编码方式问题的万能钥匙(uicode,utf8,gbk......)
转载 原文:https://blog.csdn.net/xiongzaiabc/article/details/81008330 无论遇到的网页代码是何种编码方式,都可以用以下方法统一解决 imp ...
- Python 爬虫常见的坑和解决方法
1.请求时出现HTTP Error 403: Forbidden headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23. ...
- python爬虫框架scrapy问题的解决
2016-09-24:今天的弄了一天的scrapy的环境的配置的,linux很多的学过的事情都忘记啦.理论和实践的结合还是非常的重要的,不光要学会思考,更要学会总结纪录.还要多多回忆的和复习.学习了不 ...
- Python爬虫技术:爬虫时如何知道是否代理ip伪装成功?
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. python爬虫时如何知道是否代理ip伪装成功: 有时候我们的爬虫程序添加了 ...
- Python爬虫:设置Cookie解决网站拦截并爬取蚂蚁短租
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Eastmount PS:如有需要Python学习资料的小伙伴可以加 ...
- 从python爬虫引发出的gzip,deflate,sdch,br压缩算法分析
今天在使用python爬虫时遇到一个奇怪的问题,使用的是自带的urllib库,在解析网页时获取到的为b'\x1f\x8b\x08\x00\x00\x00\x00...等十六进制数字,尝试使用chard ...
- Python爬虫之xpath语法及案例使用
Python爬虫之xpath语法及案例使用 ---- 钢铁侠的知识库 2022.08.15 我们在写Python爬虫时,经常需要对网页提取信息,如果用传统正则表达去写会增加很多工作量,此时需要一种对数 ...
- python爬虫中文乱码解决方法
python爬虫中文乱码 前几天用python来爬取全国行政区划编码的时候,遇到了中文乱码的问题,折腾了一会儿,才解决.现特记录一下,方便以后查看. 我是用python的requests和bs4库来实 ...
随机推荐
- HDU 1051 - Rightmost Digit
找循环 #include <iostream> #include <cmath> using namespace std; int t,m,p,q; long long n; ...
- c#datagrid的每行的单击事件
需要一个帮助类 using System; using System.Net; using System.Windows; using System.Windows.Controls; using S ...
- Long,String类型的两个值进行比较,注意点!!!
一: . Long 类型指的是 java.util.Lang 对象,而不是基本类型 long (注意大小写)Java中如果使用 == 双等于比较对象,等于比较的是两个对象的内存地址,也就是比较两个对象 ...
- $ cd `dirname $0` 和PWD%/* shell变量的一些特殊用法
在命令行状态下单纯执行 $ cd `dirname $0` 是毫无意义的.因为他返回当前路径的".". $0:当前Shell程序的文件名dirname $0,获取当前Shell程序 ...
- oracle使用口令文件验证和os验证
一.Oracle安装之后默认情况下是启用了OS认证的,这里提到的os认证是指服务器端os认证.OS认证的意思把登录数据库的用户和口令校验放在了操作系统一级.如果以安装Oracle时的用户登录OS,那么 ...
- Java、Tomcat 及 MySQL 环境配置
Java开发环境的配置 首先我们要下载JDK. 到Oracle官网上去下载即可,目前最新版是Java SE 8u25. 开始我很混乱,Java SE 和 JDK是什么关系呢?最后查了一下 Java S ...
- python运维开发(十二)----rabbitMQ、pymysql、SQLAlchemy
内容目录: rabbitMQ python操作mysql,pymysql模块 Python ORM框架,SQLAchemy模块 Paramiko 其他with上下文切换 rabbitMQ Rabbit ...
- OpenWRT交叉编译
对于当前不在OpenWRT repository中的软件,如果是用源码形式发布的,那么可以用OpenWRT Buildroot进行交叉编译. 首先编译好Buildroot(一般编译过一次固件,就已经编 ...
- jquery $ dollar符号用法总结
参考:https://github.com/chyingp/blog/blob/master/jquery/jQuery%E6%BA%90%E7%A0%81-%E7%BE%8E%E5%85%83$%E ...
- Baidu Sitemap Generator插件使用图解教程
这两天因为百度对本博客文章收录更新很慢,一直在网络查找真正的原因和解决方法.最终发现了柳城开发的Baidu Sitemap Generator WordPress插件,最终效果如果还需要验证一段时间. ...