scrapy框架用CrawlSpider类爬取电影天堂.
本文使用CrawlSpider方法爬取电影天堂网站内国内电影分类下的所有电影的名称和下载地址
CrawlSpider其实就是Spider的一个子类。
CrawlSpider功能更加强大(链接提取器,规则解释器)
#CrawlSpider一些主要功能如下
#LinkExtractor()实例化了一个链接提取对象,链接提取器:用来提取指定的链接(url)
#allow参数:赋值一个正则表达式,链接提取器就可以根据正则表达式在页面中提取指定的链接
#提取到的链接全部交给规则解释器
#rules=()实例化了一个规则解析器对象
#规则解析器接受了链接提取器发送的链接后,就会对这些链接发起请求,获取链接对应的页面内容,就会根据指定的规则对页面内容指定的数据进行解析
#callback:指定一个解析规则(方法,函数)
#follw:是否将链接提取器继续作用到链接提取器提取出的链接所表示的页面数据中
#LinkExtractor:设置提取链接的规则(正则表达式)
allow=():设置允许提取的url
restrict_xpaths=():根据xpath语法,定位到某一标签下提取链接
restrict_css=():根据css选择器,定位到某一标签下提取链接
deny=():设置不允许提取的url(优先级比allow高)
allow_domains=():设置允许提取的url的域
deny_domains=():设置不允许提取url的域(优先级比allow_domains高)
unique=True:如果出现多个相同的url只会保留一个,默认为True
strip=True:自动去除url首位的空格,默认为True
process_links=None:可以设置回调函数,对所有提取到的url进行拦截
process_request=identity:可以设置回调函数,对request对象进行拦截 0,创建scrapy项目
scrapy startproject dianyingtiantang cd dianyingtiantang
#后面的网址先随便写,在程序里面改
scrapy genspider -t crawl dytt www.xxx.com
1,items中定义爬取的字段
import scrapy class DianyingtiantangItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
movie_url = scrapy.Field()
2,编写爬虫主程序
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from dianyingtiantang.items import DianyingtiantangItem class DyttSpider(CrawlSpider):
name = 'dytt'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.ygdy8.net/html/gndy/china/index.html']
rules = (
Rule(LinkExtractor(allow=r'/html/gndy/jddy/(\d+)/(\d+).html'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = DianyingtiantangItem()
item['name'] = response.xpath('//td/p/text()|//div[@class="title_all"]/h1/font/text()').extract_first()
item['movie_url'] = response.xpath('//tbody/tr/td/a/@href|//tbody/tr/td/p/a/@href').extract_first()
yield item
3,pipelines.py文件中编写永久性存储规则,写入mysql数据库和.txt文件
# 写入数据库
import pymysql
class DianyingtiantangPipeline(object):
conn = None
mycursor = None def open_spider(self, spider):
self.conn = pymysql.connect(host='172.16.25.4', user='root', password='root', db='scrapy')
self.mycursor = self.conn.cursor() def process_item(self, item, spider):
print(item['name'] + ':正在写数据库...')
sql = 'insert into dytt VALUES (null,"%s","%s")' % (
item['name'], item['movie_url'])
bool = self.mycursor.execute(sql)
self.conn.commit()
return item def close_spider(self, spider):
print('写入数据库完成...')
self.mycursor.close()
self.conn.close()
# 写入.txt
class FilePipeline(object):
f = None
def open_spider(self,spider):
self.f = open('dytt.txt','a+',encoding='utf-8')
def process_item(self, item, spider):
print(item['name'] + ':正在写入文件...')
self.f.write(item['movie_url']+'\n')
return item
def close_spider(self,spider):
print('写入文件完成...')
self.f.close()
4,settings.py文件中打开项目管道和设置请求头
ITEM_PIPELINES = {
'dianyingtiantang.pipelines.DianyingtiantangPipeline': 200,
'dianyingtiantang.pipelines.FilePipeline': 300,
}
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36'
5,运行爬虫程序
scrapy crawl dytt --nolog
6,查看数据库和文件内是否下载成功
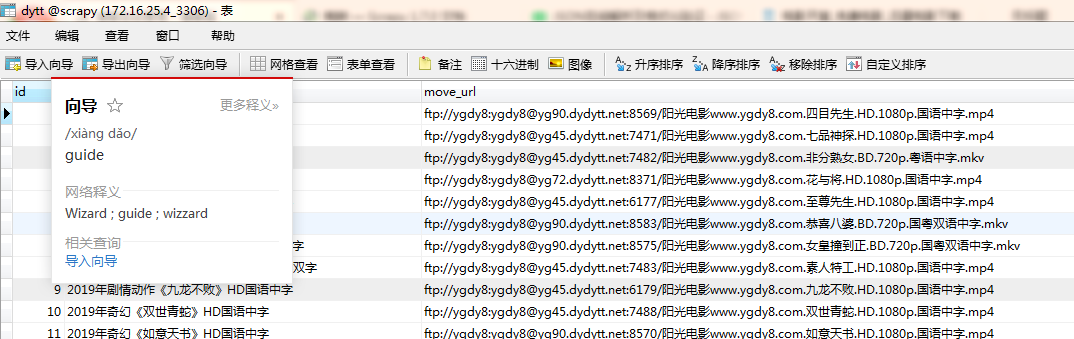
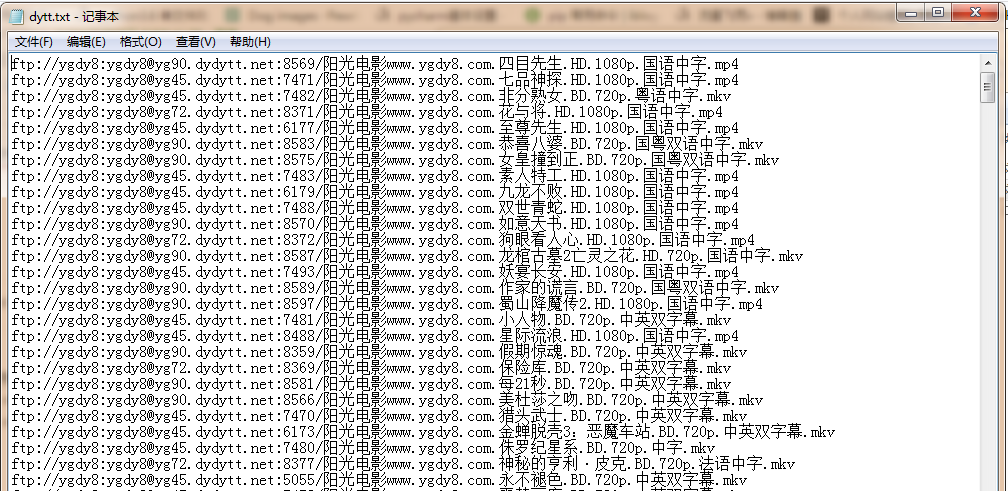
可以用迅雷下载器下载电影了,
done。
scrapy框架用CrawlSpider类爬取电影天堂.的更多相关文章
- python利用requests和threading模块,实现多线程爬取电影天堂最新电影信息。
利用爬到的数据,基于Django搭建的一个最新电影信息网站: n1celll.xyz (用的花生壳动态域名解析,服务器在自己的电脑上,纯属自娱自乐哈.) 今天想利用所学知识来爬取电影天堂所有最新电影 ...
- Python爬取电影天堂指定电视剧或者电影
1.分析搜索请求 一位高人曾经说过,想爬取数据,要先分析网站 今天我们爬取电影天堂,有好看的美剧我在上面都能找到,算是很全了. 这个网站的广告出奇的多,用过都知道,点一下搜索就会弹出个窗口,伴随着滑稽 ...
- 14.python案例:爬取电影天堂中所有电视剧信息
1.python案例:爬取电影天堂中所有电视剧信息 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- '''======================== ...
- python爬虫入门(八)Scrapy框架之CrawlSpider类
CrawlSpider类 通过下面的命令可以快速创建 CrawlSpider模板 的代码: scrapy genspider -t crawl tencent tencent.com CrawSpid ...
- 爬虫(十七):Scrapy框架(四) 对接selenium爬取京东商品数据
1. Scrapy对接Selenium Scrapy抓取页面的方式和requests库类似,都是直接模拟HTTP请求,而Scrapy也不能抓取JavaScript动态谊染的页面.在前面的博客中抓取Ja ...
- requests+lxml+xpath爬取电影天堂
1.导入相应的包 import requests from lxml import etree 2.原始ur url="https://www.dytt8.net/html/gndy/dyz ...
- Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- requests+BeautifulSoup | 爬取电影天堂全站电影资源
import requests import urllib.request as ur from bs4 import BeautifulSoup import csv import threadin ...
- Python 之scrapy框架58同城招聘爬取案例
一.项目目录结构: 代码如下: # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See docu ...
随机推荐
- WeQuant教程—1.3 利用回测工具降低交易风险
量化系统投入实际使用之前,人们会希望提前测试交易的效果.这个期间往往涉及代码的改动和参数的调整.最常见的做法是将历史数据输入量化系统,让量化系统根据既定的交易逻辑进行操作,观察和分析交易结果,找到问题 ...
- linux用户态和内核态理解
1.特权级 Intel x86架构的cpu一共有0-4四个特权级,0级最高,3级最低,硬件上在执行每条指令时都会对指令所具有的特权级做相应的检查.硬件已经提供了一套特权级使用的相关机制 ...
- mysql全量+增量备份脚本
cat xtrabackup_mysql.sh #!/bin/bash #title :xtrabackup_mysql.sh #description :backup mysql by using ...
- Java数组操作类
最近又重新在看慕课网的数据结构,然后把示例代码整理一下. public class Array<E> { private E[] data; private int count = 0; ...
- Java序列化的方式。
0.前言 本文主要对几种常见Java序列化方式进行实现.包括Java原生以流的方法进行的序列化.Json序列化.FastJson序列化.Protobuff序列化. 1.Java原生序列化 Java原生 ...
- dp --- 二维dp + 最大上升子序列
<传送门> 滑雪 Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 74477 Accepted: 27574 ...
- Python 入门(3):运算符
Python语言支持以下类型的运算符: 算术运算符 比较(关系)运算符 赋值运算符 逻辑运算符 位运算符 成员运算符 身份运算符 运算符优先级 Python算术运算符: + 加 两个对象相加 a + ...
- 文件包含lfi
CG-CTF web(文件包含漏洞) 参考链接:https://blog.csdn.net/qq_34072526/article/details/89431431 php://filter 的使用: ...
- 【LEETCODE】63、数组分类,hard级别,题目:85、4、84
package y2019.Algorithm.array.hard; /** * @ProjectName: cutter-point * @Package: y2019.Algorithm.arr ...
- (六)pdf的构成之文件体(pages对象)
页面树(pages) 通过页面树访问文档的页面,页面树定义PDF文档中的所有页面.树包含表示PDF文档页面的节点,可以是两种类型:中间节点和叶节点.中间节点也称为页面树节点,而叶节点称为页面对象.最简 ...