requests+lxml+xpath爬取电影天堂
1.导入相应的包
import requests
from lxml import etree
2.原始ur
url="https://www.dytt8.net/html/gndy/dyzz/list_23_1.html"
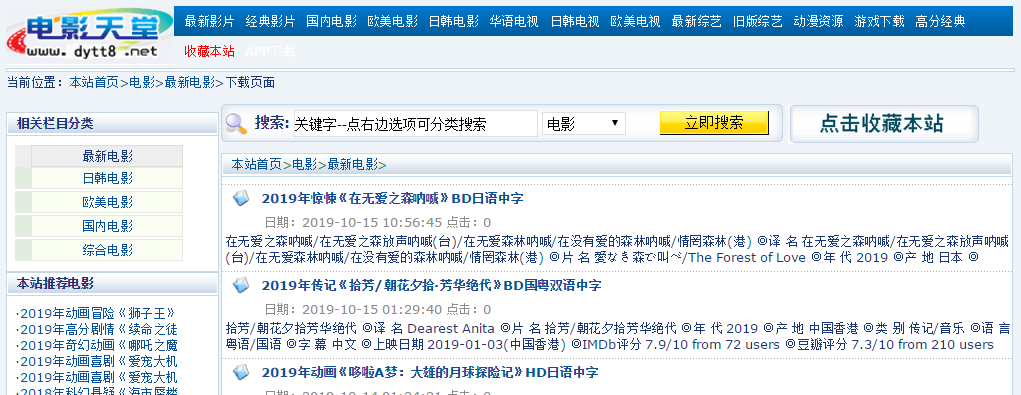
我们要爬取的是最新电影,在该界面中,我们发现,具体的信息存储在每个名字的链接中,因此我们要获取所有电影的链接才能得到电影的信息。同时我们观察url,发现
list_23_1,最后的1是页面位于第几页。右键点击其中一个电影的名字-检查。

我们发现,其部分连接位于具有class="tbspan"的table的<b>中,首先建立一个函数,用来得到所有的链接:
#用于补全url
base_url="https://www.dytt8.net"
def get_domain_urls(url):
response=requests.get(url=url,headers=headers)
text=response.text
html=etree.HTML(text)
#找到具有class="tbspan"的table下的所有a下面的href里面的值
detail_urls=html.xpath("//table[@class='tbspan']//a/@href")
#将url进行补全
detail_urls=map(lambda url:base_url+url,detail_urls)
return detail_urls
我们输出第1页中的所有url结果:
url="https://www.dytt8.net/html/gndy/dyzz/list_23_1.html"
for i in get_domain_urls(url):
print(i)
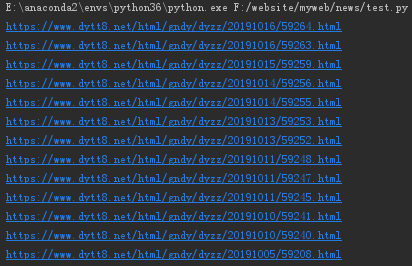
我们随便进入第一个链接:

按下F12,发现这些信息基本上都在div id="Zoom"中,接下来我们就可以对该界面进行解析。

def parse_detail_page(url):
movie={}
response=requests.get(url,headers=headers)
text=response.content.decode("GBK")
html=etree.HTML(text)
zoom=html.xpath("//div[@id='Zoom']")[0]
infos=zoom.xpath("//text()")
def parse_info(info,rule):
return info.replace(rule,"").lstrip()
for k,v in enumerate(infos):
if v.startswith("◎译 名"):
v=parse_info(v,"◎译 名").split("/")[0]
movie["name"]=v
elif v.startswith("◎产 地"):
v=parse_info(v,"◎产 地")
movie["country"]=v
elif v.startswith("◎类 别"):
v=parse_info(v,"◎类 别")
movie["category"]=v
elif v.startswith("◎豆瓣评分"):
v=parse_info(v,"◎豆瓣评分").split("/")[0]
movie["douban"]=v
elif v.startswith("◎导 演"):
v=parse_info(v,"◎导 演")
movie["director"]=v
elif v.startswith("◎主 演"):
v=parse_info(v,"◎主 演")
actors=[v]
for x in range(k+1,len(infos)):
actor=infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
movie["actors"]=actors
elif v.startswith("◎简 介"):
profile=""
for x in range(k+1,len(infos)):
tmp=infos[x].strip()
if tmp.startswith("【下载地址】"):
break
else:
profile=profile+tmp
movie["profile"]=profile
down_url=html.xpath("//td[@bgcolor='#fdfddf']/a/@href")
movie["down_url"]=down_url
return movie
最后将这两个整合进一个爬虫中:
def spider():
domain_url="https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html"
movies=[]
for i in range(1,2):
page=str(i)
url=domain_url.format(page)
detail_urls=get_domain_urls(url)
for detail_url in detail_urls:
movie = parse_detail_page(detail_url)
movies.append(movie)
print(movies)
运行爬虫,得到以下结果(在Json查看器中进行格式化):
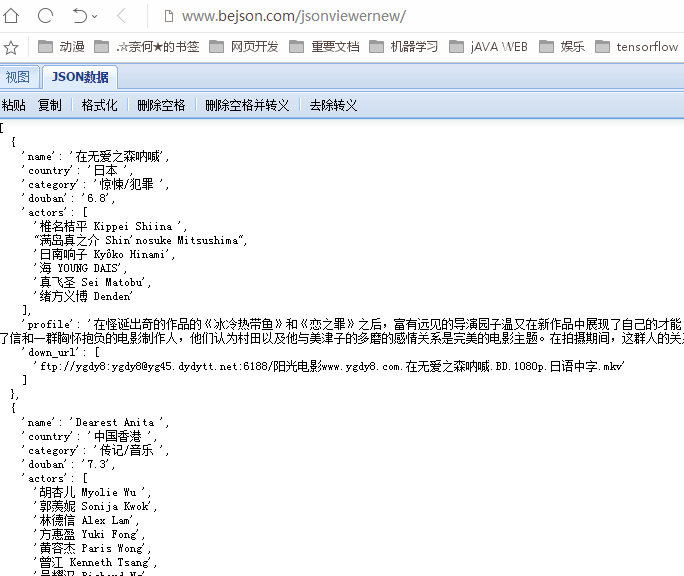
至此,一个简单的电影爬虫就完成了。
requests+lxml+xpath爬取电影天堂的更多相关文章
- requests+lxml+xpath爬取豆瓣电影
(1)lxml解析html from lxml import etree #创建一个html对象 html=stree.HTML(text) result=etree.tostring(html,en ...
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- python利用requests和threading模块,实现多线程爬取电影天堂最新电影信息。
利用爬到的数据,基于Django搭建的一个最新电影信息网站: n1celll.xyz (用的花生壳动态域名解析,服务器在自己的电脑上,纯属自娱自乐哈.) 今天想利用所学知识来爬取电影天堂所有最新电影 ...
- 14.python案例:爬取电影天堂中所有电视剧信息
1.python案例:爬取电影天堂中所有电视剧信息 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- '''======================== ...
- scrapy框架用CrawlSpider类爬取电影天堂.
本文使用CrawlSpider方法爬取电影天堂网站内国内电影分类下的所有电影的名称和下载地址 CrawlSpider其实就是Spider的一个子类. CrawlSpider功能更加强大(链接提取器,规 ...
- Python爬取电影天堂指定电视剧或者电影
1.分析搜索请求 一位高人曾经说过,想爬取数据,要先分析网站 今天我们爬取电影天堂,有好看的美剧我在上面都能找到,算是很全了. 这个网站的广告出奇的多,用过都知道,点一下搜索就会弹出个窗口,伴随着滑稽 ...
- requests结合xpath爬取豆瓣最新上映电影
# -*- coding: utf-8 -*- """ 豆瓣最新上映电影爬取 # ul = etree.tostring(ul, encoding="utf-8 ...
- requests+BeautifulSoup | 爬取电影天堂全站电影资源
import requests import urllib.request as ur from bs4 import BeautifulSoup import csv import threadin ...
随机推荐
- invalid comparison: java.util.ArrayList and java.lang.String解决
报错: Caused by: org.apache.ibatis.exceptions.PersistenceException: ### Error querying database. Cause ...
- VS Code配置Go语言开发环境(建议使用goland)
VS Code是微软开源的一款编辑器,插件系统十分的丰富.本文就介绍了如何使用VS Code搭建Go语言开发环境. VS Code配置Go语言开发环境 说在前面的话,Go语言是采用UTF8编码的,理论 ...
- aircrack-ng wifi密码破解
wifi密码破解 步骤1:查看网卡信息 ifconfig 找到你要用到的网卡 步骤2:启动网卡监听模式 airmon-ng start wlan0 我的是wlp2s0 步骤三:查看网卡变化 wlan0 ...
- [WP8.1]给Pivot的Header加上颜色
先上个效果图 以前想实现这个给Pivot加颜色时只找到8的,通过参考8的实现方式,8.1的实现如下,在Pivot的样式上做一些修改,如下图的红框处 另外如果要改Pivot的Header里文字的颜色又要 ...
- Linux被中断的系统调用
慢系统调用,指的是可能永远无法返回,从而使进程永远阻塞的系统调用,比如无客户连接时的accept.无输入时的read都属于慢速系统调用. 在Linux中,当阻塞于某个慢系统调用的进程捕获一个信号,则该 ...
- Rust入坑指南:坑主驾到
欢迎大家和我一起入坑Rust,以后我就是坑主,我主要负责在前面挖坑,各位可以在上面看,有手痒的也可以和我一起挖.这个坑到底有多深?我也不知道,我是抱着有多深就挖多深的心态来的,下面我先跳了,各位请随意 ...
- Cocos Creator 通用框架设计 —— 网络
在Creator中发起一个http请求是比较简单的,但很多游戏希望能够和服务器之间保持长连接,以便服务端能够主动向客户端推送消息,而非总是由客户端发起请求,对于实时性要求较高的游戏更是如此.这里我们会 ...
- 虚拟机上安装centos8.0
一.准备宿主机 为了培训Hadoop生态的部署和调优技术,需要准备3台虚拟机部署Hadoop集群环境,能够保证HA,即主要服务没有单点故障,可执行基本功能,完成小内存模式的参数调整. 1.1.准备安装 ...
- IT爱心求助站
最近发生的一些事情,让我对自己的专业有了另外一层认识. 小尹同学,你是做软件的是吗?能否帮我看一下我的电脑问题? 老同学,我的电脑安装一个软件这么都装不上,能否帮我看一下呢? 邻居你好,我的手机怎么没 ...
- badboy录制脚本
第一步:介绍badboy工具 1.1: 页面功能分析: 1. 界面视图,模拟浏览器,能够进行操作 2. 需要录制脚本的URL 3. 点击运行URL 4. Summary:运行的各指标,响应时间,成功事 ...