机器学习之KMeans聚类
零、学习生成测试数据
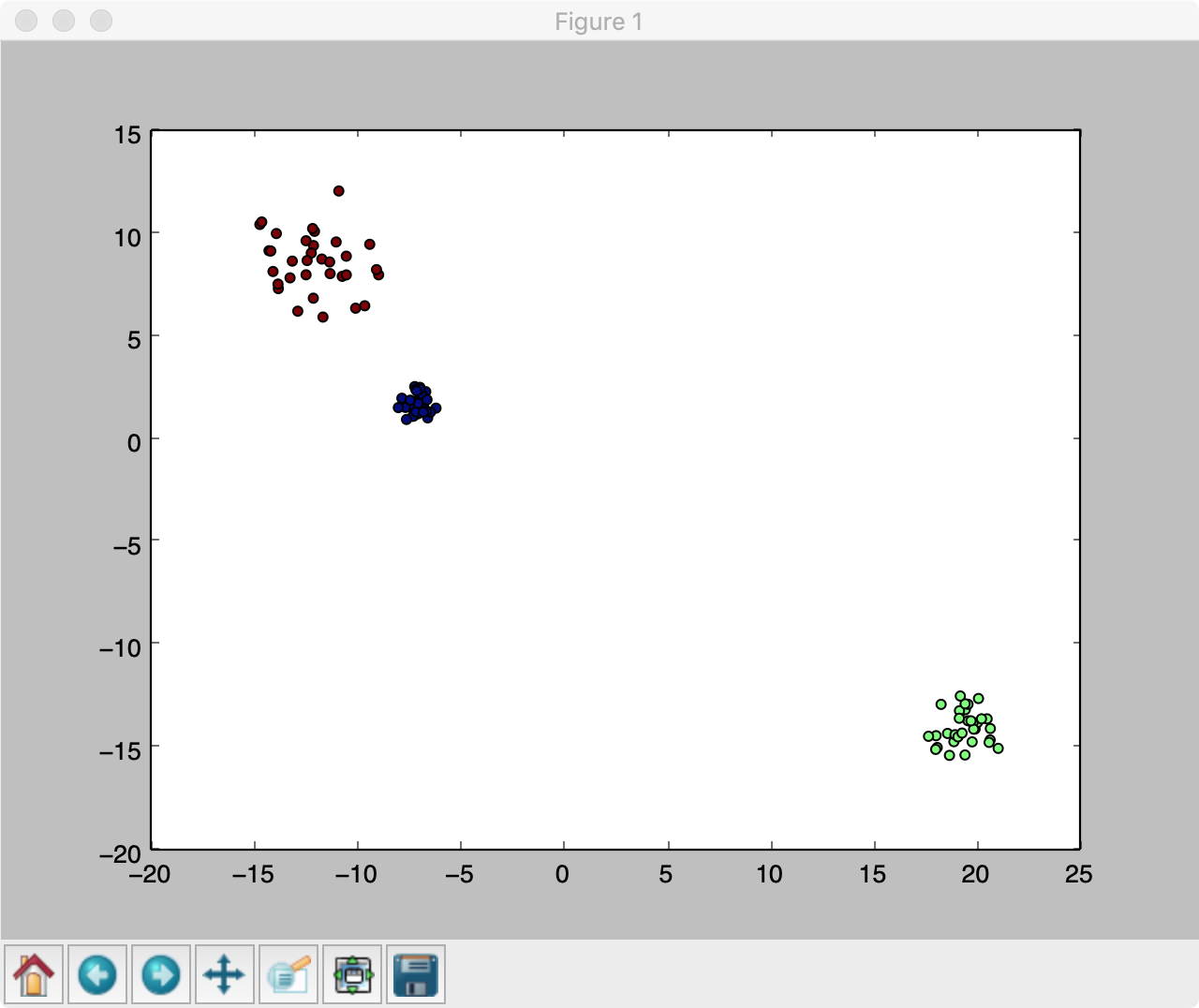
from sklearn.datasets import make_blobs
from matplotlib import pyplot
# create test data sets
datas, targets = make_blobs(
n_samples=100, #样本数量
n_features=2, #样本特征数
centers=3, #中心数量
cluster_std=[0.5, 1.0, 1.5], #方差
center_box=(-20.0, 20.0),
shuffle=True,
random_state=None
)
pyplot.scatter(datas[:,0],datas[:,1],c=targets)
pyplot.show()
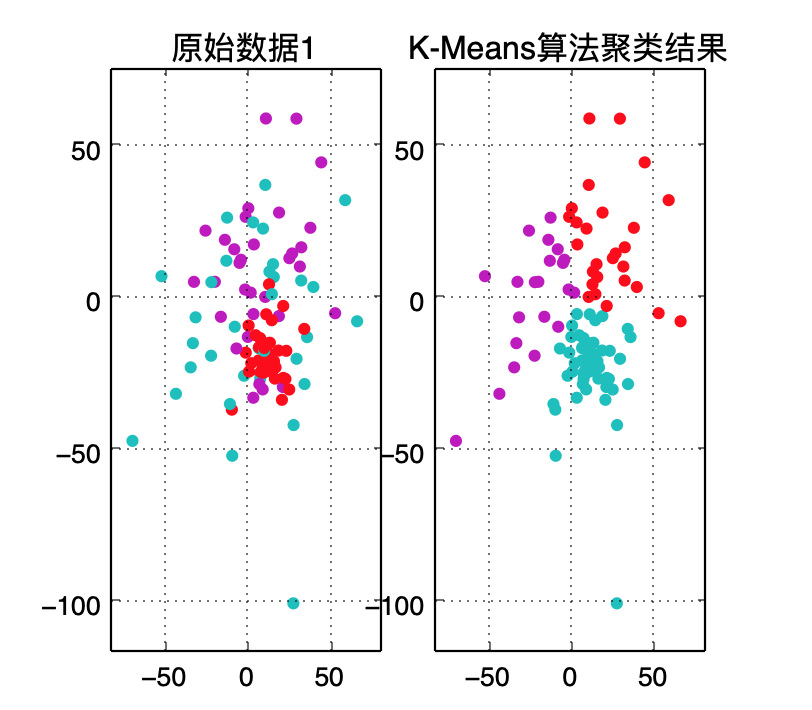
一、建立模型
km = KMeans(n_clusters=3, random_state=10)#创建模型(几个群组,随机种子数)
km.fit(datas, targets)#计算聚类
y_hat = km.predict(datas)#给这个样本估计最接近的分组(簇)
'''
ret = km.fit_predict(datas) #返回一个给数据每一项分组的组号列表
print km.get_params()#获取参数信息
km.set_params(keyname=value)
'''
其他常用函数

二、KMeans算法原理
机器学习之KMeans聚类的更多相关文章
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- 机器学习算法-K-means聚类
引文: k均值算法是一种聚类算法.所谓聚类.他是一种无监督学习,将类似的对象归到同一个蔟中.蔟内的对象越类似,聚类的效果越好. 聚类和分类最大的不同在于.分类的目标事先已知.而聚类则不一样. 由于其产 ...
- 菜鸟之路——机器学习之Kmeans聚类个人理解及Python实现
一些概念 相关系数:衡量两组数据相关性 决定系数:(R2值)大概意思就是这个回归方程能解释百分之多少的真实值. Kmeans聚类大致就是选择K个中心点.不断遍历更新中心点的位置.离哪个中心点近就属于哪 ...
- 机器学习: K-means 聚类
今天介绍机器学习里常见的一种无监督聚类算法,K-means.我们先来考虑在一个高维空间的一组数据集,S={x1,x2,...,xN}" role="presentation&quo ...
- 机器学习:K-Means聚类算法
本文来自同步博客. 前面几篇文章介绍了回归或分类的几个算法,它们的共同点是训练数据包含了输出结果,要求算法能够通过训练数据掌握规律,用于预测新输入数据的输出值.因此,回归算法或分类算法被称之为监督学习 ...
- 机器学习中K-means聚类算法原理及C语言实现
本人以前主要focus在传统音频的软件开发,接触到的算法主要是音频信号处理相关的,如各种编解码算法和回声消除算法等.最近切到语音识别上,接触到的算法就变成了各种机器学习算法,如GMM等.K-means ...
- 【机器学习】K-means聚类算法与EM算法
初始目的 将样本分成K个类,其实说白了就是求一个样本例的隐含类别y,然后利用隐含类别将x归类.由于我们事先不知道类别y,那么我们首先可以对每个样例假定一个y吧,但是怎么知道假定的对不对呢?怎样评价假定 ...
- Python机器学习算法 — K-Means聚类
K-Means简介 步,直到每个簇的中心基本不再变化: 6)将结果输出. K-Means的说明 如图所示,数据样本用圆点表示,每个簇的中心点用叉叉表示: (a)刚开始时是原始数据,杂乱无章 ...
- 机器学习之--kmeans聚类简单算法实例
import numpy as np import sklearn.datasets #加载原数据 import matplotlib.pyplot as plt import random #点到各 ...
随机推荐
- 【Mybatis】CDATA
忽视内部尖括号那些东西
- [NOIP2015]联合权值
1.题面 2.总结 第一次回忆一下当年的题目.但是这道题已经做烂了,只是看还记得树遍历会写么. 然后我写了一下,有点费劲,交上去之后只有70,比较尴尬,看了下去年5月写的代码,发现完全不是一个感觉啊. ...
- 洛谷p3384【模板】树链剖分题解
洛谷p3384 [模板]树链剖分错误记录 首先感谢\(lfd\)在课上调了出来\(Orz\) \(1\).以后少写全局变量 \(2\).线段树递归的时候最好把左右区间一起传 \(3\).写\(dfs\ ...
- [清华集训2017]小 Y 和地铁(神奇思路,搜索,剪枝,树状数组)
世界上最不缺的就是好题. 首先考虑暴搜.(还有什么题是从这东西推到正解的……) 首先单独一个换乘站明显没用,只用考虑一对对的换乘站. 那么有八种情况:(从题解偷图) 然后大力枚举每个换 ...
- [LeetCode] 780. Reaching Points 到达指定点
A move consists of taking a point (x, y) and transforming it to either (x, x+y) or (x+y, y). Given a ...
- [LeetCode] 723. Candy Crush 糖果消消乐
This question is about implementing a basic elimination algorithm for Candy Crush. Given a 2D intege ...
- [LeetCode] 25. Reverse Nodes in k-Group 每k个一组翻转链表
Given a linked list, reverse the nodes of a linked list k at a time and return its modified list. k ...
- portal项目启动问题
错误信息: Disconnected from the target VM, address: '127.0.0.1:58909', transport: 'socket' Process finis ...
- python读写符号的含义
r 打开只读文件,该文件必须存在. r+ 打开可读写的文件,该文件必须存在. w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失.若文件不存在则建立该文件. w+ 打开可读写文件,若文件 ...
- eclipse web 新建servers时选中tomcat版本后不能继续操作,next是灰色.
解决方案: 1.退出 eclipse2.到[工程目录下]/.metadata/.plugins/org.eclipse.core.runtime3.把org.eclipse.wst.server.co ...