分布式任务队列 Celery —— 详解工作流
目录
前文列表
前言
Celery 的工作流具有非常浓厚的函数式编程风格,在理解工作流之前,我们需要对「签名」、「偏函数」以及「回调函数」有所了解。
文中所用的示例代码紧接前文,其中 taks.py 模块有少量修改。
# filename: tasks.py
from proj.celery import app
@app.task
def add(x, y, debug=False):
if debug:
print("x: %s; y: %s" % (x, y))
return x + y
@app.task
def log(msg):
return "LOG: %s" % msg任务签名 signature
使用 Celery Signature 签名(Subtask 子任务),可生成一个特殊的对象——任务签名。任务签名和函数签名类似,除了包含函数的常规声明信息(形参、返回值)之外,还包含了执行该函数所需要的调用约定和(全部/部分)实参列表。你可以在任意位置直接使用该签名,甚至不需要考虑实参传递的问题(实参可能在生成签名时就已经包含)。可见,任务签名的这种特性能够让不同任务间的组合、嵌套、调配变得简单。
任务签名支持「直接执行」和「Worker 执行」两种方式:
- 生成任务签名并直接执行:签名在当前进程中执行
>>> from celery import signature
>>> from proj.task.tasks import add
# 方式一
>>> signature('proj.task.tasks.add', args=(2, 3), countdown=10)
proj.task.tasks.add(2, 3)
>>> s_add = signature('proj.task.tasks.add', args=(2, 3), countdown=10)
>>> s_add()
5
# 方式二
>>> add.signature((3, 4), countdown=10)
proj.task.tasks.add(3, 4)
>>> s_add = add.signature((3, 4), countdown=10)
>>> s_add()
7
# 方式三
>>> add.subtask((3, 4), countdown=10)
proj.task.tasks.add(3, 4)
>>> s_add = add.subtask((3, 4), countdown=10)
>>> s_add()
7
# 方式四
>>> add.s(3, 4)
proj.task.tasks.add(3, 4)
>>> s_add = add.s(3, 4)
>>> s_add()
7- 生成任务签名并交由 Worker 执行:签名在 Worker 服务进程中执行
# 调用 delay/apply_async 方法将签名加载到 Worker 中执行
>>> s_add = add.s(2, 2)
>>> s_add.delay()
<AsyncResult: 75be3776-b36b-458e-9a89-512121cdaa32>
>>> s_add.apply_async()
<AsyncResult: 4f1bf824-331a-42c0-9580-48b5a45c2f7a>
>>> s_add = add.s(2, 2)
>>> s_add.delay(debug=True) # 任务签名支持动态传递实参
<AsyncResult: 1a1c97c5-8e81-4871-bb8d-def39eb539fc>
>>> s_add.apply_async(kwargs={'debug': True})
<AsyncResult: 36d10f10-3e6f-46c4-9dde-d2eabb24c61c>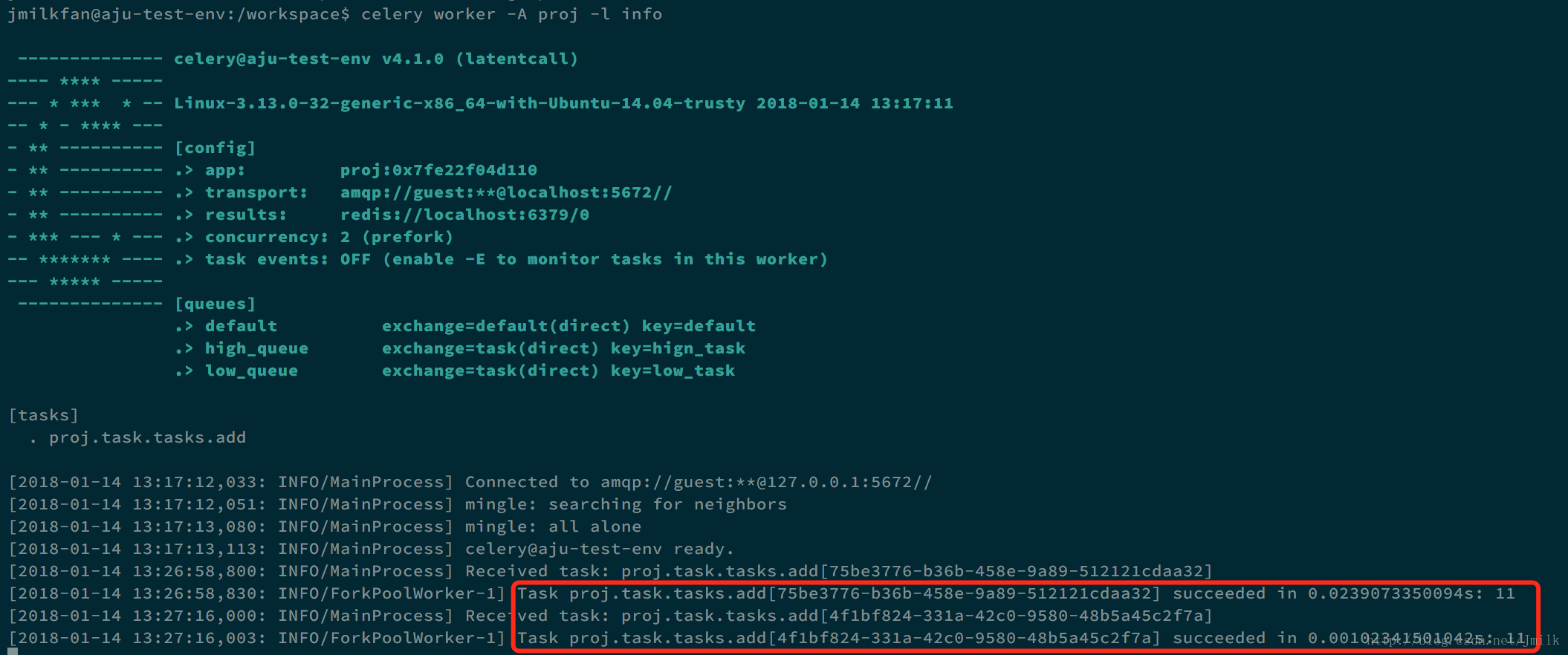
偏函数
偏函数(Partial Function Application,PFA):将拥有任意形参数量(顺序)的函数转化为另一个已经包含了任意实参的新的函数。简单来说,就是返回一个新的函数对象并将函数中的某些形参,固化为实参。从某个角度来看类似函数的默认参数特性,但也并不全是。因为默认参数列表是持久不变的,而 PFA 中,固化的参数列表能够任意定义。对于同一个函数,你可以得到关于它的许多偏函数,而且每一个偏函数的固化参数列表都可以不同。e.g.
# 普通偏函数:
>>> from functools import partial
>>> add_1 = partial(add, 1)
>>> add_1(2)
3
# add_1(x) == add(1, x)
>>> int_base2 = partial(int, base=2)
>>> int_base2.__doc__ = ‘Convert base 2 string to an int.'
>>> int_base2('10010')
18
int_base2(x) == int(x, base=2)Celery 中的偏函数实际上就是固化了部分参数的任务签名。e.g.
# Celery 偏函数
>>> add.s(1)
proj.task.tasks.add(1)
>>> s_add_1 = add.s(1)
>>> s_add_1(10)
11
>>> s_add_1.delay(20)
<AsyncResult: eb88ad9c-31f6-484f-8fd5-735a498aedbc>回调函数
回调函数就是一个通过函数指针(函数名)来调用的函数。如果你把函数指针作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就称之为回调。回调函数在发生特定事件或满足指定条件时被回调,从而对该事件或条件进行响应。
Celery 中的回调函数依旧是一个任务签名,而触发回调的事件或条件就是「任务执行成功」和「任务执行失败」。
调用 apply_async 方法的 link/link_error 来指定回调函数。e.g.
- 任务执行成功回调:
# 默认的,回调函数的实参来自于上一个任务的执行结果
>>> from proj.task.tasks import add, log
>>> result = add.apply_async(args=(1, 2), link=log.s())
>>> result.get()
3
- 任务执行失败回调:
>>> result = add.apply_async(args=(1, 2), link_error=log.s())
>>> result.status
u'SUCCESS'
>>> result.get()
3
如果你希望回调函数的实参不来自于上一个任务的结果,那么你可以将回调函数的实参设置为 immutable(不可变的):
>>> add.apply_async((2, 2), link=log.signature(args=('Task SUCCESS', ), immutable=True))
<AsyncResult: c136ad34-68b4-49a9-8462-84ac8cd75810>
# 简易写法
>>> add.apply_async((2, 2), link=log.si('Task SUCCESS'))
<AsyncResult: bbb35212-5a6b-427b-a6a6-d1eb5359365e>
当然了,回调函数和偏函数可以结合使用,拥有了更好的灵活性:
>>> result = add.apply_async((2, 2), link=add.s(2))
NOTE:需要注意的是,回调函数的结果不会被返回,所以使用 Result.get 只也能获取第一个任务的结果。
>>> result = add.apply_async((2, 2), link=add.s(2))
>>> result.get()
4Celery 工作流
group 任务组
任务组函数接收一组任务签名列表,返回一个新的任务签名——签名组,调用签名组会并行执行其包含的所有任务签名,并返回所有结果的列表。常用于一次性创建多个任务。
>>> from celery import group
>>> from proj.task.tasks import add
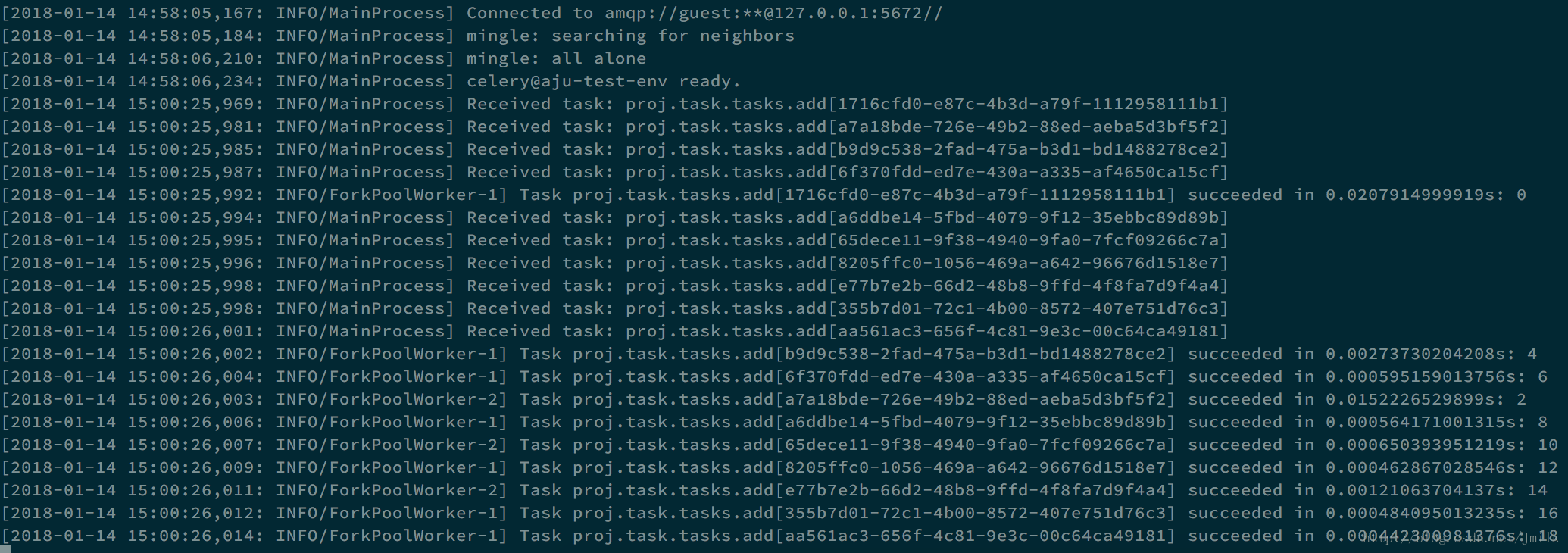
>>> add_group_sig = group(add.s(i, i) for i in range(10))
>>> result = add_group_sig.delay()
>>> result.get()
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
# 返回多个结果
>>> result.results
[<AsyncResult: 1716cfd0-e87c-4b3d-a79f-1112958111b1>,
<AsyncResult: a7a18bde-726e-49b2-88ed-aeba5d3bf5f2>,
<AsyncResult: b9d9c538-2fad-475a-b3d1-bd1488278ce2>,
<AsyncResult: 6f370fdd-ed7e-430a-a335-af4650ca15cf>,
<AsyncResult: a6ddbe14-5fbd-4079-9f12-35ebbc89d89b>,
<AsyncResult: 65dece11-9f38-4940-9fa0-7fcf09266c7a>,
<AsyncResult: 8205ffc0-1056-469a-a642-96676d1518e7>,
<AsyncResult: e77b7e2b-66d2-48b8-9ffd-4f8fa7d9f4a4>,
<AsyncResult: 355b7d01-72c1-4b00-8572-407e751d76c3>,
<AsyncResult: aa561ac3-656f-4c81-9e3c-00c64ca49181>] (并行执行)
chain 任务链
任务链函数接收若干个任务签名,并返回一个新的任务签名——链签名。调用链签名会并串行执行其所含有的任务签名,每个任务签名的执行结果都会作为第一个实参传递给下一个任务签名,最后只返回一个结果。
>>> from celery import chain
>>> from proj.task.tasks import add
>>> add_chain_sig = chain(add.s(1, 2), add.s(3))
# 精简语法
>>> add_chain_sig = (add.s(1, 2) | add.s(3))
>>> result = add_chain_sig.delay() # ((1 + 2) + 3)
>>> result.status
u’SUCCESS’
>>> result.get()
6
# 仅返回最终结果
>>> result.results
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'AsyncResult' object has no attribute 'results'
# 结合偏函数
>>> add_chain_sig = chain(add.s(1), add.s(3))
>>> result = add_chain_sig.delay(3) # ((3 + 1) + 3)
>>> result.get()
7(串行执行)

chord 复合任务
复合任务函数生成一个任务签名时,会先执行一个组签名(不支持链签名),等待任务组全部完成时执行一个回调函数。
>>> from proj.task.tasks import add, log
>>> from celery import chord, group, chain
>>> add_chord_sig = chord(group(add.s(i, i) for i in range(10)), log.s())
>>> result = add_chord_sig.delay()
>>> result.status
u'SUCCESS'
>>> result.get()
u'LOG: [0, 2, 4, 6, 8, 10, 12, 16, 14, 18]'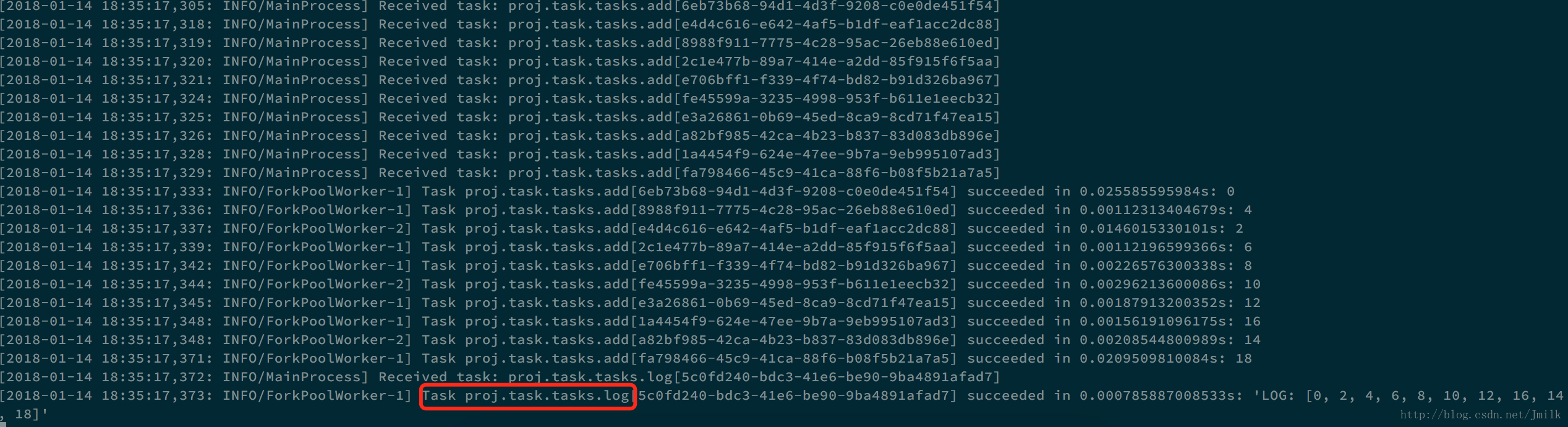
可见任务组函数依旧是并行执行的,但任务组和回调函数时串行执行的,所以 chord 被称为复合任务函数。
chunks 任务块
任务块函数能够让你将需要处理的大量对象分为分成若干个任务块,如果你有一百万个对象,那么你可以创建 10 个任务块,每个任务块处理十万个对象。有些人可能会担心,分块处理会导致并行性能下降,实际上,由于避免了消息传递的开销,因此反而会大大的提高性能。
>>> add_chunks_sig = add.chunks(zip(range(100), range(100)), 10)
>>> result = add_chunks_sig.delay()
>>> result.get()
[[0, 2, 4, 6, 8, 10, 12, 14, 16, 18],
[20, 22, 24, 26, 28, 30, 32, 34, 36, 38],
[40, 42, 44, 46, 48, 50, 52, 54, 56, 58],
[60, 62, 64, 66, 68, 70, 72, 74, 76, 78],
[80, 82, 84, 86, 88, 90, 92, 94, 96, 98],
[100, 102, 104, 106, 108, 110, 112, 114, 116, 118],
[120, 122, 124, 126, 128, 130, 132, 134, 136, 138],
[140, 142, 144, 146, 148, 150, 152, 154, 156, 158],
[160, 162, 164, 166, 168, 170, 172, 174, 176, 178],
[180, 182, 184, 186, 188, 190, 192, 194, 196, 198]]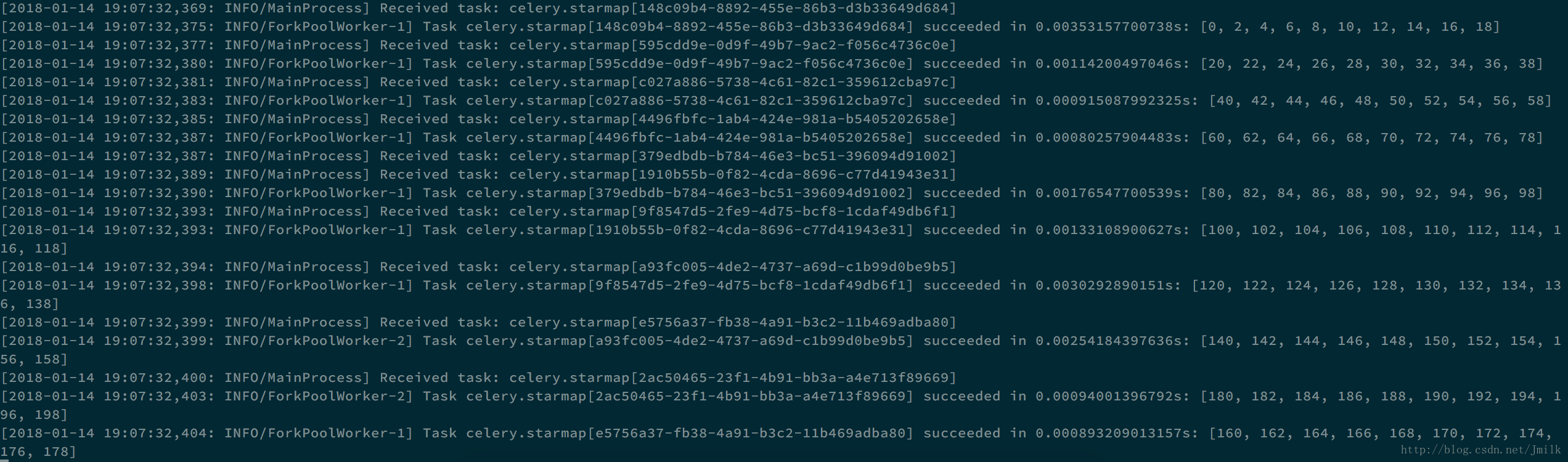
map/starmap 任务映射
映射函数,与 Python 函数式编程中的 map 内置函数相似。都是将序列对象中的元素作为实参依次传递给一个特定的函数。
map 和 starmap 的区别在于,前者的参数只有一个,后者支持的参数有多个。
>>> add.starmap(zip(range(10), range(100)))
[proj.task.tasks.add(*x) for x in [(0, 0), (1, 1), (2, 2), (3, 3), (4, 4), (5, 5), (6, 6), (7, 7), (8, 8), (9, 9)]]
>>> result = add.starmap(zip(range(10), range(100))).delay()
>>> result.get()
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
如果使用 map 来处理 add 函数会报错,因为 map 只能支持一个参数的传入。
>>> add.map(zip(range(10), range(100)))
[proj.task.tasks.add(x) for x in [(0, 0), (1, 1), (2, 2), (3, 3), (4, 4), (5, 5), (6, 6), (7, 7), (8, 8), (9, 9)]]
>>> result = add.map(zip(range(10), range(100))).delay(1)
>>> result.status
u’FAILURE'
分布式任务队列 Celery —— 详解工作流的更多相关文章
- 分布式任务队列 Celery —— Task对象
转载至 JmilkFan_范桂飓:http://blog.csdn.net/jmilk 目录 目录 前文列表 前言 Task 的实例化 任务的名字 任务的绑定 任务的重试 任务的请求上下文 任务的继 ...
- 分布式任务队列 Celery —— 深入 Task
目录 目录 前文列表 前言 Task 的实例化 任务的名字 任务的绑定 任务的重试 任务的请求上下文 任务的继承 前文列表 分布式任务队列 Celery 分布式任务队列 Celery -- 详解工作流 ...
- 分布式任务队列 Celery —— 应用基础
目录 目录 前文列表 前言 Celery 的周期定时任务 Celery 的同步调用 Celery 结果储存 Celery 的监控 Celery 的调试 前文列表 分布式任务队列 Celery 分布式任 ...
- [源码分析] 分布式任务队列 Celery 之 发送Task & AMQP
[源码分析] 分布式任务队列 Celery 之 发送Task & AMQP 目录 [源码分析] 分布式任务队列 Celery 之 发送Task & AMQP 0x00 摘要 0x01 ...
- [源码分析]并行分布式任务队列 Celery 之 子进程处理消息
[源码分析]并行分布式任务队列 Celery 之 子进程处理消息 0x00 摘要 Celery是一个简单.灵活且可靠的,处理大量消息的分布式系统,专注于实时处理的异步任务队列,同时也支持任务调度.在前 ...
- celery详解
目录 Celery详解 1.背景 2.形象比喻 3.celery具体介绍 3.1 Broker 3.2 Backend 4.使用 4.1 celery架构 4.2 安装redis+celery 4.3 ...
- 分布式任务队列 Celery
目录 目录 前言 简介 Celery 的应用场景 架构组成 Celery 应用基础 前言 分布式任务队列 Celery,Python 开发者必备技能,结合之前的 RabbitMQ 系列,深入梳理一下 ...
- [源码解析] 分布式任务队列 Celery 之启动 Consumer
[源码解析] 分布式任务队列 Celery 之启动 Consumer 目录 [源码解析] 分布式任务队列 Celery 之启动 Consumer 0x00 摘要 0x01 综述 1.1 kombu.c ...
- [源码解析] 并行分布式任务队列 Celery 之 Task是什么
[源码解析] 并行分布式任务队列 Celery 之 Task是什么 目录 [源码解析] 并行分布式任务队列 Celery 之 Task是什么 0x00 摘要 0x01 思考出发点 0x02 示例代码 ...
随机推荐
- C语言几种常用的排序算法
/* ============================================================================= 相关知识介绍(所有定义只为帮助读者理解 ...
- 作为测试人员,不能不懂的adb命令和操作
刚从web转到app测试,很多知识需要补充,记录一下 1.概念 其实我们口中所讲的adb是个泛指,这其中有两个工具——Fastboot和ADB fastboot 快速启动,usb链接数据线的一 ...
- 从标准输入读取一行数组并保存(用的是字符串分割函数strtok_s() )
首先介绍字符串分割函数: char *strtok_s( char *strToken, //字符串包含一个标记或一个以上的标记. const char *strDelimit, //分隔符的设置 c ...
- vs开发之工程属性
1.建立工程 最好使用自己创建工程 然后把代码移过去 2.不要使用别人建立的工程直接导入(差异比较大的话),后面32位 64位 配置属性 可能造成冲突 3.冲突了 还需要重新做 上面 1
- 【hiho1041】国庆出游 dfs+bitset
题目大意:给定一棵 N 个节点的有根树,1 号节点为根节点,现遍历整棵树,要求每条边仅被经过两次,问是否存在一种特定的遍历方式使得 dfs 序中节点的相对前后关系符合给定的顺序. 题解: 首先,由于要 ...
- css不常见属性之pointer-events
MDN 上介绍为 CSS 属性指定在什么情况下 (如果有) 某个特定的图形元素可以成为鼠标事件的 target.pointer-events 属性值有: /* Keyword values */ po ...
- ArrayList为什么是线程不安全的
首先需要了解什么是线程安全:线程安全就是说多线程访问同一代码(对象.变量等),不会产生不确定的结果. 既然说ArrayList是线程不安全的,那么在多线程中操作一个ArrayList对象,则会出现不确 ...
- Tronado【第1篇】:tronado的简单使用以及使用
Tronado Tornado 是 FriendFeed 使用的可扩展的非阻塞式 web 服务器及其相关工具的开源版本.这个 Web 框架看起来有些像web.py 或者 Google 的 webapp ...
- CodeForces-585B(BFS)
链接: https://vjudge.net/problem/CodeForces-585B 题意: The mobile application store has a new game calle ...
- 美团点评SQL优化工具SQLAdvisor开源快捷部署
美团点评SQL优化工具SQLAdvisor开源快捷部署 git clone https://github.com/Meituan-Dianping/SQLAdvisor.gityum install ...