机器学习聚类算法之DBSCAN
一、概念
DBSCAN是一种基于密度的聚类算法,DBSCAN需要两个参数,一个是以P为中心的邻域半径;另一个是以P为中心的邻域内的最低门限点的数量,即密度。
优点:
1、不需要提前设定分类簇数量,分类结果更合理;
2、可以有效的过滤干扰。
缺点:
1、对高维数据处理效果较差;
2、算法复杂度较高,资源消耗大于K-means。
二、计算
1、默认使用第一个点作为初始中心;
2、通过计算点到中心的欧氏距离和领域半径对比,小于则是邻域点;
3、计算完所有点,统计邻域内点数量,小于于最低门限点数量则为噪声;
4、循环统计各个点的邻域点数,只要一直大于最低门限点数量,则一直向外扩展,直到不再大于。
5、一个簇扩展完成,会从剩下的点中重复上述操作,直到所有点都被遍历。
三、实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt cs = ['black', 'blue', 'brown', 'red', 'yellow', 'green'] class NpCluster(object):
def __init__(self):
self.key = []
self.value = [] def append(self, data):
if str(data) in self.key:
return
self.key.append(str(data))
self.value.append(data) def exist(self, data):
if str(data) in self.key:
return True
return False def __len__(self):
return len(self.value) def __iter__(self):
self.times = 0
return self def __next__(self):
try:
ret = self.value[self.times]
self.times += 1
return ret
except IndexError:
raise StopIteration() def create_sample():
np.random.seed(10) # 随机数种子,保证随机数生成的顺序一样
n_dim = 2
num = 100
a = 3 + 5 * np.random.randn(num, n_dim)
b = 30 + 5 * np.random.randn(num, n_dim)
c = 60 + 10 * np.random.randn(1, n_dim)
data_mat = np.concatenate((np.concatenate((a, b)), c))
ay = np.zeros(num)
by = np.ones(num)
label = np.concatenate((ay, by))
return {'data_mat': list(data_mat), 'label': label} def region_query(dataset, center_point, eps):
result = NpCluster()
for point in dataset:
if np.sqrt(sum(np.power(point - center_point, 2))) <= eps:
result.append(point)
return result def dbscan(dataset, eps, min_pts):
noise = NpCluster()
visited = NpCluster()
clusters = []
for point in dataset:
cluster = NpCluster()
if not visited.exist(point):
visited.append(point)
neighbors = region_query(dataset, point, eps)
if len(neighbors) < min_pts:
noise.append(point)
else:
cluster.append(point)
expand_cluster(visited, dataset, neighbors, cluster, eps, min_pts)
clusters.append(cluster)
for data in clusters:
print(data.value)
plot_data(np.mat(data.value), cs[clusters.index(data)])
if noise.value:
plot_data(np.mat(noise.value), 'green')
plt.show() def plot_data(samples, color, plot_type='o'):
plt.plot(samples[:, 0], samples[:, 1], plot_type, markerfacecolor=color, markersize=14) def expand_cluster(visited, dataset, neighbors, cluster, eps, min_pts):
for point in neighbors:
if not visited.exist(point):
visited.append(point)
point_neighbors = region_query(dataset, point, eps)
if len(point_neighbors) >= min_pts:
for expand_point in point_neighbors:
if not neighbors.exist(expand_point):
neighbors.append(expand_point)
if not cluster.exist(point):
cluster.append(point) init_data = create_sample()
dbscan(init_data['data_mat'], 10, 3)
聚类结果:
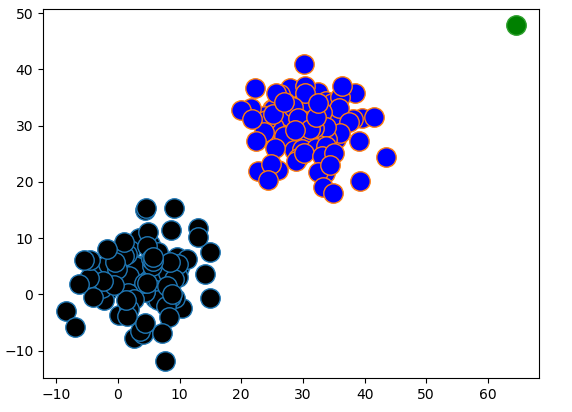
可以看到,点被很好的聚类为两个簇,右上角是噪声。
机器学习聚类算法之DBSCAN的更多相关文章
- 机器学习 - 算法 - 聚类算法 K-MEANS / DBSCAN算法
聚类算法 概述 无监督问题 手中无标签 聚类 将相似的东西分到一组 难点 如何 评估, 如何 调参 基本概念 要得到的簇的个数 - 需要指定 K 值 质心 - 均值, 即向量各维度取平均 距离的度量 ...
- 机器学习聚类算法之K-means
一.概念 K-means是一种典型的聚类算法,它是基于距离的,是一种无监督的机器学习算法. K-means需要提前设置聚类数量,我们称之为簇,还要为之设置初始质心. 缺点: 1.循环计算点到质心的距离 ...
- Standford机器学习 聚类算法(clustering)和非监督学习(unsupervised Learning)
聚类算法是一类非监督学习算法,在有监督学习中,学习的目标是要在两类样本中找出他们的分界,训练数据是给定标签的,要么属于正类要么属于负类.而非监督学习,它的目的是在一个没有标签的数据集中找出这个数据集的 ...
- 【Python机器学习实战】聚类算法(1)——K-Means聚类
实战部分主要针对某一具体算法对其原理进行较为详细的介绍,然后进行简单地实现(可能对算法性能考虑欠缺),这一部分主要介绍一些常见的一些聚类算法. K-means聚类算法 0.聚类算法算法简介 聚类算法算 ...
- 【转】常用聚类算法(一) DBSCAN算法
原文链接:http://www.cnblogs.com/chaosimple/p/3164775.html#undefined 1.DBSCAN简介 DBSCAN(Density-Based Spat ...
- 常用聚类算法(一) DBSCAN算法
1.DBSCAN简介 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度 ...
- 关于k-means聚类算法的matlab实现
在数据挖掘中聚类和分类的原理被广泛的应用. 聚类即无监督的学习. 分类即有监督的学习. 通俗一点的讲就是:聚类之前是未知样本的分类.而是根据样本本身的相似性进行划分为相似的类簇.而分类 是已知样本分类 ...
- 简单易学的机器学习算法—基于密度的聚类算法DBSCAN
简单易学的机器学习算法-基于密度的聚类算法DBSCAN 一.基于密度的聚类算法的概述 我想了解下基于密度的聚类算法,熟悉下基于密度的聚类算法与基于距离的聚类算法,如K-Means算法之间的区别. ...
- 简单易学的机器学习算法——基于密度的聚类算法DBSCAN
一.基于密度的聚类算法的概述 最近在Science上的一篇基于密度的聚类算法<Clustering by fast search and find of density peaks> ...
随机推荐
- 全面解读PHP-JS和jQuery
一.变量的定义 1.未使用值来申明的变量,其值为 undefined. 2.如果重新声明一个变量,该变量的值不会丢失. //定义一个变量 var str = 'hello'; //重新申明 var s ...
- leetcode 56区间合并
class Solution { public: static bool cmp(vector<int> a,vector<int> b){ ]<b[]; } vecto ...
- jquery.validate.js使用之自定义表单验证规则
jquery.validate.js使用之自定义表单验证规则,下面列出了一些常用的验证法规则 jquery.validate.js演示查看 jquery validate强大的jquery表单验证插件 ...
- Java-Logger日志
<转载于--https://www.cnblogs.com/yorickLi/p/6158405.html> Java中关于日志系统的API,在 java.util.logging 包中, ...
- JavaScript日常学习5
JavaScript字符串属性和方法 eg :var txt = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"; var sln = txt.length; ...
- 如何利用Nginx的缓冲、缓存优化提升性能
使用缓冲释放后端服务器 反向代理的一个问题是代理大量用户时会增加服务器进程的性能冲击影响.在大多数情况下,可以很大程度上能通过利用Nginx的缓冲和缓存功能减轻. 当代理到另一台服务器,两个不同的连接 ...
- django QueryDict 类型
如果没有值,返回默认值的写法 允许有多个同名的值,但是需要用getlist 访问. 如果用常规的访问只能访问到最后一个值.
- 【CUDA开发】CUDA从入门到精通
CUDA从入门到精通(零):写在前面 在老板的要求下,本博主从2012年上高性能计算课程开始接触CUDA编程,随后将该技术应用到了实际项目中,使处理程序加速超过1K,可见基于图形显示器的并行计算对于追 ...
- 【Linux 网络编程】常用套接字类型
常用套接字类型<1>流式套接字(SOCK_STREAM)---TCP 提供面向连接的.可靠的传输服务,数据无差错,无重复的发送, 且按发送顺序接收.<2>数 ...
- Java static基本认知
一. static的用途 在Java编程思想中有这么一句话:“static方法就是没有this的方法.在static方法内部不能调用非静态方法,反过来是可以的.而且可以在没有创建任何对象的前提下,仅仅 ...