python pytorch numpy DNN 线性回归模型
1、直接奉献代码,后期有入门更新,之前一直在学的是TensorFlow,
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np x_data = np.arange(-2*np.pi,2*np.pi,0.1).reshape(-1,1)
y_data = np.sin(x_data).reshape(-1,1) x = torch.unsqueeze(torch.linspace(-5, 5, 100), dim=1) # 将1维的数据转换为2维数据
# y = x.pow(2) + 0.2 * torch.rand(x.size())
y = torch.cos(x)
# 将tensor置入Variable中
x, y = Variable(torch.from_numpy(x_data)).float(), Variable(torch.from_numpy(y_data)).float()
print(x.shape,y.shape) # plt.scatter(x.data.numpy(), y.data.numpy())
# plt.show() # 定义一个构建神经网络的类
class Net(torch.nn.Module): # 继承torch.nn.Module类
def __init__(self):
super(Net, self).__init__() # 获得Net类的超类(父类)的构造方法
# 定义神经网络的每层结构形式
# 各个层的信息都是Net类对象的属性
self.hidden = torch.nn.Linear(1, 10) # 隐藏层线性输出
self.centre_1 = torch.nn.Linear(10,20)
self.predict = torch.nn.Linear(20, 1) # 输出层线性输出 # 将各层的神经元搭建成完整的神经网络的前向通路
def forward(self, x):
x = F.tanh(self.hidden(x)) # 对隐藏层的输出进行relu激活
x_1 = F.tanh(self.centre_1(x))
x =F.tanh(self.predict(x_1))
return x # 定义神经网络 net = Net()
print(net) # 打印输出net的结构 # 定义优化器和损失函数
optimizer = torch.optim.SGD(net.parameters(), lr=0.5) # 传入网络参数和学习率
loss_function = torch.nn.MSELoss() # 最小均方误差
acc = lambda y1,y2: np.sqrt(np.sum(y1**2+y2**2)/len(y1)) # 神经网络训练过程
plt.ion() # 动态学习过程展示
plt.show() for t in range(100):
prediction = net(x) # 把数据x喂给net,输出预测值
loss = loss_function(prediction, y) # 计算两者的误差,要注意两个参数的顺序
optimizer.zero_grad() # 清空上一步的更新参数值
loss.backward() # 误差反相传播,计算新的更新参数值
optimizer.step() # 将计算得到的更新值赋给net.parameters() # 可视化训练过程
if (t + 1) % 2 == 0:
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=2)
aucc = acc(prediction.data.numpy(),y.data.numpy())
print("loss={} aucc={}".format(loss.data.numpy(),aucc))
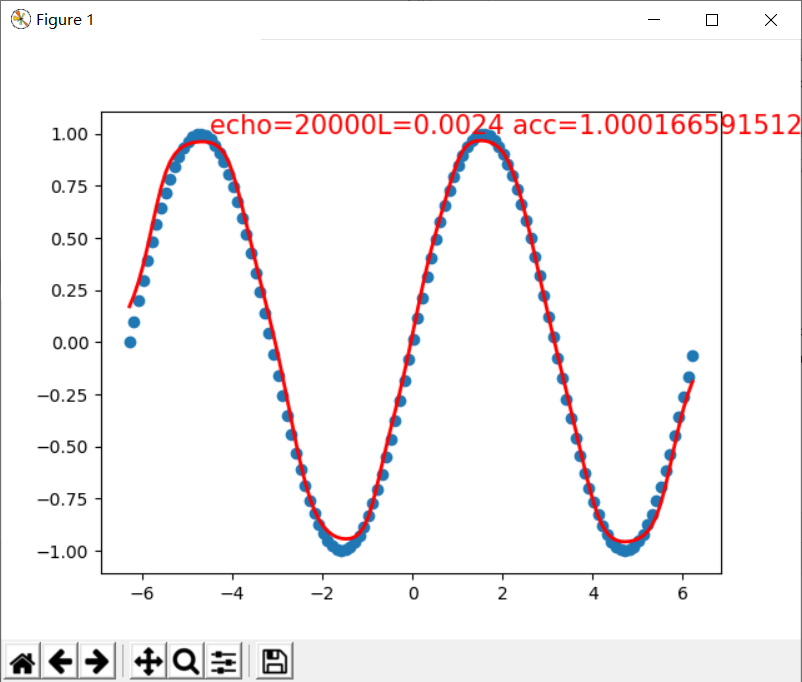
plt.text(-4.5, 1,
'echo=%sL=%.4f acc=%s' % (t+1,loss.data.numpy(),aucc),
fontdict={'size': 15, 'color': 'red'})
plt.pause(0.1)
print("训练结束")
plt.ioff()
plt.show()
python pytorch numpy DNN 线性回归模型的更多相关文章
- Python机器学习/LinearRegression(线性回归模型)(附源码)
LinearRegression(线性回归) 2019-02-20 20:25:47 1.线性回归简介 线性回归定义: 百科中解释 我个人的理解就是:线性回归算法就是一个使用线性函数作为模型框架($ ...
- 莫烦python教程学习笔记——线性回归模型的属性
#调用查看线性回归的几个属性 # Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg # ...
- 02_利用numpy解决线性回归问题
02_利用numpy解决线性回归问题 目录 一.引言 二.线性回归简单介绍 2.1 线性回归三要素 2.2 损失函数 2.3 梯度下降 三.解决线性回归问题的五个步骤 四.利用Numpy实战解决线性回 ...
- 线性回归模型(Linear Regression)及Python实现
线性回归模型(Linear Regression)及Python实现 http://www.cnblogs.com/sumai 1.模型 对于一份数据,它有两个变量,分别是Petal.Width和Se ...
- 吴裕雄 python 机器学习——线性回归模型
import numpy as np from sklearn import datasets,linear_model from sklearn.model_selection import tra ...
- 【scikit-learn】scikit-learn的线性回归模型
内容概要 怎样使用pandas读入数据 怎样使用seaborn进行数据的可视化 scikit-learn的线性回归模型和用法 线性回归模型的评估測度 特征选择的方法 作为有监督学习,分类问题是预 ...
- scikit-learn的线性回归模型
来自 http://blog.csdn.net/jasonding1354/article/details/46340729 内容概要 如何使用pandas读入数据 如何使用seaborn进行数据的可 ...
- 用C++调用tensorflow在python下训练好的模型(centos7)
本文主要参考博客https://blog.csdn.net/luoyexuge/article/details/80399265 [1] bazel安装参考:https://blog.csdn.net ...
- [tensorflow] 线性回归模型实现
在这一篇博客中大概讲一下用tensorflow如何实现一个简单的线性回归模型,其中就可能涉及到一些tensorflow的基本概念和操作,然后因为我只是入门了点tensorflow,所以我只能对部分代码 ...
随机推荐
- 【洛谷P4309】最长上升子序列
题目大意:给定一个序列,初始为空.现在我们将 1 到 N 的数字插入到序列中,每次将一个数字插入到一个特定的位置.每插入一个数字,我们都想知道此时最长上升子序列长度是多少? 题解:学会了 rope 操 ...
- hiho #1474 拆字游戏(dfs,记录状态)
#1474 : 拆字游戏 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Kui喜欢把别人的名字拆开来,比如“螺”就可以拆成“虫田糸”,小Kui的语文学的不是很好,于是 ...
- JSP中的四种作用域?
page.request.session和application,具体如下: ①page 代表与一个页面相关的对象和属性. ②request 代表与Web客户机发出的一个请求相关的对象和属性.一个请求 ...
- QT之QChar
QChar 类是 Qt 中用于表示一个字符的类,实现在 QtCore 共享库中.QChar 类内部用2个字节的Unicode编码来表示一个字符. Qchar构造函数: QChar ch=QChar() ...
- Atcoder Regular Contest 066 F genocide【JZOJ5451】
题目 分析 \(s[i]\)表示a前缀和. 设\(f[i]\)表示做完了1~i的友谊颗粒的最优值(不一定选i),那么转移方程为 \[f[i]=max\{f[i-1],max\{f[j]-s[i]+s[ ...
- Leetcode练习题21. Merge Two Sorted Lists
题目描述(easy) Merge Two Sorted Lists Merge two sorted linked lists and return it as a new list. The new ...
- spark 任务导致tmp目录过大
现象:hdp的集群没有配置spak的临时本地目录,默认在跑程序的时候会将中间过程的文件存放在本地的/tmp目录下 如果跑的spark数据量过大,就会导致/tmp下文件过大,最终导致根分区被占满,系统崩 ...
- k8s-强制删除pod
kubectl get deployments --all-namespaces [root@master ~]# kubectl get deployments --all-namespacesNA ...
- [人物存档]【AI少女】【捏脸数据】1224今日份的推荐
点击下载(城通网盘):AISChaF_20191111222714074.png 点击下载(城通网盘):AISChaF_20191108141610951.png
- eclipse切换工作空间