如何利用scrapy新建爬虫项目
抓取豆瓣top250电影数据,并将数据保存为csv、json和存储到monogo数据库中,目标站点:https://movie.douban.com/top250
一、新建项目
打开cmd命令窗口,输入:scrapy startproject douban【新建一个爬虫项目】
在命令行输入:cd douban/spiders【进入spiders目录】
在命令行输入:scrapy genspider douban_spider movie.douban.com【douban_spider为爬虫文件,编写xpath和正则表达式的地方,movie.douban.com为允许的域名】
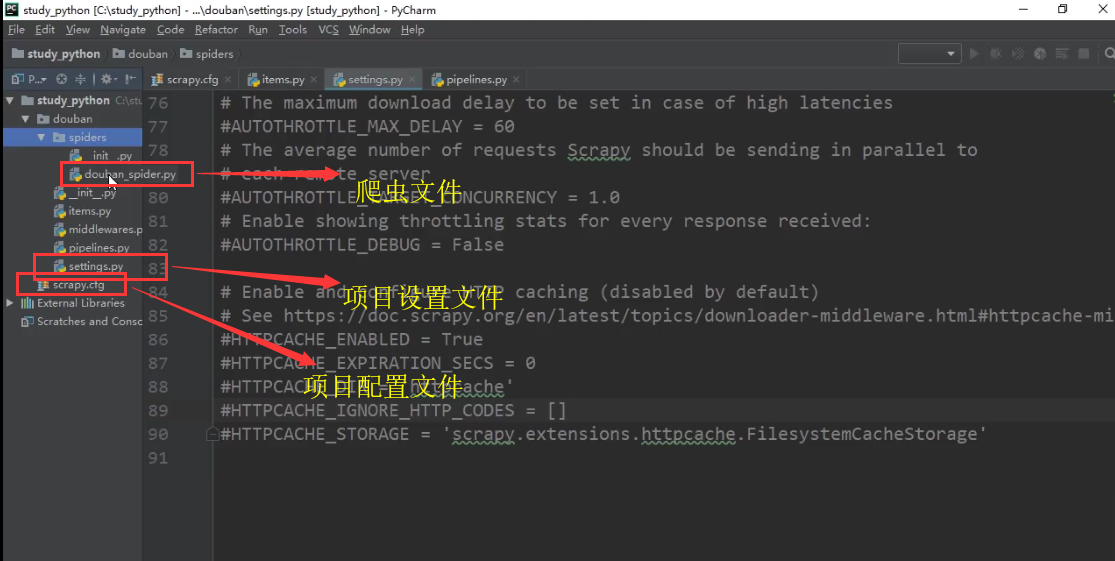
在pycharm打开创建的douban项目,目录结构如下:
二、明确目标
分析网站,确定要抓取的内容,编写items文件;
import scrapy class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#序号
serial_number = scrapy.Field()
#电影名称
movie_name = scrapy.Field()
#电影简介
introduce = scrapy.Field()
#星级
star = scrapy.Field()
#评价数
evaluate = scrapy.Field()
#描述
describe = scrapy.Field()
三、制作爬虫
编写douban_spider爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem class DoubanSpiderSpider(scrapy.Spider):
#爬虫名,不能跟项目名称重复
name = 'douban_spider'
#允许的域名,域名之内的网址才会访问
allowed_domains = ['movie.douban.com']
#入口url,扔到调度器里边
start_urls = ['https://movie.douban.com/top250']
#默认解析方法
def parse(self, response):
#循环电影的条目
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']//li")
for i_item in movie_list:
#item文件导进来
douban_item = DoubanItem()
#写详细的xpath,进行数据的解析
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//div[@class='hd']//a//span[1]/text()").extract_first()
content= i_item.xpath(".//div[@class='info']//div[@class='bd']//p[1]/text()").extract()
#多行结果需要进行数据的处理
#douban_item['introduce'] = ''.join(data.strip() for data in content)
for i_content in content:
content_s = "".join(i_content.split())
douban_item['introduce'] = content_s
douban_item['star'] = i_item.xpath(".//div[@class='star']//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describe'] = i_item.xpath(".//p[@class='quote']//span/text()").extract_first()
#将数据yield到piplines中
yield douban_item
#解析下一页规则,取的后一页的xpath
next_link = response.xpath("//span[@class='next']//a//@href").extract()
if next_link:
next_link=next_link[0]
#yield url到piplines中,回调函数callback
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
四、存储内容
将数据存储为JSON格式:scrapy crawl douban_spider -o test.json
将数据存储为CSV格式:scrapy crawl douban_spider -o test.csv【生成的CSV文件直接打开会是乱码,先利用Notepad++工具打开,编码格式改为utf-8保存再重新打开即可】
将数据保存到monogo数据库中:
# -*- coding: utf-8 -*-
import pymongo
mongo_db_collection
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html class DoubanPipeline(object):
#创建数据库连接
def __init__(self):
host = '127.0.0.1'
port = 27017
dbname = 'douban'
sheetname = 'douban_movie'
client = pymongo.MongoClient(host=host, port=port)
mydb = client[dbname]
self.post = mydb[sheetname]
#插入数据 def process_item(self, item, spider):
data = dict(item)
self.post.insert(data)
return item
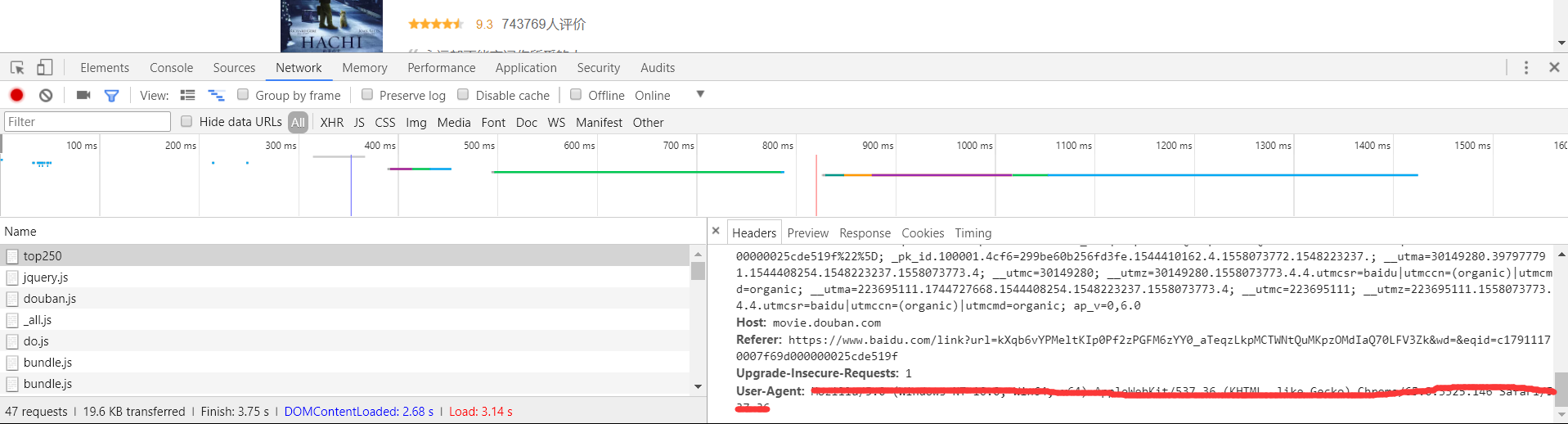
打开settings文件的USER_AGENT选项,删除里边内容,到网站找一个正确的USER_AGENT粘贴进来。【方法:打开豆瓣top50网站,按F12开发者选项,选择Network-All,刷新页面,选择top250,右侧Headers最下边即为USER_AGENT,如下图所示】
打开settings文件的ITEM_PIPELINES
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
设置启动文件
在douban文件下新建一个main.py文件,作为爬虫的启动文件,避免到命令窗口启动爬虫项目。
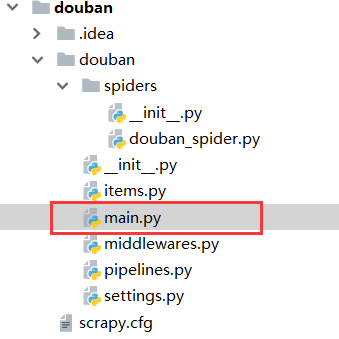
main文件内容如下:
from scrapy import cmdline
cmdline.execute('scrapy crawl douban_spider'.split())
如何利用scrapy新建爬虫项目的更多相关文章
- 使用scrapy 创建爬虫项目
使用scrapy 创建爬虫项目 步骤一: scrapy startproject tutorial 步骤二: you can start your first spider with: cd tuto ...
- (一)scrapy 安装及新建爬虫项目并运行
> 参考:https://www.cnblogs.com/hy123456/p/9847570.html 在 pycharm 中并没有创建 scrapy 工程的选项,需要手动创建. 这里就有两种 ...
- Scrapy创建爬虫项目
1.打开cmd命令行工具,输入scrapy startproject 项目名称 2.使用pycharm打开项目,查看项目目录 3.创建爬虫,打开CMD,cd命令进入到爬虫项目文件夹,输入scrapy ...
- PyCharm下使用Scrapy建立爬虫项目--MyFirstSpiderObject
首先下载并安装Anaconda3以及PyCharm Anaconda3选中添加环境变量,如果忘记选中可以手动在path中添加如下环境变量 建文件夹scrapy 安装scrapy cmd进入对应目录,执 ...
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- 利用scrapy和MongoDB来开发一个爬虫
今天我们利用scrapy框架来抓取Stack Overflow里面最新的问题(),并且将这些问题保存到MongoDb当中,直接提供给客户进行查询. 安装 在进行今天的任务之前我们需要安装二个框架,分别 ...
- 利用scrapy框架进行爬虫
今天一个网友问爬虫知识,自己把许多小细节都忘了,很惭愧,所以这里写一下大概的步骤,主要是自己巩固一下知识,顺便复习一下.(scrapy框架有一个好处,就是可以爬取https的内容) [爬取的是杨子晚报 ...
- 在Pycharm中运行Scrapy爬虫项目的基本操作
目标在Win7上建立一个Scrapy爬虫项目,以及对其进行基本操作.运行环境:电脑上已经安装了python(环境变量path已经设置好), 以及scrapy模块,IDE为Pycharm .操作如下: ...
- 关于Scrapy爬虫项目运行和调试的小技巧(下篇)
前几天给大家分享了关于Scrapy爬虫项目运行和调试的小技巧上篇,没来得及上车的小伙伴可以戳超链接看一下.今天小编继续沿着上篇的思路往下延伸,给大家分享更为实用的Scrapy项目调试技巧. 三.设置网 ...
随机推荐
- Oracle报Ora01522
应用服务报错截图 数据库后台日志报错截图 从日志分析应该是回滚异常造成表空间无法使用回滚段,而回滚涉及的表空间为undo表空间 尝试新建UNDO表空间,再将UNDO_TABLESPACE切换到新建的U ...
- Jmeter -- 上下文关联(JSON提取器)
目标: 将请求A响应数据的部分内容提取出来,保存成变量供后续请求使用(用在返回格式为json的HTTP请求中) 步骤: 1. 添加JSON Extractor后置处理器 add --> post ...
- i++ 是线程安全的吗
相信很多中高级的 Java 面试者都遇到过这个问题,很多对这个不是很清楚的肯定是一脸蒙逼.内心肯定还在质疑,i++ 居然还有线程安全问题?只能说自己了解的不够多,自己的水平有限. 先来看下面的示例来验 ...
- 一个强大的json解析工具类
该工具类利用递归原理,能够将任意结构的json字符串进行解析.当然,如果需要解析为对应的实体对象时,就不能用了 package com.wot.cloudsensing.carrotfarm.util ...
- [LeetCode]-010-Regular_Expression_Matching
Implement regular expression matching with support for '.' and '*'. '.' Matches any single character ...
- Route53 health check与 Cloudwatch alarm 没法绑定
原因 即使在控制台创建 创建的alarm会在us-east-1 不会再其他区域,目前route53 metric 在其他区域不存在. 所以使用cloudformation 创建 route53 hea ...
- shell命令别名
~/.bashrc文件 [root@linuxzgf ~]# vi ~/.bashrc 在alias cp='cp -i'前加上"#"注释,重新登录即可实现复 ...
- 总结 webpack 的插件
模块化第一步 初始化 package.json 文件 node.js 指令 npm init npm的官网:https://www.npmjs.com/ 搜索插件名,查看插件的用法 1. webpa ...
- mysql高水位问题解决办法
数据库中有些表使用delete删除了一些行后,发现空间并未释放产生原因:类比Oracle的高水位线产生原理 delete 不会释放文件高水位 truncate会释放 ,实际是把.ibd文件删掉了,再建 ...
- windows程序调试
由于不能在控制台输出,可以使用Messagebox 但是有时候要用到输出int之类的,需要转换.转换过程中有会有很多问题. 这里给出两个可行的代码 int a = 5, b = 10; int res ...