Python爬取数据并保存到csv文件中
1、数据源
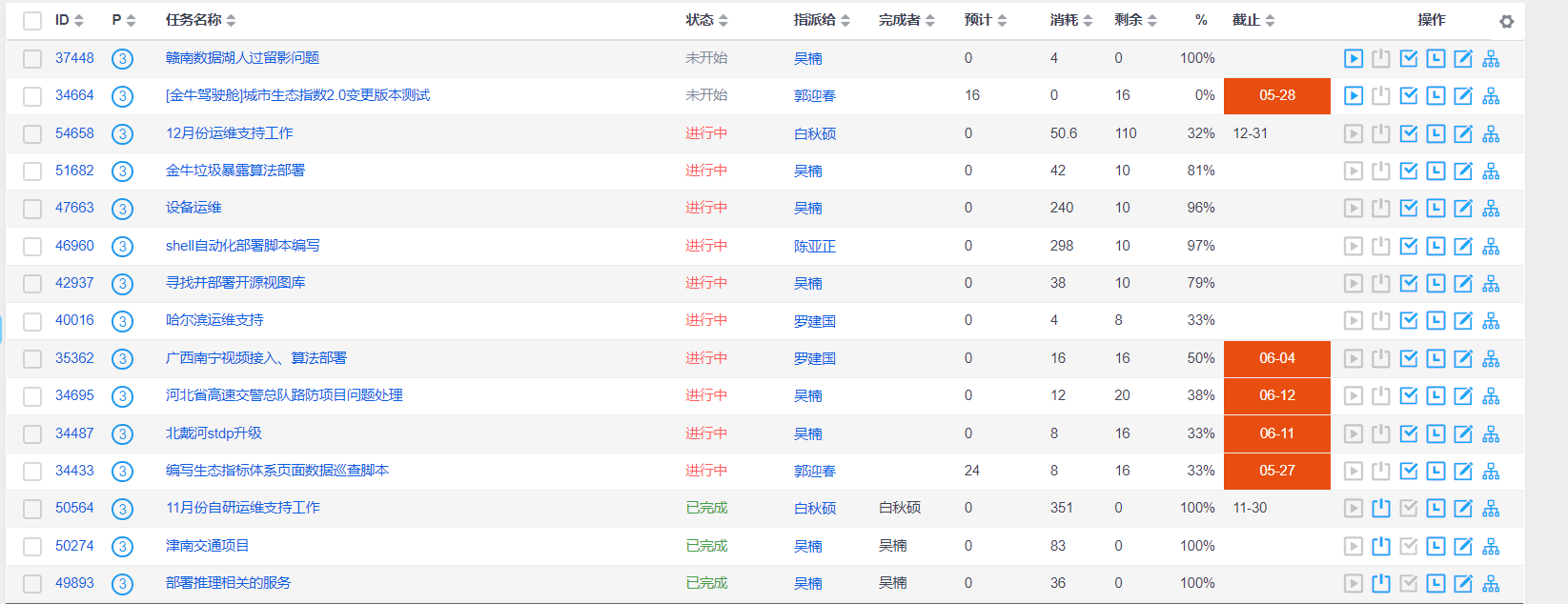
2、Python代码
import requests
from lxml import etree
import csv url = 'http://211.103.175.222:5080/zentaopms/www/index.php?m=project&f=task&projectID=830'
headers = {
'Cookie': 'lang=zh-cn; device=desktop; theme=default; feedbackView=0; lastProject=830; preProjectID=830; lastTaskModule=0; projectTaskOrder=status%2Cid_desc; pagerProjectTask=2000; keepLogin=on; za=zhangyh01; zp=2a7befd1193619083ca09e00e186dc709a5722c2; windowWidth=1707; windowHeight=679; zentaosid=revjktmd869d6q7ilfhrjp1bpn'
} res = requests.get(url,headers=headers)
res.encoding = 'utf-8' tree = etree.HTML(res.text)
trs = tree.xpath('//*[@id="taskList"]/tbody/tr')
f = open('result.csv',mode='w',newline='') # newline='':防止保存的csv文件有空行
csv_writer = csv.writer(f) for tr in trs:
id = tr.xpath('./td[1]/a/text()')[0]
jb = tr.xpath('./td[2]/span/text()')[0]
title = tr.xpath('./td[3]/a/text()')[0]
name = tr.xpath('./td[5]/a/span/text()')[0]
wcl = tr.xpath('./td[10]/text()')[0]
csv_writer.writerow([id,jb,title,name,wcl])
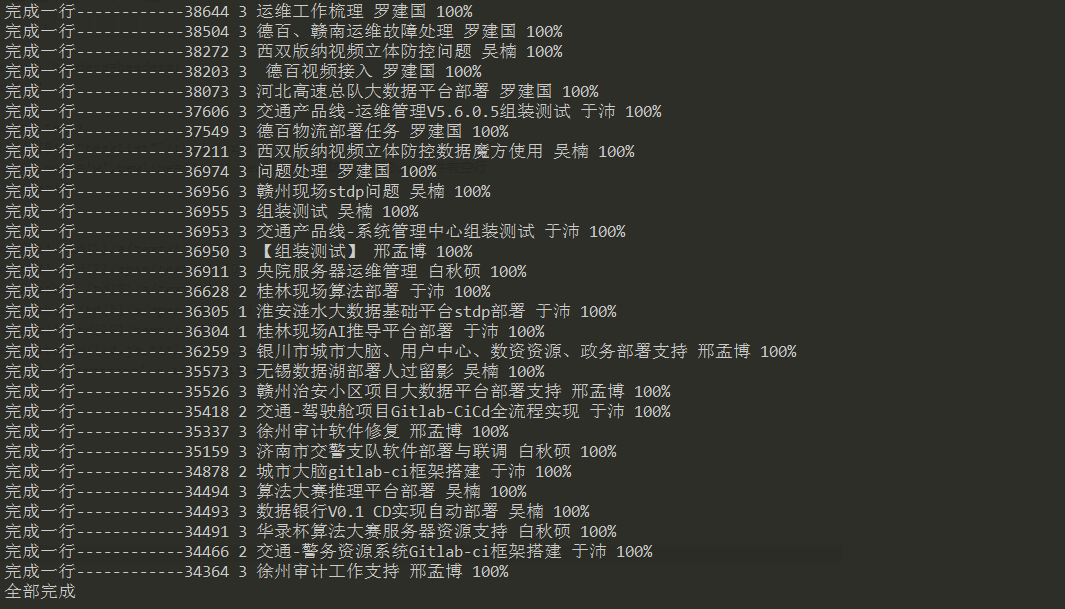
print('完成一行------------' + id,jb,title,name,wcl) f.close()
print('全部完成')
3、执行过程
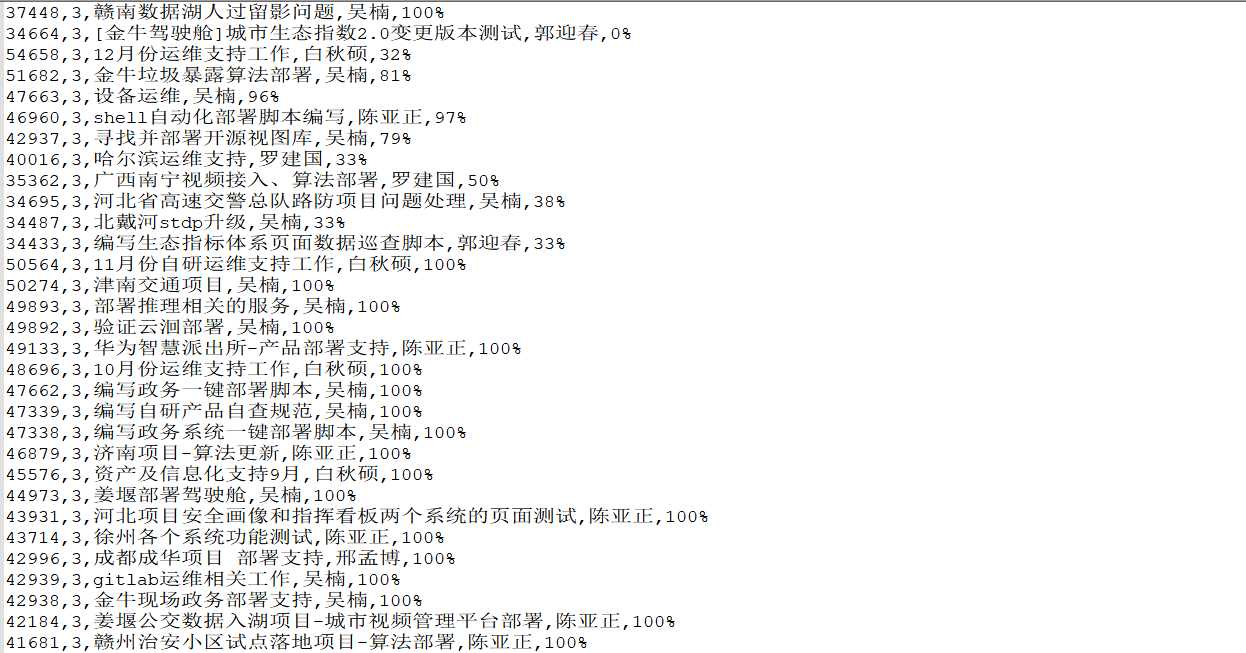
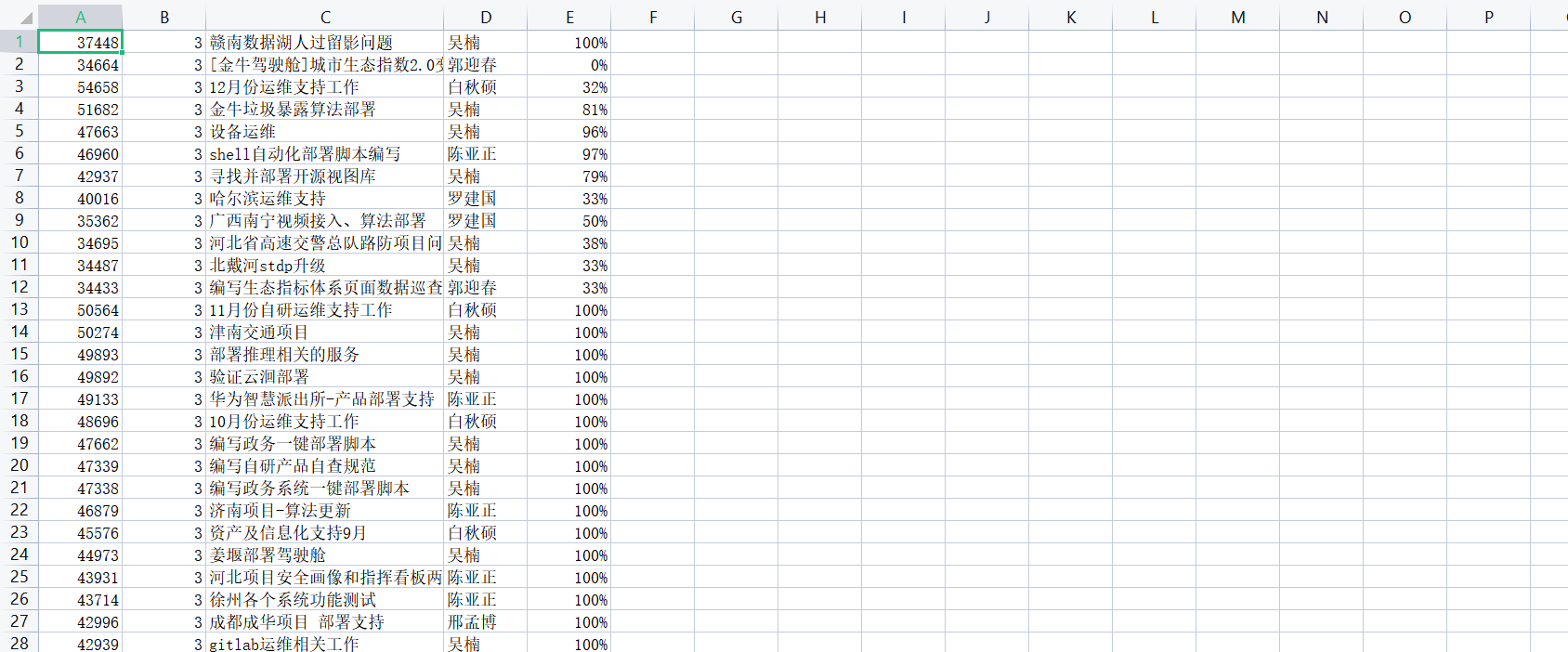
4、保存的结果
Python爬取数据并保存到csv文件中的更多相关文章
- 使用scrapy爬取的数据保存到CSV文件中,不使用命令
pipelines.py文件中 import codecs import csv # 保存到CSV文件中 class CsvPipeline(object): def __init__(self): ...
- 使用pandas中的raad_html函数爬取TOP500超级计算机表格数据并保存到csv文件和mysql数据库中
参考链接:https://www.makcyun.top/web_scraping_withpython2.html #!/usr/bin/env python # -*- coding: utf-8 ...
- 实现多线程爬取数据并保存到mongodb
多线程爬取二手房网页并将数据保存到mongodb的代码: import pymongo import threading import time from lxml import etree impo ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- node 爬虫 --- 将爬取到的数据,保存到 mysql 数据库中
步骤一:安装必要模块 (1)cheerio模块 ,一个类似jQuery的选择器模块,分析HTML利器. (2)request模块,让http请求变的更加简单 (3)mysql模块,node连接mysq ...
- Python爬取爬取明星关系并写入csv文件
今天用Python爬取了明星关系,数据不多,一共1386条数据,代码如下: import requests from bs4 import BeautifulSoup import bs4 impor ...
- 直接把数据库中的数据保存在CSV文件中
今天突然去聊就来写一个小小的demo喽,嘿嘿 public partial class Form1 : Form { public Form1() { InitializeComponent(); } ...
- python爬取数据保存到Excel中
# -*- conding:utf-8 -*- # 1.两页的内容 # 2.抓取每页title和URL # 3.根据title创建文件,发送URL请求,提取数据 import requests fro ...
- python爬取数据需要注意的问题
1 爬取https的网站或是接口的时候,如果是不受信用的SSL证书,会报错,需要添加如下代码,如下代码可以保证当前代码块内所有的请求都自动屏蔽ssl证书问题: import ssl # 这个是爬取ht ...
- python爬取数据保存入库
import urllib2 import re import MySQLdb class LatestTest: #初始化 def __init__(self): self.url="ht ...
随机推荐
- html-testRunner中文乱码
如下图,使用 html-testRunner 这个库生成测试报告后,出现乱码 因为 HTML文件已经写了 文件编码是 utf-8 所以 我怀疑可能是 html-testRunner 这个库文件中 ...
- MogDB/openGauss关于PL/SQL匿名块调用测试
MogDB/openGauss 关于 PL/SQL 匿名块调用测试 一.原理介绍 PL/SQL(Procedure Language/Structure Query Language)是标准 SQL ...
- HarmonyOS SDK 助力新浪新闻打造精致易用的新闻应用
原生智能是HarmonyOS NEXT的核心亮点之一,依托HarmonyOS SDK丰富全面的开放能力,开发者只需通过几行代码,即可快速实现AI功能.新浪新闻作为鸿蒙原生应用开发的先行者之一,从有声资 ...
- 活动开启 | 以梦筑码 · 不负韶华 开发者故事征集令,讲出你的故事,有机会参加HDC.Together 2023
HarmonyOS面世以来,经历了3大版本迭代,系统能力逐步完善,生态加速繁荣.一路前行,是开发者们点亮漫天星光.点滴贡献,聚沙成塔,开发者们正用代码改变世界. 是梦想,激励我们一路前行.在黎明到 ...
- modbus通信案例简单介绍
介绍: 1.仪表等其他智能设备的modbus通信协议,确定其内部功能码地址.以型号U-MIK-P350-SCN2的杭州美控公司的压力变送器为例.查看对应手册20页.2.PLC端的编程配置.以西门子s7 ...
- js扩展方法(自用)
//字符串转Date 字符串格式 yyyy-MM-dd HH:mm:ssString.prototype.toDate = function() { var date = eval('new Date ...
- 【Serverless实战】B站每日自动签到&&传统单节点网站的Serverless上云
简介: Serverless好哇!这里将针对个人与生产两个应用方向的测评 使用Serverless实现自动获取每日B站的经验值,让你更快冲到LV6! 你的业务站点还是一台服务器All in One吗? ...
- 阿里云2020上云采购季,你的ECS买好了吗?
阿里云2020上云采购季,超级品类日,天天有爆款. 今日爆款推荐:云服务器. 重磅推荐两款,限时抢购. 新品共享型s6: 企业级共享型n4: 想看更多云产品,来阿里云采购季: https://www. ...
- 最佳实践丨构建云上私有池(虚拟IDC)的5种方案详解
简介:云上私有池系列终篇终于来了,本文将重点介绍构建云上的私有池(虚拟IDC)的多种方案和各自的优缺点,并给出相关的性价比优化建议. 本文作者:阿里云技术专家李雨前 摘要 围绕私有池(虚拟IDC)的 ...
- Vineyard 加入 CNCF Sandbox,将继续瞄准云原生大数据分析领域
简介: Vineyard 是一个专为云原生环境下大数据分析场景中端到端工作流提供内存数据共享的分布式引擎,我们很高兴宣布 Vineyard 在 2021 年 4 月 27 日被云原生基金会(CNCF) ...