(二)requests-爬取国家药监局生产许可证数据
首先访问这个页面 url = 'http://125.35.6.84:81/xk/'
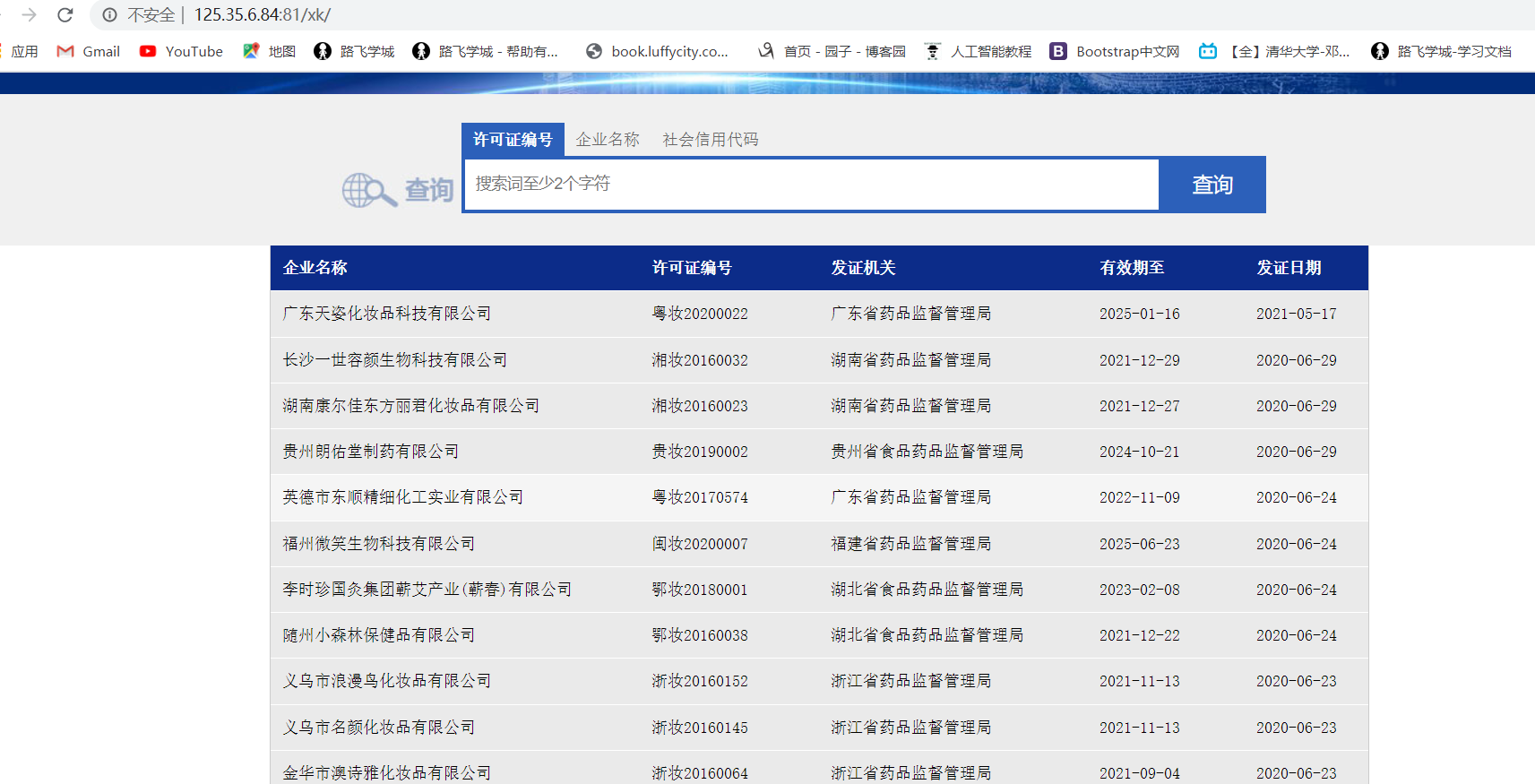
我们的目标是抓取这里的每一个企业的详情页数据,但是可以发现这里只有企业的简介信息,所以这就意味着我们要发送两次get请求。
在写代码之前,我们可以大概看一下我们想要的数据大概在什么位置。
1. 我们打开一个公司的详情页

2. 右击检查,通过Response查找对应的目标数据
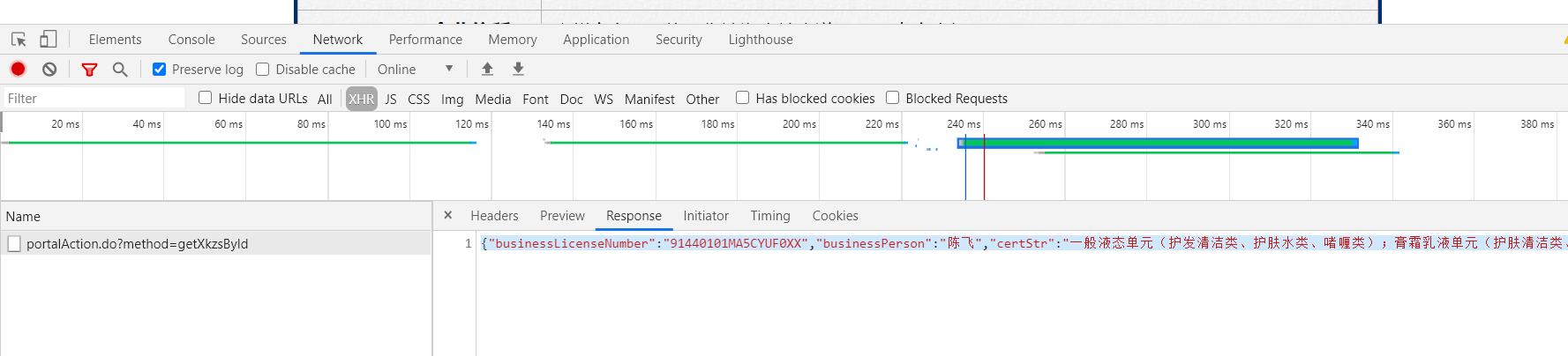
从这里我们可以看出,当前的数据是通过ajax请求动态加载出来的
3.查看头信息,以及参数信息

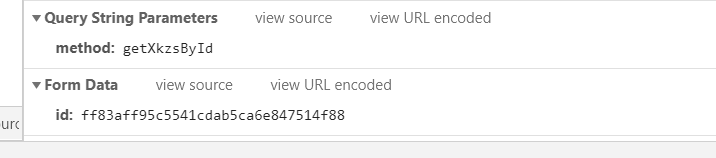
我们可以看出,当前的请求是post请求,所需要的参数是id,但是从以上的数据来看我们并没有发现哪里有id这个参数。因为我们将目光聚焦到首页。
4. 分析首页所返回的数据
同样是右击检查,打开抓包工具
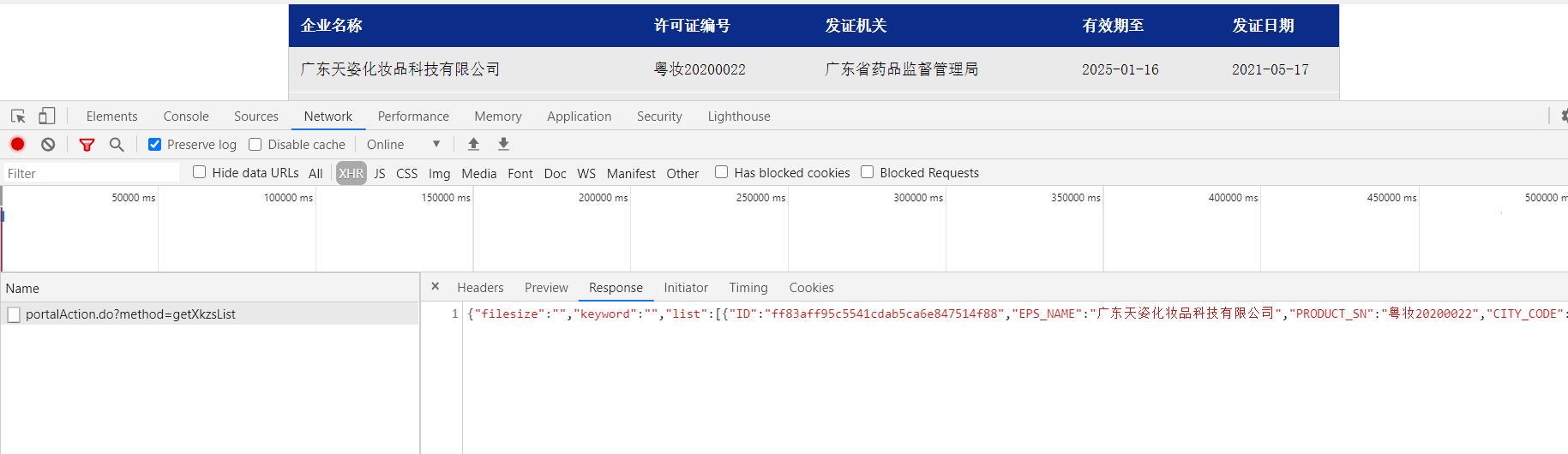
从这里我们可以看出首页的数据也是通过ajax动态加载出来的,并且通过观察我们可以发现在ID的踪迹,至此我们就可以形成一条完整的思路。
5.我们可以看看首页的请求方式,与是否携带了参数
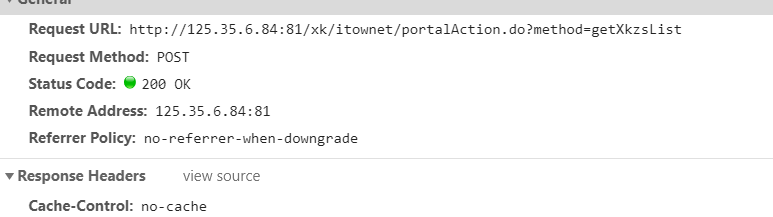
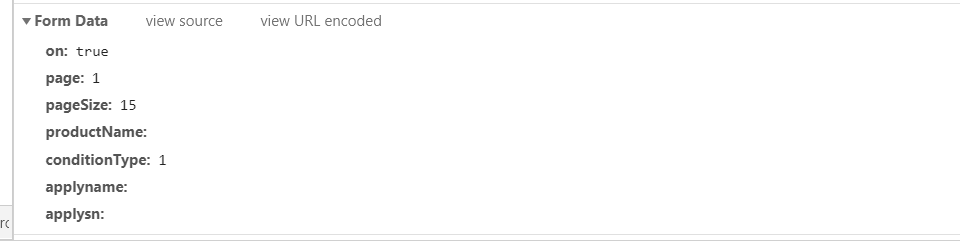
6. 思路:拿到首页的响应数据的ID,并以此为参数向详情页发送post请求,拿到每个详情页的详情数据。
7.代码实现:
import requests
import json if __name__ == '__main__':
# 获取各个企业id
id_list = []
# 这里的url并非是首页的url 首页中的所有企业信息都是通过ajax动态请求的 因此应查看对应包中的url
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36'
}
# 获取前五页的数据
for page in range(1, 5):
page = str(page)
# 首页请求所需参数
data = {
'on': 'true',
'page': page,
'pageSize': '15',
'productName': '',
'conditionType': '1',
'applyname': '',
'applysn': ''
} # 向首页发送请求
response = requests.post(url=url, data=data, headers=header)
# 拿到json格式的数据
info = response.json()
# 拿到所有企业信息的列表
target_id = info['list']
for i in target_id:
# 获取所有企业的id
id_list.append(i['ID']) # 获取企业详情信息
ret_list = []
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById' # 获取所有企业的详情数据
for i in id_list:
data = {
'id': i
}
ret = requests.post(url=url, data=data, headers=header)
ret_list.append(ret.json()) # 持久化存储
fileName = 'files/药监总局.json'
with open(fileName, 'w', encoding='utf-8') as f:
f.write(json.dumps(ret_list, ensure_ascii=False))
print('work is done')
(二)requests-爬取国家药监局生产许可证数据的更多相关文章
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- selenium爬取qq空间,requests爬取雪球网数据
一.爬取qq空间好友动态数据 # 爬取qq空间好友状态信息(说说,好友名称),并屏蔽广告 from selenium import webdriver from time import sleep f ...
- 爬虫(二)Python网络爬虫相关基础概念、爬取get请求的页面数据
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆 ...
- requests爬取百度音乐
使用requests爬取百度音乐,我想把当前热门歌手的音乐信息爬下来. 首先进行url分析,可以看到: 歌手网页: 薛之谦网页: 可以看到,似乎这些路劲的获取一切都很顺利,然后可以写代码: # -*- ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 爬虫学习(二)--爬取360应用市场app信息
欢迎加入python学习交流群 667279387 爬虫学习 爬虫学习(一)-爬取电影天堂下载链接 爬虫学习(二)–爬取360应用市场app信息 代码环境:windows10, python 3.5 ...
- Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的 使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据 爬虫工具 使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文 ...
- Requests爬取网页的编码问题
Requests爬取网页的编码问题 import requests from requests import exceptions def getHtml(): try: r=requests.get ...
- Python爬虫系列之爬取美团美食板块商家数据(二)
今天为大家重写一个美团美食板块小爬虫,说不定哪天做旅游攻略的时候也可以用下呢.废话不多说,让我们愉快地开始吧~ 开发工具 Python版本:3.6.4 相关模块: requests模块: argpar ...
随机推荐
- 力扣476(java)-数字的补数(简单)
题目: 对整数的二进制表示取反(0 变 1 ,1 变 0)后,再转换为十进制表示,可以得到这个整数的补数. 例如,整数 5 的二进制表示是 "101" ,取反后得到 "0 ...
- 阿里云全站加速DCDN重磅发布!打造新一代加速引擎
简介: 新一代的加速引擎DCDN,安全.高效.可计算 在数字化转型变革逐步深入的当下,安全高效成为企业上云.全球化部署的关键需求. 随着应用场景复杂度不断提升.业务需求差异化发展,为了给企业提供更完善 ...
- Cube 技术解读 | 详解「支付宝」全新的卡片技术栈
简介: 魔方卡片(Cube),让 App 首页实现敏捷更新. CodeHub#7 正式落幕,来自蚂蚁集团的技术专家「京君」与掘金社区的开发者们分享了「支付宝」全新的卡片技术栈--魔方卡片(Cub ...
- [Py] Failed to import pydot. You must install pydot and graphviz for `pydotprint` to work
当通过常规命令安装 pip install pydot 和 brew install graphviz 之后,在代码中 import pydot 依旧不生效. 比如:在 tensorflow 使用 t ...
- dotnet 解析 TTF 字体文件格式
在 Windows 下,可以使用 DX 提供的强大能力,调用 DX 读取 TTF 字体文件,获取字体文件的信息以及额外的渲染信息.特别是基于 DX 的 WPF 更是加了一层封装,使用 FontFami ...
- C# 采集知网
采集知网 WebClient /// <summary> /// 支持 Session 和 Cookie 的 WebClient. /// </summary> public ...
- Stable Diffusion中的embedding
Stable Diffusion中的embedding 嵌入,也称为文本反转,是在 Stable Diffusion 中控制图像样式的另一种方法.在这篇文章中,我们将学习什么是嵌入,在哪里可以找到它们 ...
- 程序员天天 CURD,怎么才能成长,职业发展的思考 ?
前言 关于程序员成长的话题,我前面写过一篇文章 - 程序员天天CURD,职业生涯怎么发展的思考. 现在回头看,对程序员这个职业发展的认识以及怎么发展还是有一些局限性.有一句话是这么说的:人的成长就是不 ...
- C# 实现Ping远程主机功能
C#实现Ping远程主机功能. 1.引用nuget包 Wesky.Net.OpenTools OpenTools是一个用于提高开发效率的开源工具库.该项目为个人开源项目,采用MIT开源协议,永不更改协 ...
- 关于URP14绘制全屏Blit后处理的改动
最近用回URP,发现RendererFeature这部分改动很大,启用了之前HDRP的RTHandle,RTHandle的设计类似于优化版本的RenderTexture, 可以统一控制缩放或者并非一对 ...