结巴分词中TFIDF的原理
之前了解TFIDF只是基于公式,今天被阿里面试官问住了,所以深入讨论下TFIDF在结巴分词中原理。
概念
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
原理
在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(分子一般小于分母 区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语 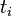 来说,它的重要性可表示为:
来说,它的重要性可表示为:

以上式子中 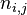 是该词 在文件
是该词 在文件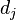 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:

其中
- |D|:语料库中的文件总数
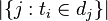 :包含词语的文件数目(即
:包含词语的文件数目(即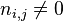 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用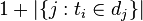
然后
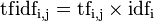
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
结巴中的应用:关键词提取
先上例子:
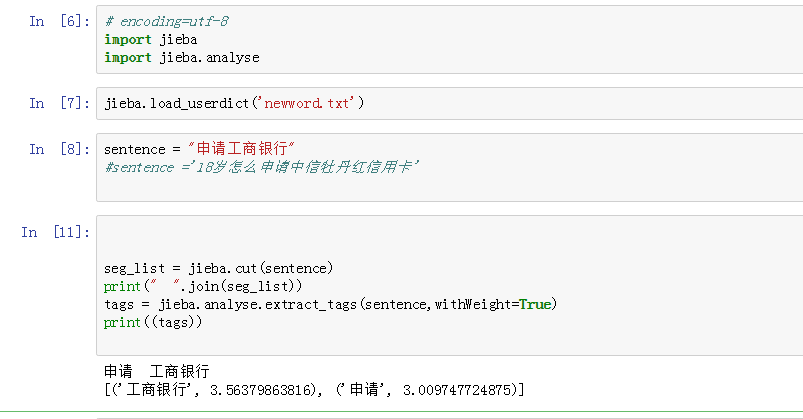
很好奇 这个3.56是怎么算出来的,因为只有一个句子,idf应该是1(总文章数(1)除以 出现"工商银行"的文章数(1))
其实并不是这样的,结巴中自带了定义好的idf文件,如图。
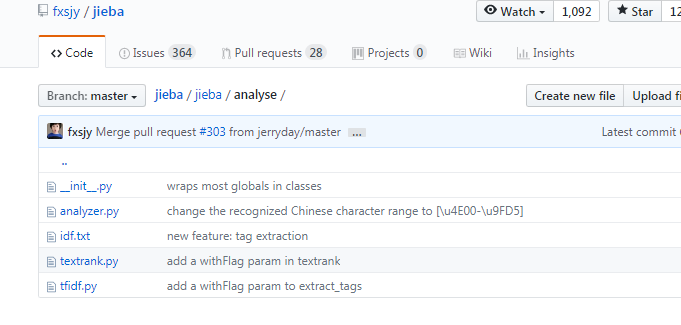
其中 工商银行的idf是7.12
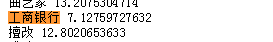
所以 3.56 是 tf=0.5(申请工商银行。里有2个词,工商银行出现1次) idf = 7.12(内置的idf)
tfidf = tf*idf=3.56
下面 把句子换成 工商银行申请工商银行
tf = 2/3 idf = 7.12
tfidf = 2/3*7.12 = 4.75

如果结巴自定义的词典,词语不在idf中,会怎样呢?
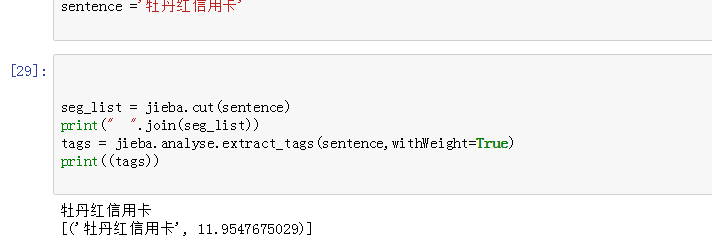
11.95 是咋来的呢?
分析一下idf那个文件:
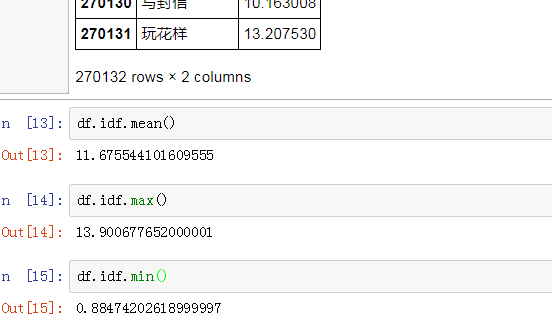
11.95可以看做是idf的平均值!!!!
结巴分词中TFIDF的原理的更多相关文章
- Python3.7+jieba(结巴分词)配合Wordcloud2.js来构造网站标签云(关键词集合)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_138 其实很早以前就想搞一套完备的标签云架构了,迫于没有时间(其实就是懒),一直就没有弄出来完整的代码,说到底标签对于网站来说还是 ...
- Python中结巴分词使用手记
手记实用系列文章: 1 结巴分词和自然语言处理HanLP处理手记 2 Python中文语料批量预处理手记 3 自然语言处理手记 4 Python中调用自然语言处理工具HanLP手记 5 Python中 ...
- python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库 -转载
转载请注明出处 “结巴”中文分词:做最好的 Python 中文分词组件,分词模块jieba,它是python比较好用的分词模块, 支持中文简体,繁体分词,还支持自定义词库. jieba的分词,提取关 ...
- 结巴分词3--基于汉字成词能力的HMM模型识别未登录词
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 1 算法简介 在 结巴分词2--基于前缀词典及动态规划实现分词 博 ...
- python中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
- Python 结巴分词模块
原文链接:http://www.gowhich.com/blog/147?utm_source=tuicool&utm_medium=referral PS:结巴分词支持Python3 源码下 ...
- python 结巴分词学习
结巴分词(自然语言处理之中文分词器) jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于 ...
- python 中文分词:结巴分词
中文分词是中文文本处理的一个基础性工作,结巴分词利用进行中文分词.其基本实现原理有三点: 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) 采用了动态规 ...
- python结巴分词SEO的应用详解
结巴分词在SEO中可以应用于分析/提取文章关键词.关键词归类.标题重写.文章伪原创等等方面,用处非常多. 具体结巴分词项目:https://github.com/fxsjy/jieba ...
随机推荐
- android studio如何生成签名文件,以及SHA1和MD5值
一.生成签名文件 1.点击菜单栏中的Build的. 2.弹出窗体,如下图,选中Generate Signed APK,并点击. 3.弹出窗体,如下图. 4.点击Create new…按钮,创建一个签名 ...
- cocos2d-x游戏引擎核心之二——内存管理
(一) cocos2d-x 内存管理 cocos2d里面管理内存采用了引用计数的方式,具体来说就是CCObject里面有个成员变量m_uReference(计数); 1, m_uReference的变 ...
- iOS - xib中关于拖拽手势的潜在错误
iOS开发拓展篇—xib中关于拖拽手势的潜在错误 一.错误说明 自定义一个用来封装工具条的类 搭建xib,并添加一个拖拽的手势. 主控制器的代码:加载工具条 封装工具条以及手势拖拽的监听事件 此时运行 ...
- c++11实现optional
optional< T> c++14中将包含一个std::optional类,optional< T>内部存储空间可能存储了T类型的值也可能没有存储T类型的值.当optiona ...
- MQTT-SN协议乱翻之功能描述
前言 紧接上文,这是第三篇,主要是对MQTT-SN 1.2协议进行总体性功能描述. 嗯,这一部分可以结合着MQTT协议对比着来看. 网关的广播和发现 网关只能在成功连接到MQTT Server之后,才 ...
- MQTT-SN协议乱翻之简要介绍
前言 这一段时间在翻看MQTT-SN的协议,对针对不依赖于TCP传输的MQTT协议十分感兴趣,总是再想着这货到底是怎么定义的.一系列文章皆有MQTT-SN 1.2协议所拼装组成,原文档地址: MQTT ...
- 解决Chrome关联Html文件图标显示为空白
用记事本保存为ChromeHTML.reg Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\CLSID\{42042206-2D85-1 ...
- HTML的特殊字符-图标对应表
本文摘自:http://www.cnblogs.com/web-d/archive/2010/04/16/1713298.html HTML特殊字符编码大全:往网页中输入特殊字符,需在html代码 ...
- 使用log4net记录日志到数据库(含有自定义属性)
记录日志是管理系统中对用户行为的一种监控与审核,asp.net中记录日志的方式有很多种,这里我只介绍一下最近用到的log4net,关于他的具体介绍网上有很多,我讲一下他的用法. 第一步:在配置文件中的 ...
- Feature Tools 简介
FeatureTools是2017年9月上线的github项目,是一个自动生成特征的工具,应用于关系型数据. github链接:https://github.com/Featuretools/feat ...