Elasticsearch拼音分词和IK分词的安装及使用
一、Es插件配置及下载
1.IK分词器的下载安装
关于IK分词器的介绍不再多少,一言以蔽之,IK分词是目前使用非常广泛分词效果比较好的中文分词器。做ES开发的,中文分词十有八九使用的都是IK分词器。
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
2.pinyin分词器的下载安装
可以在淘宝、京东的搜索框中输入pinyin就能查找到自己想要的结果,这就是拼音分词,拼音分词则是将中文分析成拼音格式,可以通过拼音分词分析出来的数据进行查找想要的结果。
下载地址:https://github.com/medcl/elasticsearch-analysis-pinyin
注:插件下载一定要和自己版本对应的Es版本一致,并且安装完插件后需重启Es,才能生效。
插件安装位置:(本人安装了三个插件,暂时先不介绍murmur3插件,可以暂时忽略)

插件配置成功,重启Es
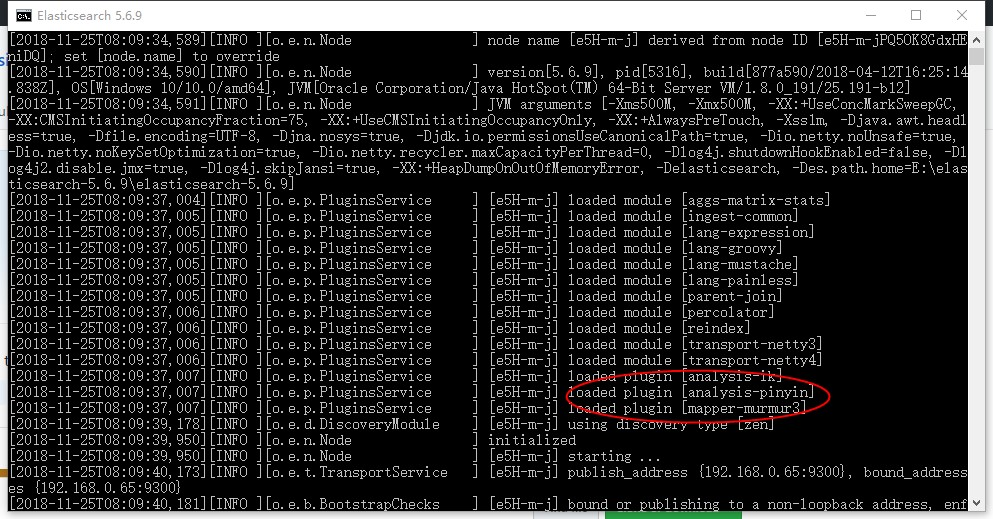
二、拼音分词器和IK分词器的使用
1.IK中文分词器的使用
1.1 ik_smart: 会做最粗粒度的拆分
GET /_analyze
{
"text":"中华人民共和国国徽",
"analyzer":"ik_smart"
} 结果:
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "国徽",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 1
}
]
}
1.2 ik_max_word: 会将文本做最细粒度的拆分
GET /_analyze
{
"text": "中华人民共和国国徽",
"analyzer": "ik_max_word"
} 结果:
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "中华人民",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "中华",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
},
{
"token": "华人",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 3
},
{
"token": "人民共和国",
"start_offset": 2,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
},
{
"token": "人民",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 5
},
{
"token": "共和国",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 6
},
{
"token": "共和",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 7
},
{
"token": "国",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 8
},
{
"token": "国徽",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 9
}
]
}
2.拼音分词器的使用
GET /_analyze
{
"text":"刘德华",
"analyzer": "pinyin"
} 结果:
{
"tokens": [
{
"token": "liu",
"start_offset": 0,
"end_offset": 1,
"type": "word",
"position": 0
},
{
"token": "ldh",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "de",
"start_offset": 1,
"end_offset": 2,
"type": "word",
"position": 1
},
{
"token": "hua",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 2
}
]
}
注:不管是拼音分词器还是IK分词器,当深入搜索一条数据是时,必须是通过分词器分析的数据,才能被搜索到,否则搜索不到
三、IK分词和拼音分词的组合使用
当我们创建索引时可以自定义分词器,通过指定映射去匹配自定义分词器
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"ik_smart_pinyin": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": ["my_pinyin", "word_delimiter"]
},
"ik_max_word_pinyin": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["my_pinyin", "word_delimiter"]
}
},
"filter": {
"my_pinyin": {
"type" : "pinyin",
"keep_separate_first_letter" : true,
"keep_full_pinyin" : true,
"keep_original" : true,
"limit_first_letter_length" : 16,
"lowercase" : true,
"remove_duplicated_term" : true
}
}
}
} }
当我们建type时,需要在字段的analyzer属性填写自己的映射
PUT /my_index/my_type/_mapping
{
"my_type":{
"properties": {
"id":{
"type": "integer"
},
"name":{
"type": "text",
"analyzer": "ik_smart_pinyin"
}
}
}
}
测试,让我们先添加几条数据
POST /my_index/my_type/_bulk
{ "index": { "_id":1}}
{ "name": "张三"}
{ "index": { "_id": 2}}
{ "name": "张四"}
{ "index": { "_id": 3}}
{ "name": "李四"}
IK分词查询
GET /my_index/my_type/_search
{
"query": {
"match": {
"name": "李"
}
}
} 结果:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.47160998,
"hits": [
{
"_index": "my_index",
"_type": "my_type",
"_id": "3",
"_score": 0.47160998,
"_source": {
"name": "李四"
}
}
]
}
}
拼音分词查询:
GET /my_index/my_type/_search
{
"query": {
"match": {
"name": "zhang"
}
}
} 结果:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.3758317,
"hits": [
{
"_index": "my_index",
"_type": "my_type",
"_id": "2",
"_score": 0.3758317,
"_source": {
"name": "张四"
}
},
{
"_index": "my_index",
"_type": "my_type",
"_id": "1",
"_score": 0.3758317,
"_source": {
"name": "张三"
}
}
]
}
}
注:搜索时,先查看被搜索的词被分析成什么样的数据,如果你搜索该词输入没有被分析出的参数时,是查不到的!!!!
Elasticsearch拼音分词和IK分词的安装及使用的更多相关文章
- 使用Docker 安装Elasticsearch、Elasticsearch-head、IK分词器 和使用
原文:使用Docker 安装Elasticsearch.Elasticsearch-head.IK分词器 和使用 Elasticsearch的安装 一.elasticsearch的安装 1.镜像拉取 ...
- ElasticSearch已经配置好ik分词和mmseg分词(转)
ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进行数据索引 ...
- Elasticsearch集群使用ik分词器
IK分词插件的安装 ES集群环境 VMWare下三台虚拟机Ubuntu 14.04.2 LTS JDK 1.8.0_66 Elasticsearch 2.3.1 elasticsearch-jdbc- ...
- ElasticSearch中文分词器-IK分词器的使用
IK分词器的使用 首先我们通过Postman发送GET请求查询分词效果 GET http://localhost:9200/_analyze { "text":"农业银行 ...
- ElasticSearch(六):IK分词器的安装与使用IK分词器创建索引
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了. 1. i ...
- Windows10安装Elasticsearch IK分词插件
安装插件 cmd切换到Elasticsearch安装目录下 C:\Users\Administrator>D: D:\>cd D:\Program Files\Elastic\Elasti ...
- Docker 下Elasticsearch 的安装 和ik分词器
(1)docker镜像下载 docker pull elasticsearch:5.6.8 (2)安装es容器 docker run -di --name=changgou_elasticsearch ...
- Elasticsearch拼音和ik分词器的结合应用
一.创建索引时,自定义拼音分词和ik分词 PUT /my_index { "index": { "analysis": { "analyzer&quo ...
- ElasticSearch 中文分词插件ik 的使用
下载 IK 的版本要与 Elasticsearch 的版本一致,因此下载 7.1.0 版本. 安装 1.中文分词插件下载地址:https://github.com/medcl/elasticsearc ...
随机推荐
- leetcode — count-and-say
import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * Source : https://o ...
- VC连接MySql
VC连接MySql 一丶MySql 需要了解的知识 VC连接MySql 需要了解几个关键的API: MYSQL * stdcall mysql init (MYSQL *mysql): 初始化一个数 ...
- solr查询特殊字符的处理
1. 使用solr的页面功能时,遇到语法错误 2. 确认原因 从lexical error分析时特殊字符的问题. 首先 solr查询有哪些特殊字符? 查找官方文档:http://lucene.apac ...
- 翻译:update语句(已提交到MariaDB官方手册)
本文为mariadb官方手册:UPDATE的译文. 原文:https://mariadb.com/kb/en/update/ 我提交到MariaDB官方手册的译文:https://mariadb.co ...
- Python 的名称空间和作用域
最开始对名称空间的了解是在学习函数的时候,那时候知道了作用域的查找顺序,以及全局名称空间和局部名称空间,产生疑惑的时候为学递归的时候,那时候还没有名称空间这个概念,只知道递归有个最大深度,那时候以后递 ...
- python模块之sys与os
python常用模块系列(二):sys模块与os模块 sys模块是python解释器和环境有关的一个模块: os是python用来和操作系统进行交互的一个模块. 一 sys 查看当前环境变量 查看已经 ...
- Laravel日志
大家在使用 Log::info() 会让日志全部记录默认在 storage/logs/laravel.log 文件里,文件大了查找起来就比较麻烦.那么我可不可以单独记录在一个日志文件里呢? 只需在你的 ...
- 【Linux命令】grep命令
1.作用 Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来.grep全称是Global Regular Expression Print,表示全 ...
- C#设计模式之二十职责链模式(Chain of Responsibility Pattern)【行为型】
一.引言 今天我们开始讲“行为型”设计模式的第八个模式,该模式是[职责链模式],英文名称是:Chain of Responsibility Pattern.让我们看看现实生活中的例子吧,理解起来可能更 ...
- CSS3 - 盒子的 box - size
两个参数: border-box和content-box <!DOCTYPE html> <html lang="en"> <head> < ...