吴裕雄--天生自然 pythonTensorFlow自然语言处理:交叉熵损失函数
import tensorflow as tf # 1. sparse_softmax_cross_entropy_with_logits样例。
# 假设词汇表的大小为3, 语料包含两个单词"2 0"
word_labels = tf.constant([2, 0]) # 假设模型对两个单词预测时,产生的logit分别是[2.0, -1.0, 3.0]和[1.0, 0.0, -0.5]
predict_logits = tf.constant([[2.0, -1.0, 3.0], [1.0, 0.0, -0.5]]) # 使用sparse_softmax_cross_entropy_with_logits计算交叉熵。
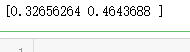
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=word_labels, logits=predict_logits) # 运行程序,计算loss的结果是[0.32656264, 0.46436879], 这对应两个预测的
# perplexity损失。
sess = tf.Session()
print(sess.run(loss))
# 2. softmax_cross_entropy_with_logits样例。
# softmax_cross_entropy_with_logits与上面的函数相似,但是需要将预测目标以
# 概率分布的形式给出。
word_prob_distribution = tf.constant([[0.0, 0.0, 1.0], [1.0, 0.0, 0.0]])
loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_distribution, logits=predict_logits)
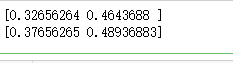
# 运行结果与上面相同:[ 0.32656264, 0.46436879]
print(sess.run(loss)) # label smoothing:将正确数据的概率设为一个比1.0略小的值,将错误数据的概率
# 设为比0.0略大的值,这样可以避免模型与数据过拟合,在某些时候可以提高训练效果。
word_prob_smooth = tf.constant([[0.01, 0.01, 0.98], [0.98, 0.01, 0.01]])
loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_smooth, logits=predict_logits)
# 运行结果:[ 0.37656265, 0.48936883]
print(sess.run(loss)) sess.close()
吴裕雄--天生自然 pythonTensorFlow自然语言处理:交叉熵损失函数的更多相关文章
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:PTB 语言模型
import numpy as np import tensorflow as tf # 1.设置参数. TRAIN_DATA = "F:\TensorFlowGoogle\\201806- ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Attention模型--测试
import sys import codecs import tensorflow as tf # 1.参数设置. # 读取checkpoint的路径.9000表示是训练程序在第9000步保存的ch ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Attention模型--训练
import tensorflow as tf # 1.参数设置. # 假设输入数据已经转换成了单词编号的格式. SRC_TRAIN_DATA = "F:\\TensorFlowGoogle ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Seq2Seq模型--测试
import sys import codecs import tensorflow as tf # 1.参数设置. # 读取checkpoint的路径.9000表示是训练程序在第9000步保存的ch ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:Seq2Seq模型--训练
import tensorflow as tf # 1.参数设置. # 假设输入数据已经用9.2.1小节中的方法转换成了单词编号的格式. SRC_TRAIN_DATA = "F:\\Tens ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:文本数据预处理--生成训练文件
import sys import codecs # 1. 参数设置 MODE = "PTB_TRAIN" # 将MODE设置为"PTB_TRAIN", &qu ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:数据集高层操作
import tempfile import tensorflow as tf # 1. 列举输入文件. # 输入数据生成的训练和测试数据. train_files = tf.train.match_ ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:输入数据处理框架
import tensorflow as tf # 1. 创建文件列表,通过文件列表创建输入文件队列 files = tf.train.match_filenames_once("F:\\o ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:循环神经网络预测正弦函数
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt # 定义RNN的参数. HIDDEN_SIZE = ...
随机推荐
- Jenkins-在Centos上配置自动化部署(Jenkins+Gitlab+Rancher)
Jenkins-在Centos上配置自动化部署(Jenkins+Gitlab+Rancher) 环境:centos7 首先在服务器上安装好Jenkins和Gitlab和Rancher Gitlab安装 ...
- 2.在约会网站上使用k近邻算法
在约会网站上使用k近邻算法 思路步骤: 1. 收集数据:提供文本文件.2. 准备数据:使用Python解析文本文件.3. 分析数据:使用Matplotlib画二维扩散图.4. 训练算法:此步骤不适用于 ...
- 吴裕雄--天生自然C++语言学习笔记:C++ 修饰符类型
C++ 允许在 char.int 和 double 数据类型前放置修饰符.修饰符用于改变基本类型的含义,所以它更能满足各种情境的需求. 下面列出了数据类型修饰符: signed unsigned lo ...
- Codeforces 1291B - Array Sharpening
题目大意: 一个数列是尖锐的 当且仅当存在一个位置k使得 a[1]<a[2]<a[3]<...<a[k] 且 a[k]>a[k+1]>a[k+2]>...&g ...
- chown virtualbox
virtualbox安装 root@cbill-VirtualBox:/# chown --help用法:chown [选项]... [所有者][:[组]] 文件... 或:chown [选项]... ...
- LVS DR模式搭建、keepalived+LVS搭建介绍
参考文献 http://blog.51cto.com/taoxie/2066993 疑问: 1.为什么要修改RealServer的返回arp响应和发送arp请求参数 echo "1&quo ...
- SpringCloud学习之手把手教你用IDEA搭建入门项目【番外篇】(一)
之前的文章里,我曾经搭建了一个Springcloud项目,但是那个时候我对于SpringCloud架构的很多组件不甚清楚,只是通过查找资料然后动手稀里糊涂的把一个项目成功搭建起来了,其中有很多不合理和 ...
- class选择器,外部样式表,选择器优先级
class选择器: 先在相应标签中设置一个class属性,如class=“class名”.class名{ ……css样式}注:class名以英文字母开头,可以多个标签重复使用.优先级:标签名选择器 & ...
- C语言中getopt()和getopt_long()函数的用法
一.参考文章 1.C语言中getopt()和getopt_long()函数的用法 2.linux 中解析命令行参数 (getopt_long用法) 二.调试经验
- hook鼠标
library dllMouse; uses SysUtils, Classes, UnitHookDLL in 'UnitHookDLL.pas', UnitHookConst in 'UnitHo ...