Gatling脚本编写技巧篇(二)
脚本示例:
import io.gatling.core.Predef._
import io.gatling.http.Predef._
import scala.concurrent.duration._
class BaiduSimulation extends Simulation {
//读取配置文件
val conf = ConfigFactory.load()
//实例化请求方法
val httpProtocol = http.baseUrl(conf.getString("baseUrl"))
//包装请求接口
val rootEndPointUsers = scenario("信贷重构")
.exec(http("信贷重构-授信申请")
.post("/apply")
.header("Content-Type", "application/json")
.header("Accept-Encoding", "gzip")
.body(RawFileBody("computerdatabase/recordedsimulation/0001_request.json"))
.check(status.is(200)
.saveAs("myresponse") )
.check(bodyString.saveAs("Get_bodys")))
.exec{
session => println("这就是传说的值传递"+session("Get_bodys").as[String] )
session
}
}
配置文件(application.properties):
#新信贷通用接口
baseUrl = http://172.16.3.179:7800
脚本编写:
Gatling脚本的编写主要包含三个步骤:
1. http head配置
2. Scenario 执行细节
3. setUp 组装
编写实例:
//配置文件地址src/galting/resource/application.properties //使用的时候 初始化配置文件的读
val conf = ConfigFactory.load()
报头定义:
//设置请求的根路径
val httpConf = http.baseURL(conf.getString("baseUrl"))
这里需要知道的是报头也可以在seniario中定义(有下列两种方式去设置Json和xml要求的报头)
//http(...).get(...).asJSON等同于:
http(...).get(...)
.header(HttpHeaderNames.ContentType,HttpHeaderValues.ApplicationJson)
.header(HttpHeaderNames.accept,HttpHeaderValues.ApplicationJson) //http(...).get(...).asXML等同于
http(...).get(...)
.header(HttpHeaderNames.ContentType,HttpHeaderValues.ApplicationXml)
.header(HttpHeaderNames.accept,HttpHeaderValues.ApplicationXml)
场景定义:
val rootEndPointUsers = scenario("信贷重构").exec(http("信贷重构-授信申请").post("/apply"))
场景的定义要有名称,原因是同一个模拟器中可以 定义多个场景,场景通常被存储在Scala的变量中
场景的基本机构有两种
exec :用来描述行动,通常是发送到待测应用的一个请求
pause: 用来模拟连续请求的用户思考时间
模拟器的定义:
//设置线程数
setUp(rootEndPointUsers.inject(atOnceUsers(10)).protocols(httpConf))
模拟器的参数:
setUp( rootEndPointUsers.inject(
nothingFor(4 seconds), // 1
atOnceUsers(10), // 2
rampUsers(10) over(5 seconds), // 3
constantUsersPerSec(20) during(15 seconds), // 4
constantUsersPerSec(20) during(15 seconds) randomized, // 5
rampUsersPerSec(10) to 20 during(10 minutes), // 6
rampUsersPerSec(10) to 20 during(10 minutes) randomized, // 7
splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy(10 seconds), // 8
splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy atOnceUsers(30), // 9
heavisideUsers(1000) over(20 seconds) // 10
).protocols(httpConf)
)
| 函数 | 解释 |
| nothingFor(4 seconds) | 等待一个指定的时间 |
| atOnceUsers(10) | 一次性注入指定数量的用户 |
| ampUsers(10) over(5 seconds) | 在指定的时间内,以线性增长的方式注入指定数量的用户 |
| constantUsersPerSec(20) during(15 seconds) | 在指定的时间内,以固定频率注入用户,以每秒的多少用户的方式。固定时间间隔 |
| constantUsersPerSec(20) during(15 seconds) randomized | 在指定时间段内,用固定的频率注入用户,以每秒多少个用户的方式定义。用户以随机间隔注 |
| ampUsersPerSec(10) to 20 during(10 minutes) | 在指定时间段内,从起始频率到目标频率注入用户,以每秒多少个用户的方式定义。用户以固定间隔注入 |
| rampUsersPerSec(10) to 20 during(10 minutes) randomized | 在指定时间段内,从起始频率到目标频率注入用户,以每秒多少个用户的方式定义。用户以随机间隔注入 |
| splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy(10 seconds) | 在指定时间内,重复执行定义好的 注入步骤,间隔指定时间,直到达到最大用户数nbUsers |
| splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy atOnceUsers(30) | 在指定时间内,重复执行定义好的 第一个注入步骤,间隔定义好的 第二个注入步骤,直到达到最大用户数nbUsers |
设置场景属性的时候 需要注意以下两点:
开放的负载:
封闭系统,您可以控制并发的使用数量
封闭系统是并发用户数量有上限的系统。在满负荷运行时,新用户只能在另一个用户退出时才能有效地进入系统
封闭的负载:
开放系统,您可以控制用户的到达率
相反,开放系统无法控制并发用户的数量:即使应用程序无法为用户提供服务,用户也会不断地到达。大多数网站都是这样的
重点注意:
如果您希望根据每秒请求数而不是并发用户数进行推理,那么可以考虑使用constantUsersPerSec()来设置用户的到达率,从而设置请求数,而不需要进行节流,因为在大多数情况下这是多余的
技巧篇:
对于测试中的数据构造 往往是我们比较痛苦的地方 虽然Gatling中提供了参数生成 但是并不能满足我们的测试需求 ,凭借之前对其他工具的理解 同时Gatling
也是运行在java虚拟机中这两点 我尝试了将自己的java工具类放到Gatling中调用 从而进行参数的构造。
下面开始介绍我的做法:
1、在Gatling 工程中的resource 目录下创建一个lib 目录
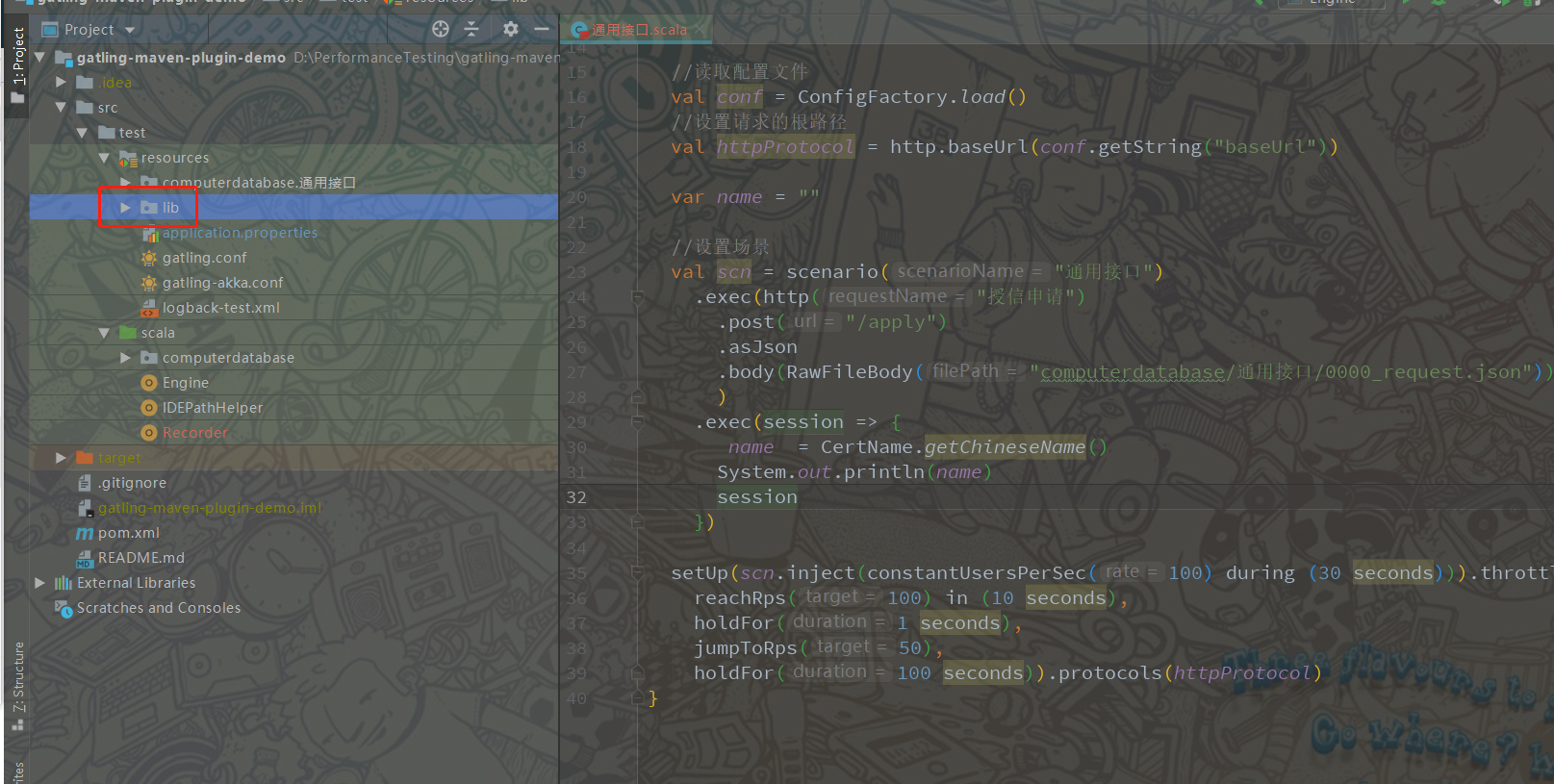
2、将自己生成的工具类jar包放到lib目录下
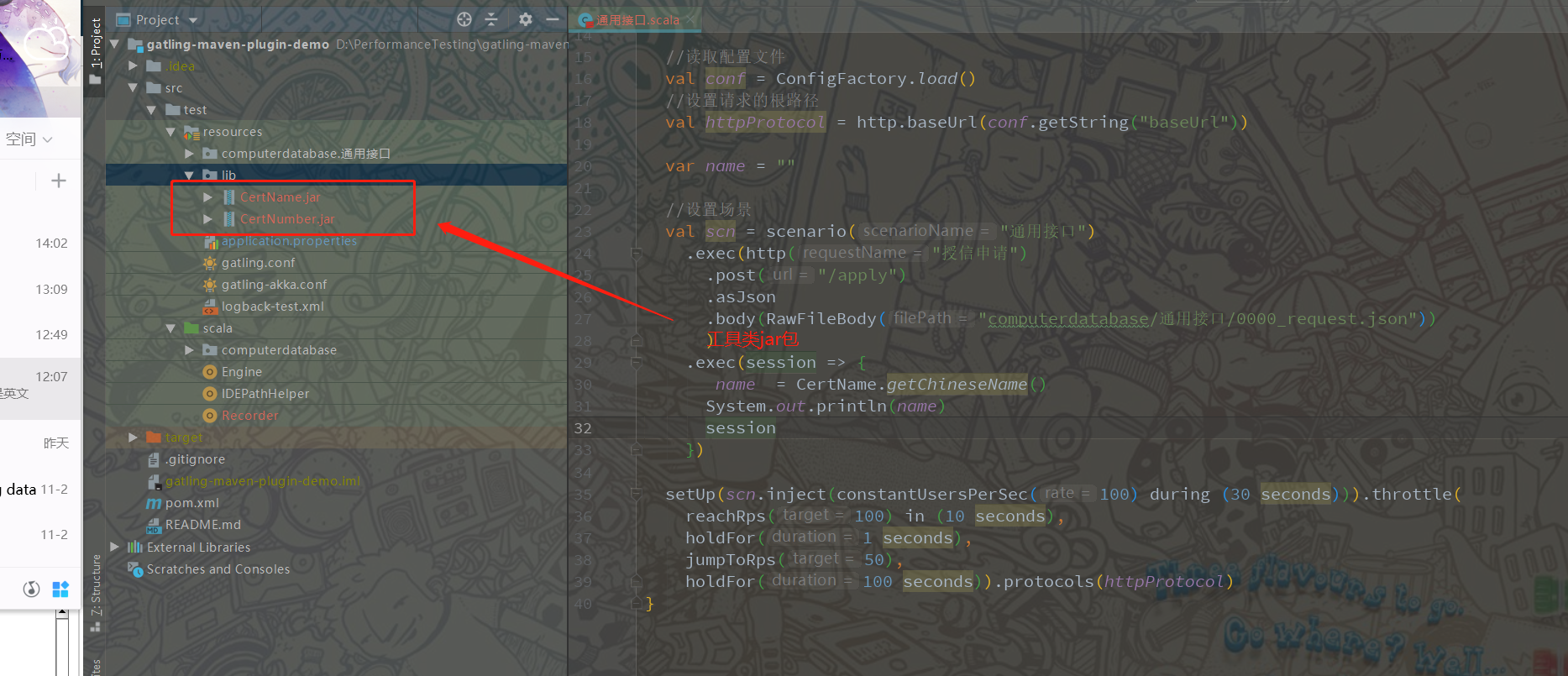
3、将jar包载入System Library库中
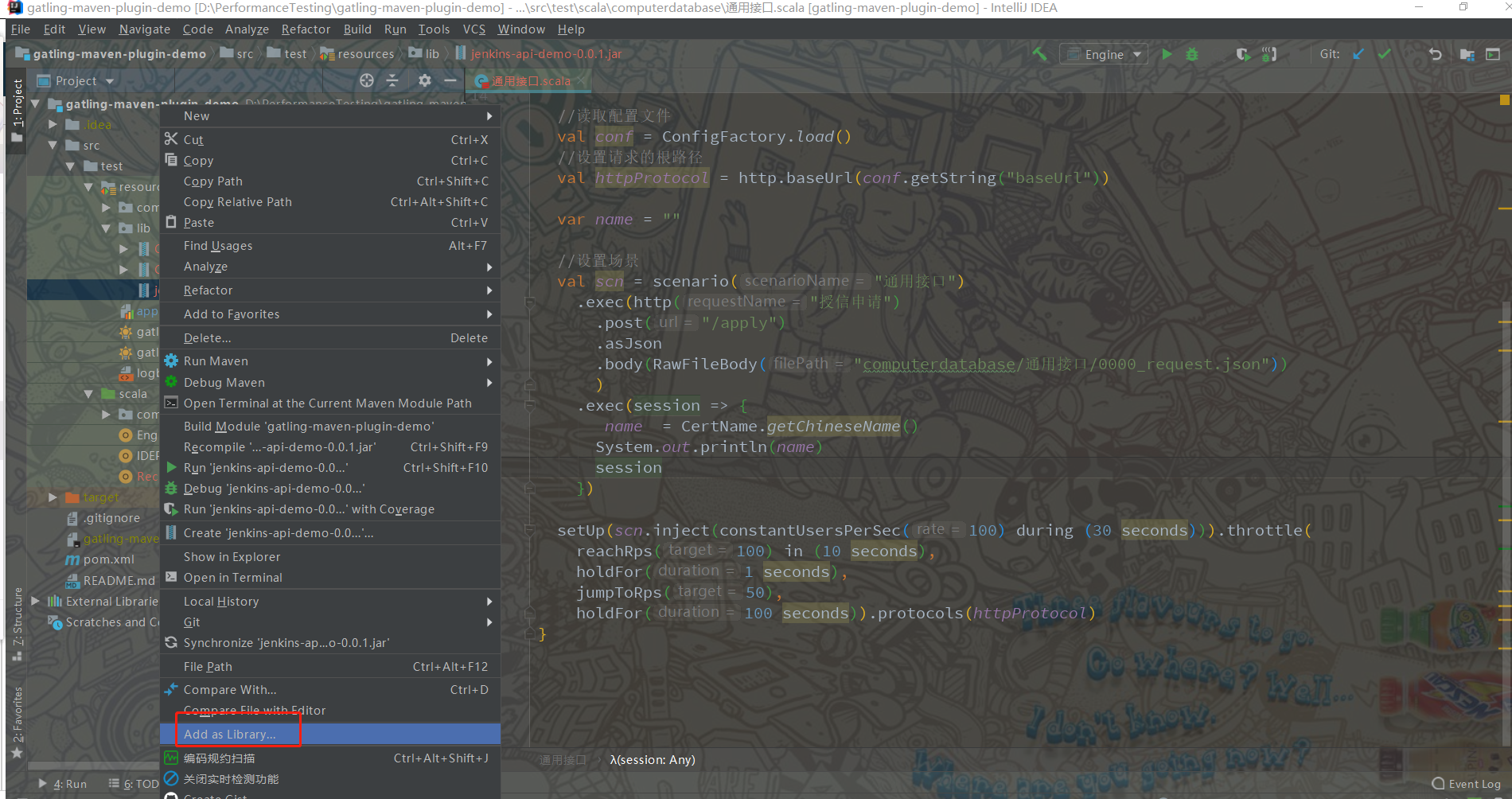
4、引入工具类
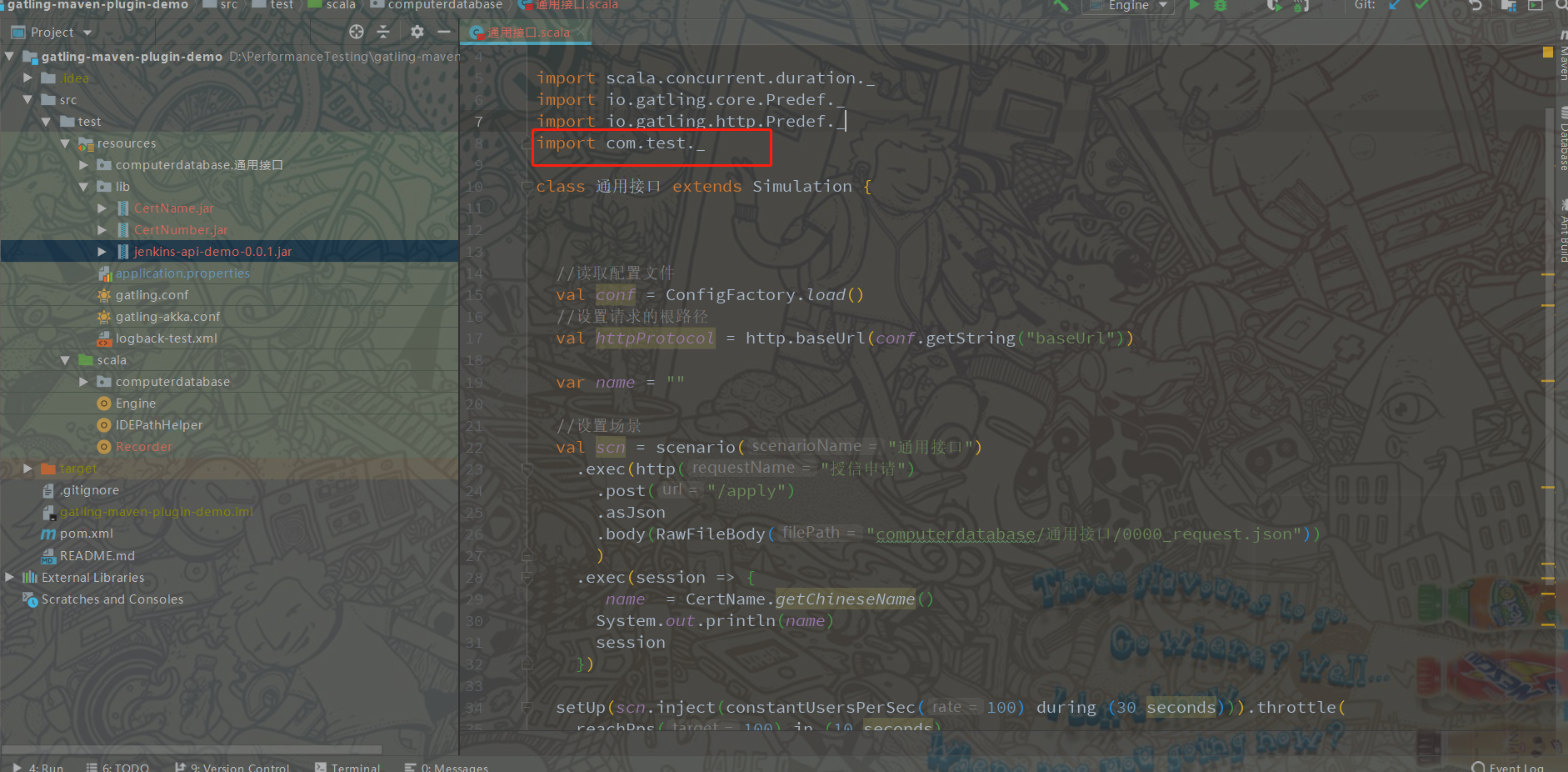
5、测试工具类 方法调用
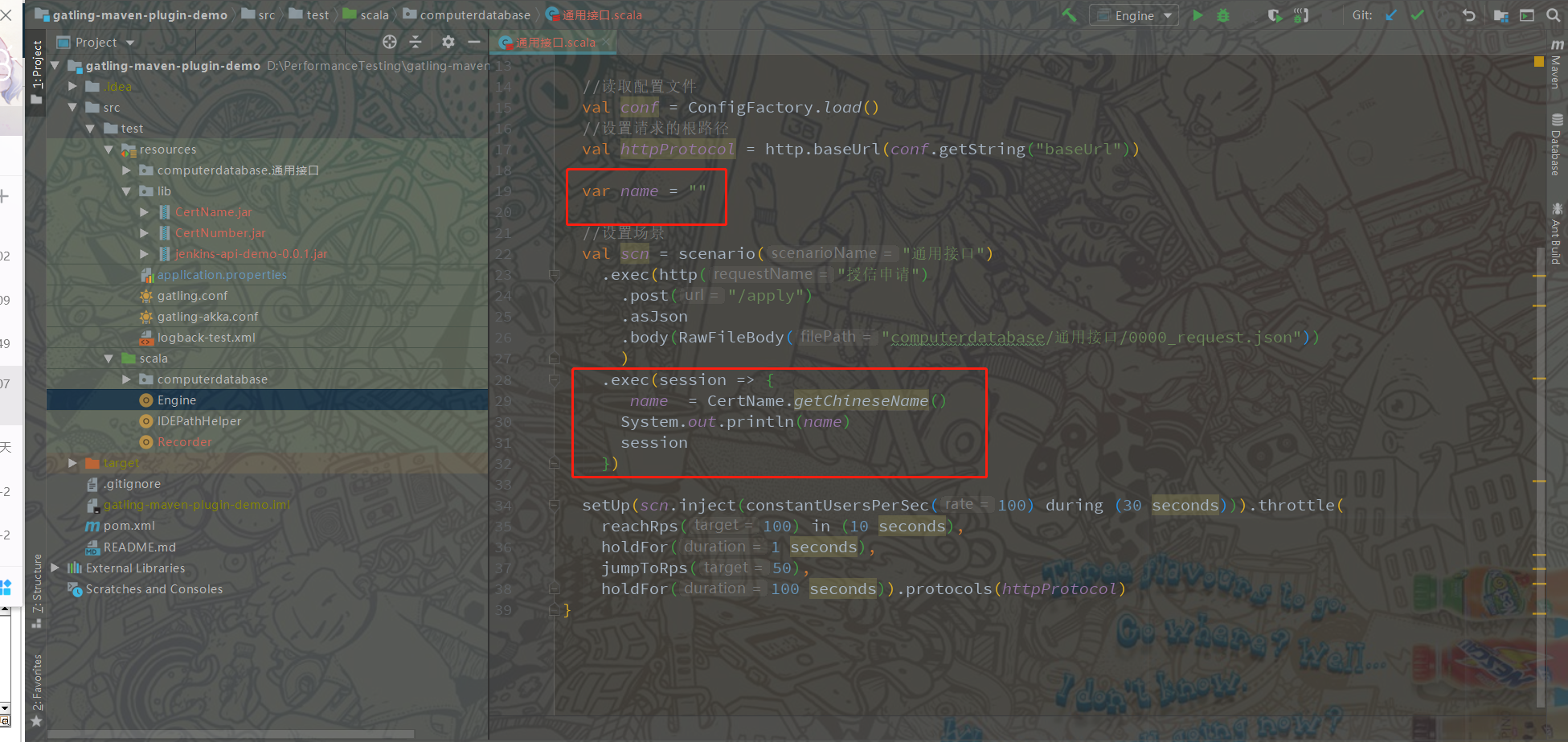
这里要注意的是Feeder这个函数,在加载参数的时候或者通过我这种方法,函数调用的外部jar包 都只会生效一次。因此要想灵活运用外部jar包工具类还需要在工程中再次加工,例如:我会调用jar包工具类一次性生成3000个数据,
然后在调用封装的方法即可。
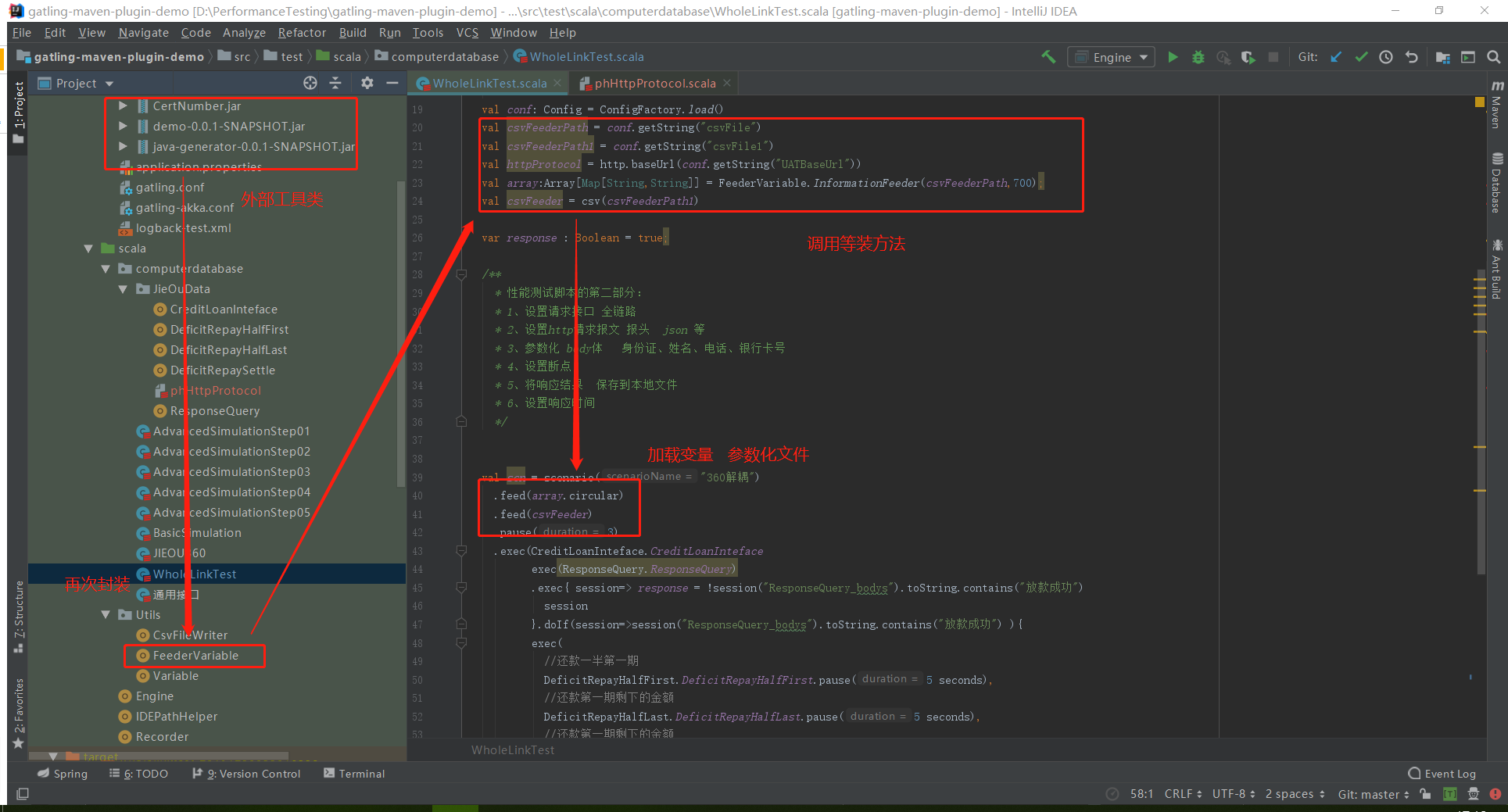
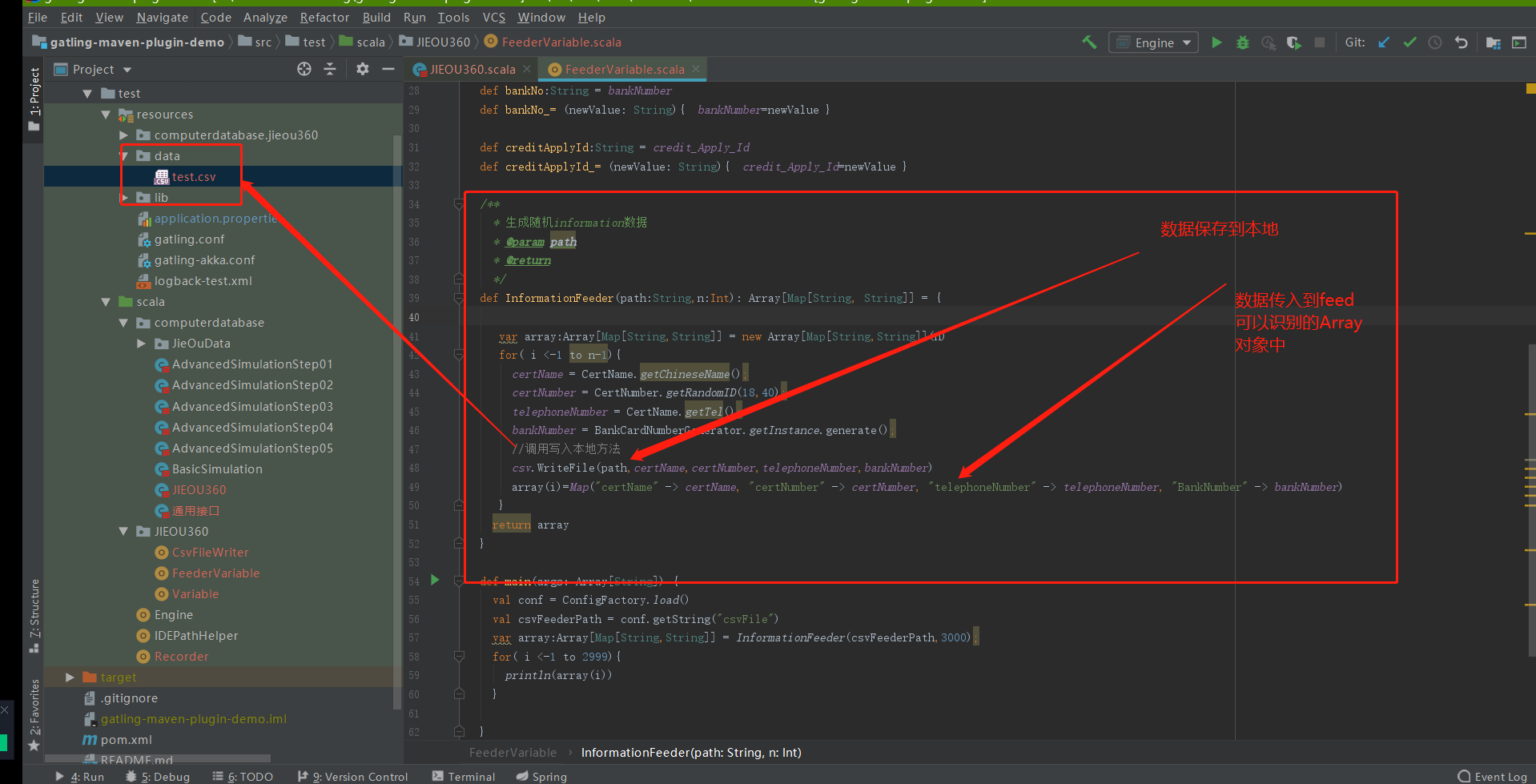
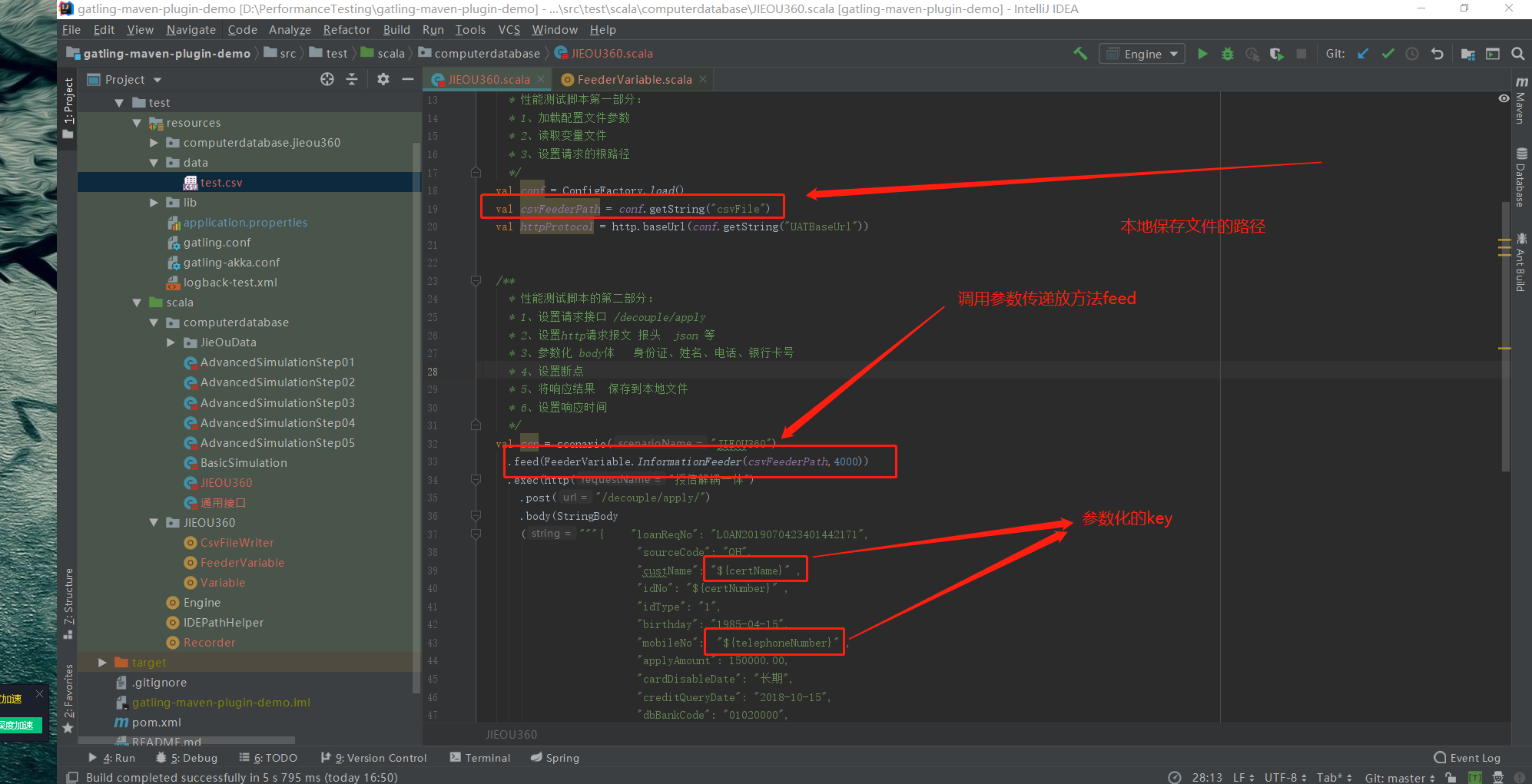
1、需要注意的是feed在整个请求过程中只加载一次传递参数的文件 也就是谁所有的传递的参数需要提前构造好 然后一次性加载到场景中
2、创建一个构造数据的脚本
实现两个功能:
随机生成的参数保存到本地
留作备用定位问题使用 随机生成的参数传递到Array中
Gatling脚本编写技巧篇(二)的更多相关文章
- Gatling脚本编写技巧篇(一)
一.公共类抽取 熟悉Gatling的同学都知道Gatling脚本的同学都知道,Gatling的脚本包含三大部分: http head配置 Scenario 执行细节 setUp 组装 那么针对三部分我 ...
- 《手把手教你》系列技巧篇(二十五)-java+ selenium自动化测试-FluentWait(详细教程)
1.简介 其实今天介绍也讲解的也是一种等待的方法,有些童鞋或者小伙伴们会问宏哥,这也是一种等待方法,为什么不在上一篇文章中竹筒倒豆子一股脑的全部说完,反而又在这里单独写了一篇.那是因为这个比较重要,所 ...
- 《手把手教你》系列技巧篇(二十七)-java+ selenium自动化测试- quit和close的区别(详解教程)
1.简介 尽管有的小伙伴或者童鞋们觉得很简单,不就是关闭退出浏览器,但是宏哥还是把两个方法的区别说一下,不然遇到坑后根本不会想到是这里的问题. 2.源码 本文介绍webdriver中关于浏览器退出操作 ...
- 《手把手教你》系列技巧篇(五十二)-java+ selenium自动化测试-处理面包屑(详细教程)
1.简介 面包屑(Breadcrumb),又称面包屑导航(BreadcrumbNavigation)这个概念来自童话故事"汉赛尔和格莱特",当汉赛尔和格莱特穿过森林时,不小心迷路了 ...
- BAT脚本编写教程简单入门篇
BAT脚本编写教程简单入门篇 批处理文件最常用的几个命令: echo表示显示此命令后的字符 echo on 表示在此语句后所有运行的命令都显示命令行本身 echo off 表示在此语句后所有运行的命 ...
- BAT脚本编写教程入门提高篇
BAT脚本编写教程入门提高篇 批处理文件的参数 批处理文件还可以像C语言的函数一样使用参数(相当于DOS命令的命令行参数),这需要用到一个参数表示符“%”. %[1-9]表示参数,参数是指在运行批处理 ...
- X86逆向15:OD脚本的编写技巧
本章节我们将学习OD脚本的使用与编写技巧,脚本有啥用呢?脚本的用处非常的大,比如我们要对按钮事件进行批量下断点,此时使用自动化脚本将大大减小我们的工作量,再比如有些比较简单的压缩壳需要脱壳,此时我们也 ...
- LoadRunner脚本编写之二
LoadRunner脚本编写之二 编程基本语法必须要记牢.程序的思想也很重要. 下面来回顾一下嵌套循环例子. Action() { int i,j; //生命两个变量 for ( ...
- 《手把手教你》系列技巧篇(二十三)-java+ selenium自动化测试-webdriver处理浏览器多窗口切换下卷(详细教程)
1.简介 上一篇讲解和分享了如何获取浏览器窗口的句柄,那么今天这一篇就是讲解获取后我们要做什么,就是利用获取的句柄进行浏览器窗口的切换来分别定位不同页面中的元素进行操作. 2.为什么要切换窗口? Se ...
随机推荐
- 【深度学习】perceptron(感知机)
目录 1.感知机的描述 2.感知机解决简单逻辑电路,与门的问题. 2.多层感应机,解决异或门 个人学习笔记,有兴趣的朋友可参考. 1.感知机的描述 感知机(perceptron)由美国学者Frank ...
- Building Applications with Force.com and VisualForce(Dev401)(十三):Implementing Business Processes:Automating Business Processes Part II
ev401-014:Implementing Business Processes:Automating Business Processes Part II Module Agenda1.Multi ...
- HDU - 1317 ~ SPFA正权回路的判断
题意:有最多一百个房间,房间之间连通,到达另一个房间会消耗能量值或者增加能量值,求是否能从一号房间到达n号房间. 看数据,有定5个房间,下面有5行,第 iii 行代表 iii 号 房间的信息,第一个数 ...
- Sublimeの虚拟环境(Venv)设置
这里主要介绍,在使用 Python 虚拟环境(Venv)时,SublimeText 该怎么设置 为什么使用虚拟环境(Venv) 因为,我有洁癖! 我就是喜欢看到,pip list 命令下什么 Pack ...
- js数据类型及方法
数据类型及方法 数据类型 number 不区分整数和浮点数 string 字符串 boolean true / false 布尔 object null 数组 function 函数 undefine ...
- Python python对象 enumerate
""" enumerate(iterable[, start]) -> iterator for index, value of iterable Return a ...
- [vijos1145]小胖吃巧克力<概率dp>
题目链接:https://vijos.org/p/1145 貌似还有一个一样的题是poj1322 chocolate,两个题只是描述不一样,意思都是一样的,不贵最近貌似poj炸了,所以也没法去poj ...
- 程序开发中的术语,如IDE,OOP等等
我们在开发程序过程中,会用到一些与编译有关的术语,比如:[编辑器.编译器.调试器.连接器,链接器.解释器,集成开发环境(Integrated Development Environment,IDE). ...
- ubuntu上安装lamp环境命令清单
#install configuration manager sudo apt-get install tasksel #install basic lamp stack sudo tasksel i ...
- 在.net core中完美解决多租户分库分表的问题
前几天有人想做一个多租户的平台,每个租户一个库,可以进行水平扩展,应用端根据登录信息,切换到不同的租户库 计划用ef core实现,他们说做不出来,需要动态创建dbContext,不好实现 然而这个使 ...