KNN分类算法
K邻近算法、K最近邻算法、KNN算法(k-Nearest Neighbour algorithm):是数据挖掘分类技术中最简单的方法之一
KNN的工作原理
所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。KNN算法的核心思想是如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 可以简单理解为:由那些离X最近的K个点来投票决定X归为哪一类。KNN方法在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
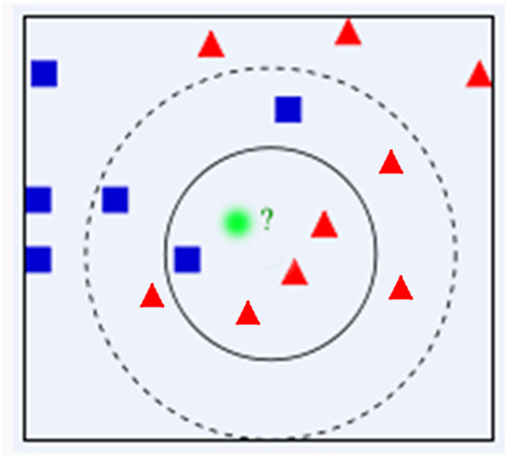
图中有红色三角和蓝色方块两种类别,我们现在需要判断绿色圆点属于哪种类别当k=3时,绿色圆点属于红色三角这种类别;当k=5时,绿色圆点属于蓝色方块这种类别
KNN的算法步骤
- 计算已知类别数据集中的点与当前点之间的距离
- 按照距离递增次序排序
- 选取与当前点距离最小的k个点
- 确定前k个点所在类别的出现频率
- 返回前k个点出现频率最高的类别作为当前点的预测类别
KNN的算法优缺点
优点
- 思想简单
- 易于理解
- 容易实现
- 通过对K的选择可具备丢噪音数据的健壮性
缺点
- 需要大量空间储存所有已知实例
- 算法复杂度高(需要比较所有已知实例与要分类的实例)
- 当其样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例实际并未接近目标样本
KNN的Python实现
在了解k-近邻算法的原理及实施步骤之后,我们用python将这些过程实现
Python实现步骤
import numpy as np
import matplotlib.pyplot as plt # 原始集合
# 数据集:特征
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]]
# 数据集:所属类别
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# 训练集合
X_train = np.array(raw_data_X) # 将x转化为数组
y_train = np.array(raw_data_y) # 将y转化为数组
# 要预测的点
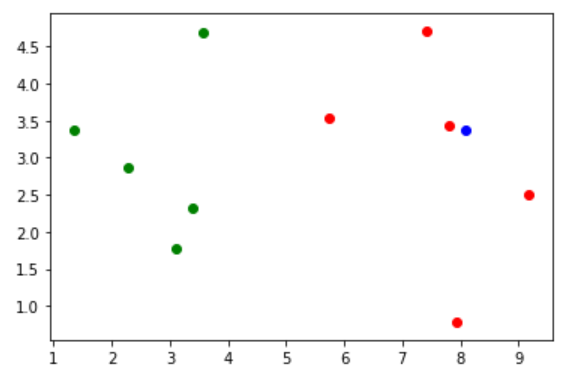
预测
x = np.array([8.093607318, 3.365731514]) # 样本传入
"""
绘制数据集及要预测的点
y_train == 0, 0 --> 返回布尔值
"""
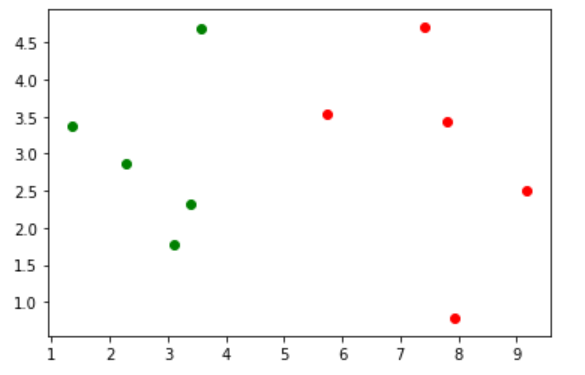
plt.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], color='g') # 绘画0类数据
plt.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], color='r') # 绘画1类数据
plt.show()
 KNN实现过程
KNN实现过程
from math import sqrt
import numpy as np
# 算新的样本点与现有样本点之间的距离
# 对所有数据集循环,再对差的平方求和,即距离
"""
distances = []
for x_train in X_train:
d = sqrt(np.sum((x_train - x)**2))
distances.append(d)
"""
distances = [sqrt(np.sum((x_train - x)**2)) for x_train in X_train] # 最近邻样本个数
k=6
# 返回排序后的结果的索引,也就是距离测试点距离最近的点的排序坐标数组
nearest = np.argsort(distances) # 投票
# 求出距离测试点最近的6个点的类别
topK_y = [y_train[neighbor] for neighbor in nearest[:k]]
# collections的Counter方法可以求出一个数组的相同元素的个数,返回一个dict{key=元素名, value= 元素个数}
from collections import Counter
votes = Counter(topK_y)
# most_common方法求出最多的元素对应的那个键值对
votes.most_common(1)
predict_y = votes.most_common(1)[0][0]
KNN算法封装
import numpy as np
from math import sqrt
from collections import Counter def KNN_classify(X_train,Y_train,x,k):
"""
dist = []
for x_train in X_train:
d = sqrt(np.sum((x_train - x) ** 2))
dist.append(d)
"""
dist = [sqrt(np.sum((x_train - x) ** 2)) for x in x_train ]
nearest = np.argsort(dist); # 取得排序后的索引列表
topk_y = [Y_train[i] for i in nearest[:k]] # 分别取得6个点并获取Y类对应索引的数据
votes = Counter(topk_y)
v = votes.most_common(1)[0][0] # 从产生的字典中获取key,就是对应的类别
return v # 特征
raw_data_x= [
[3.393533211,2.331273381],
[2.110073483,1.781539638],
[1.343808831,3.368360954],
[3.582294042,4.679179110],
[2.280362439,2.866990263],
[7.423436942,4.696522875],
[5.745051997,3.533989803],
[9.172168622,2.511101045],
[7.792783481,3.424088941],
[7.939820817,0.791637231]
]
# 所述类别
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
X_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
# 要预测的点
x = np.array([8.093607318,3.365731514]) # 调用方法
predict_y = KNN_classify(X_train , y_train , x, 6)
print(predict_y)
机器学习套路
可以说KNN是一个不需要训练过程的算法 K近邻算法是非常特殊的,可以被认为是没有模型的算法 为了和其他算法统一,可以认为训练数据集就是模型
SKLEARN库中的KNN算法实现
from sklearn.neighbors import KNeighborsClassifier
import numpy as np raw_data_x =[[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# 要预测的点
x = np.array([8.093607318, 3.365731514]) #测试数据 KNN_classfiy = KNeighborsClassifier(n_neighbors=6)
KNN_classfiy.fit(raw_data_x,raw_data_y)
#predict_y = KNN_classfiy.predict(x) #注意要将X转为一个矩阵
predict_y = KNN_classfiy.predict(x.reshape(1,-1))
print(predict_y[0])
封装自己的KNN
import numpy as np
from math import sqrt
from collections import Counter class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器""" assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self def predict(self, X_predict):
"""给定待预测数据集X_predict,返回标示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None, \
"mush fit before predict"
assert self._X_train.shape[1] == X_predict.shape[1], \
"the feature number of x must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict) def _predict(self, x):
"""给定单个待预测数据x,返回x的预测结果值"""
distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in self._X_train]
nearset = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearset[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0] kNN_classifier = KNNClassifier(6)
# 特征
raw_data_x = [
[3.393533211, 2.331273381],
[2.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]
]
# 所述类别
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
X_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
# 要预测的点
x = np.array([8.093607318, 3.365731514])
kNN_classifier.fit(X_train, y_train)
X_predict = x.reshape(1, -1)
kNN_classifier.predict(X_predict)
y_predict = kNN_classifier.predict(X_predict)
print(y_predict[0])
鸢尾花结果评估测试
import numpy as np
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# 加载数据集
iris = datasets.load_iris();
# 数据
x = iris.data
# 分类标签
y = iris.target
# 训练集,测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.6,random_state=666)
# 分类器
KNN_classfiy = KNeighborsClassifier(n_neighbors=6)
# 训练
KNN_classfiy.fit(x_train,y_train)
y_predict=KNN_classfiy.predict(x_test)
print(sum(y_test==y_predict)/len(y_test))
数据归一化处理
推荐一个在线公式编辑器:http://latex.codecogs.com/eqneditor/editor.php
如果计算两点间的距离,发现样本间的距离被时间所主导。解决方案:将所有的数据映射到同一尺度
- 最终归一化:把所有数据映射到0-1之间
$x_{scale}=\frac{x-x_{min}}{x_{max}-x_{min}}$
适用于分布有明显边界的情况
- 均值方差归一化:把所有数据归一到均值为0方差为1的分布中
数据分布没有明显边界,有可能存在极端数据值
$x_{scale}=\frac{x-x_{mean}}{S}$
划分训练集和测试集
前面概述部分我们有提到,为了测试分类器的效果,我们可以把原始数据集分为训练集和测试集两部分,训练集用来训练模型,测试集用来验证模型准确率。
关于训练集和测试集的切分函数,Scikit Learn官网上也有相应的函数比如model selection 类中的train_test_split 函数也可以完成训练集和测试集的切分。
通常来说,我们只提供已有数据的90%作为训练样本来训练模型,其余10%的数据用来测试模型。这里需要注意的10%的测试数据一定要是随机选择出来的,由于海伦提供的数据并没有按照特定的目的来排序,所以我们这里可以随意选择10%的数据而不影响其随机性
算法总结
k-近邻
算法功能 分类(核心),回归
|
算法类型 |
有监督学习 - 惰性学习,距离类模型 |
|
包含数据标签y,且特征空间中至少包含k个训练样本(k>=1) |
|
|
数据输入 |
特征空间中各个特征的量纲需统一,若不统一则需要进行归一化处理 |
|
自定义的超参数k (k>=1) |
|
|
模型输出 |
在KNN分类中,输出是标签中的某个类别 |
|
在KNN回归中,输出是对象的属性值,该值是距离输入的数据最近的k个训练样本标签的平均值 |
优点
- 简单好用,容易理解,精度高,理论成熟,既可以用来做分类也可以用来做回归
- 可用于数值型数据和离散型数据
- 无数据输入假定
- 适合对稀有事件进行分类
缺点
- 计算复杂性高;空间复杂性高
- 计算量太大,所以一般数值很大的时候不用这个,但是单个样本又不能太少,否则容易发生误分
- 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)
- 可理解性比较差,无法给出数据的内在含义
KNN分类算法的更多相关文章
- knn分类算法学习
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的 ...
- KNN分类算法实现手写数字识别
需求: 利用一个手写数字“先验数据”集,使用knn算法来实现对手写数字的自动识别: 先验数据(训练数据)集: ♦数据维度比较大,样本数比较多. ♦ 数据集包括数字0-9的手写体. ♦每个数字大约有20 ...
- KNN分类算法及python代码实现
KNN分类算法(先验数据中就有类别之分,未知的数据会被归类为之前类别中的某一类!) 1.KNN介绍 K最近邻(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法. 机器学习, ...
- 机器学习---K最近邻(k-Nearest Neighbour,KNN)分类算法
K最近邻(k-Nearest Neighbour,KNN)分类算法 1.K最近邻(k-Nearest Neighbour,KNN) K最近邻(k-Nearest Neighbour,KNN)分类算法, ...
- 后端程序员之路 12、K最近邻(k-Nearest Neighbour,KNN)分类算法
K最近邻(k-Nearest Neighbour,KNN)分类算法,是最简单的机器学习算法之一.由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重 ...
- 在Ignite中使用k-最近邻(k-NN)分类算法
在本系列前面的文章中,简单介绍了一下Ignite的线性回归算法,下面会尝试另一个机器学习算法,即k-最近邻(k-NN)分类.该算法基于对象k个最近邻中最常见的类来对对象进行分类,可用于确定类成员的关系 ...
- KNN分类算法--python实现
一.kNN算法分析 K最近邻(k-Nearest Neighbor,KNN)分类算法可以说是最简单的机器学习算法了.它采用测量不同特征值之间的距离方法进行分类.它的思想很简单:如果一个样本在特征空间中 ...
- OpenCV——KNN分类算法 <摘>
KNN近邻分类法(k-Nearest Neighbor)是一个理论上比较成熟的方法,也是最简单的机器学习算法之一. 这个算法首先贮藏所有的训练样本,然后通过分析(包括选举,计算加权和等方式)一个新样本 ...
- KNN分类算法补充
KNN补充: 1.K值设定为多大? k太小,分类结果易受噪声点影响:k太大,近邻中又可能包含太多的其它类别的点. (对距离加权,可以降低k值设定的影响) k值通常是采用交叉检验来确定(以k=1为基准) ...
随机推荐
- 【VS开发】socket编程原理
socket编程原理 1.问题的引入 1) 普通的I/O操作过程: UNIX系统的I/O命令集,是从Maltics和早期系统中的命令演变出来的,其模式为打开一读/写一关闭(open-write-rea ...
- idea连接docker实现一键部署
一.修改配置文件,打开2375端口 [root@microservice ~]# vim /usr/lib/systemd/system/docker.service 在ExecStart=/usr/ ...
- 20个「MySQL」经典面试题,答对转dba 2w+「附答案」
1.MySQL的复制原理以及流程 基本原理流程,3个线程以及之间的关联: 2.MySQL中myisam与innodb的区别,至少5点 (1).问5点不同: (2).innodb引擎的4大特性 (3). ...
- *【Python】【demo实验30】【练习实例】【使用Turtle实现实时时钟效果】
目的: 使用Turtle实现实时时钟效果 源代码: # encoding=utf-8 # -*- coding: UTF-8 -*- import turtle from datetime impor ...
- Kafka如何实现每秒上百万的高并发写入
Kafka是高吞吐低延迟的高并发.高性能的消息中间件,在大数据领域有极为广泛的运用.配置良好的Kafka集群甚至可以做到每秒几十万.上百万的超高并发写入. 那么Kafka到底是如何做到这么高的吞吐量和 ...
- linux内核编程入门 hello world
注意: Makefile 文件的命名注意M需要大写,否则会报错. 在Makefile文件中make命令前应为tab制表符. 下文转载至:https://blog.csdn.net/bingqing07 ...
- MySQL8在CentOS7上的安装
Install_CentOS7_MySQL8_binary.sh #!/bin/bash MySQL_Package=mysql-8.0.16-linux-glibc2.12-x86_64.tar.x ...
- ASP.NET Core MVC里面Razor如何获取URL参数
原文:ASP.NET Core MVC里面Razor如何获取URL参数 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https:// ...
- C# 定义热键
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- js 动态添加Table tr,选中与不选中checkbox行数NO的变化
首次加载进入页面,如图: 注:Table是在js中拼接字符串循环动态添加的(拼接字符串,详见之前随笔) 点击Line2 checkbox后,效果如图: 实现的效果就是: 点击checkbox — 显示 ...