scrapy 五大核心组件-分页
scrapy 五大核心组件-分页
分页
思路
总的原理和之前是一样的,但是由于框架的原因,要遵循他框架的使用方式,每次更改他的url,并指定回调函数
# -*- coding: utf-8 -*-
import scrapy
class XiaohuanameSpider(scrapy.Spider):
name = 'xiaohuaname'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.xiaohuar.com/list-1-0.html']
url=""
num=1
def parse(self, response):
names=response.xpath('//div[@class="title"]/span/a/text()')
for i in names:
print(i.extract())
#更改下一次请求的url
self.url=f'http://www.xiaohuar.com/list-1-{self.num}.html'
self.num+=1
#获取10页的数据
if self.num < 10:
#配置下次请求的url和回调函数
yield scrapy.Request(url=self.url,callback=self.parse)
五大核心组件
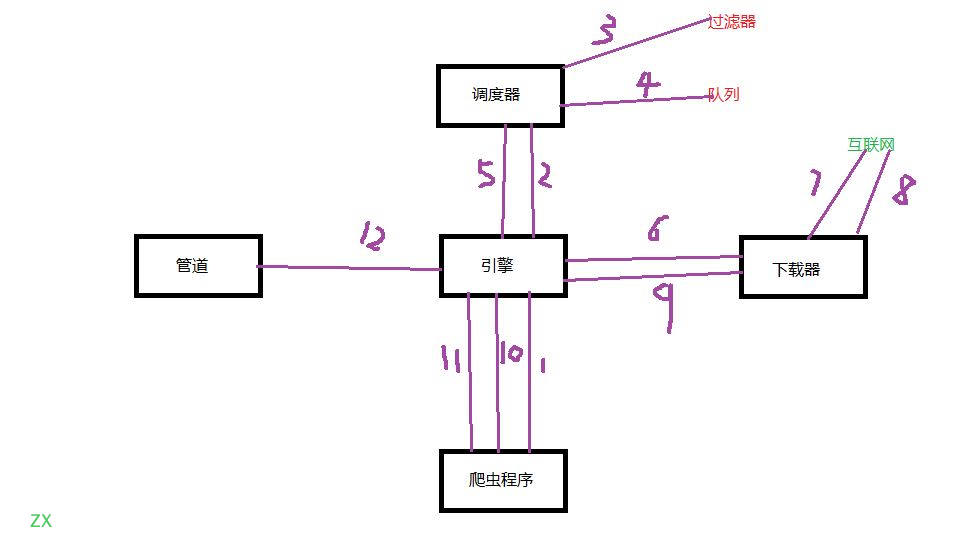
引擎(Scrapy)
(创建对象,根据数据调度方法等)
用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
执行流程
1.爬虫程序将url封装后发送给引擎
2.引擎拿到url后,把它给调度器
3.调度器首先过滤重复的url
4.将过滤好的url压入队列
5.将队列发给引擎
6.引擎将队列发给下载器
7.下载器向互联网请求数据
8.获取数据
9.将数据response发给引擎
10.引擎将数据发给爬虫程序的回调
11.数据处理好,在此发给引擎
12.引擎将数据发给管道,由管道进行数据的持久化存储
scrapy 五大核心组件-分页的更多相关文章
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
- scrapy五大核心组件
scrapy五大核心组件 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- scrapy五大核心组件和中间件以及UA池和代理池
五大核心组件的工作流程 引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- Scrapy五大核心组件简介
五大核心组件 scrapy框架主要由五大组件组成,他们分别是调度器(Scheduler),下载器(Downloader),爬虫(Spider),和实体管道(Item Pipeline),Scrapy引 ...
- 爬虫-scrapy五大核心组件及工作流
- scrapy之五大核心组件
scrapy之五大核心组件 scrapy一共有五大核心组件,分别为引擎.下载器.调度器.spider(爬虫文件).管道. 爬虫文件的作用: a. 解析数据 b. 发请求 调度器: a. 队列 队列是一 ...
- Scrapy 框架 安装 五大核心组件 settings 配置 管道存储
scrapy 框架的使用 博客: https://www.cnblogs.com/bobo-zhang/p/10561617.html 安装: pip install wheel 下载 Twisted ...
- scrapy框架post请求发送,五大核心组件,日志等级,请求传参
一.post请求发送 - 问题:爬虫文件的代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢? - 解答: ...
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
随机推荐
- 在虚拟机上的关于Apache(阿帕奇)(3)基于IP访问网站
这篇随笔是基于IP访问网站,和后面两篇文章基于域名和基于端口一起练习效果更好 基于IP(记得下载httpd服务) 首先使用nmtui命令为网卡添加多个ip地址 输入命令:nmtui 进入下面这个界 ...
- 求和:fft,表达式化简
$f(n)=\sum\limits_{i=0}^{n} \sum\limits_{j=0}^{i} S(i,j) \times 2^j \times j!$ 其中$S(i,j)$为第二类斯特林数,公式 ...
- synchronized和ReentrantLock锁住了谁?
一.synchronized 案例1: public class LockDemo{ public static void main(String[] args) throws Exception { ...
- kubespray2.11安装kubernetes1.15
关于kubespray Kubespray是开源的kubernetes部署工具,整合了ansible,可以方便的部署高可用集群环境,官网地址:https://github.com/kubernetes ...
- node真的是单线程模式吗
提到node,我们就可以立刻想到单线程.异步IO.事件驱动等字眼.首先要明确的是node真的是单线程的吗,如果是单线程的,那么异步IO,以及定时事件(setTimeout.setInterval等)又 ...
- arduino体感控制简单版
https://learn.sparkfun.com/tutorials/apds-9960-rgb-and-gesture-sensor-hookup-guide/all 硬件连线 关键 VCC= ...
- C++对象模型结论
C++对象模型 1.C++对象模型探讨的是对象成员存储问题. 2.结论: (1) .类内部的函数(静态成员函数,非静态成员函数)都不在对象内部 ,不占用对象大小. (2) 类内部的静态变量不占用对象大 ...
- 在VMware15.5中安装CentOS7_7_64bit
一.创建虚拟机 在我的另一个随笔里有. 地址为:https://www.cnblogs.com/qi-yuan/p/11692092.html 只是在虚拟机安装操作系统时候选择 Linux 而不是 W ...
- 基于R数据分析之常用Package讲解系列--1. data.table
利用data.table包变形数据 一. 基础概念 data.table 这种数据结构相较于R中本源的data.frame 在数据处理上有运算速度更快,内存运用更高效,可认为它是data.frame ...
- 【Java】面向对象初探
前段时间经历了一段心态浮躁期,这让我想起了自己最初的计划,要提升自己知识体系的广度.前几年一直做的是web前端这一块的工作,但我希望通过自己在学习Java这样的过程来提升自己的知识广度. 面向对象概述 ...