Scrapy五大核心组件简介
五大核心组件
scrapy框架主要由五大组件组成,他们分别是调度器(Scheduler),下载器(Downloader),爬虫(Spider),和实体管道(Item Pipeline),Scrapy引擎(Scrapy Fngine)
下面我们说说他们各自的作用:
调度器
用来接受引擎发过来的请求,由过滤器重复的url并将其压入队列中,在引擎再次请求的时候返回,
可以想象成一个URL(抓取网页的网址或者说是链接)的优先队列,由他决定下一个要抓取的网址是什么,用户可以根据自己的需求定制调度器
下载器
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源,Scrapy的下载器代码不会太复杂,但效率高(原因:Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫
爬虫是主要干活的,用户最关心的部分, 它可以生成url, 并从特定的url中提取自己需要的信息, 即所谓的实体(Item). 用户也可以从中提取出链接, 让Scrapy继续抓取下一个页面.
实体管道
负责处理爬虫从网页中抽取的实体, 主要的功能是持久化实体、验证实体的有效性、清除不需要的信息. 当页面被爬虫解析后, 将被发送到项目管道, 并经过几个特定的次序处理数据.
引擎
Scrapy引擎是整个框架的核心。它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。对整个系统的数据流进行处理, 触发事务(框架核心).
工作流程
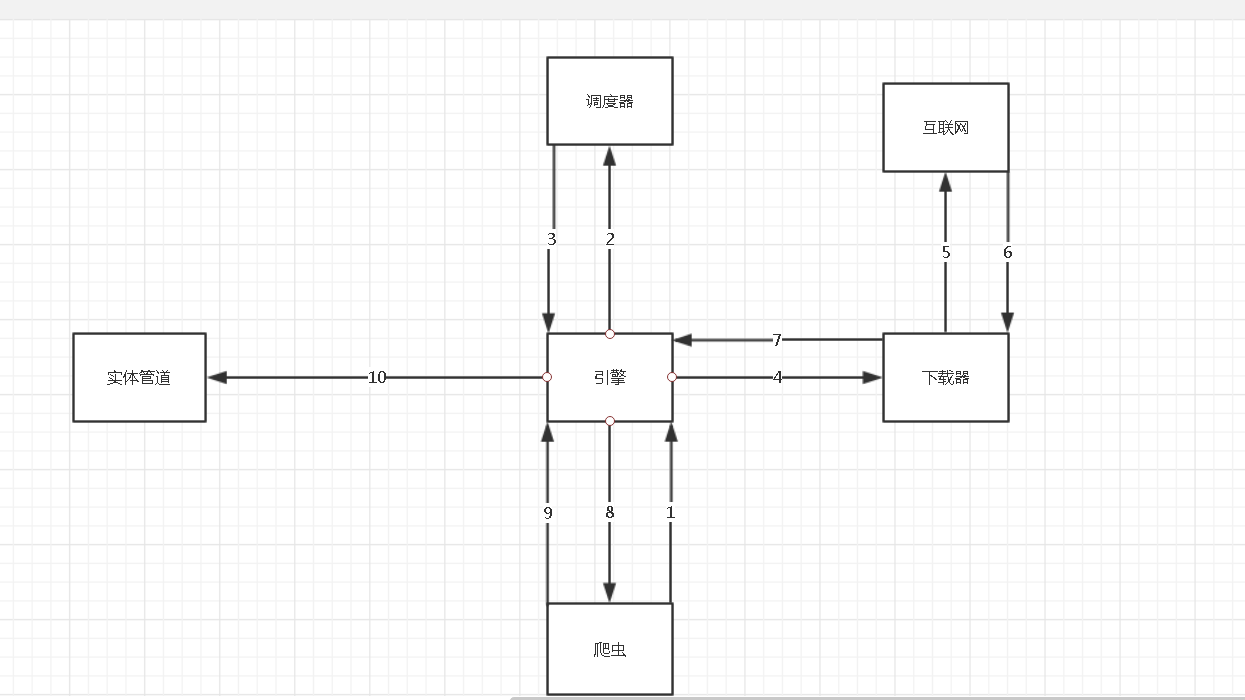
步骤详解:
1.spider中的url被封装成请求对象交给引擎(每一个对应一个请求对象)
2.引擎拿到请求对象之后,将全部交给调度器
3.调度器闹到所有请求对象后,通过内部的过滤器过滤掉重复的url,最后将去重后的所有url对应的请求对象压入到队列中,随后调度器调度出其中一个请求对象,并将其交给引擎
4.引擎将调度器调度出的请求对象交给下载器
5.下载器拿到该请求对象去互联网中下载数据
6.数据下载成功后会被封装到response中,随后response会被交给下载器
7.下载器将response交给引擎
8.引擎将response交给spiders
9.spiders拿到response后调用回调方法进行数据解析,解析成功后生成item,随后spiders将item交给引擎
10引擎将item交给管道,管道拿到item后进行数据的持久化存储
Scrapy五大核心组件简介的更多相关文章
- scrapy 五大核心组件-分页
scrapy 五大核心组件-分页 分页 思路 总的原理和之前是一样的,但是由于框架的原因,要遵循他框架的使用方式,每次更改他的url,并指定回调函数 # -*- coding: utf-8 -*- i ...
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
- scrapy五大核心组件
scrapy五大核心组件 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- scrapy五大核心组件和中间件以及UA池和代理池
五大核心组件的工作流程 引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- 爬虫-scrapy五大核心组件及工作流
- scrapy之五大核心组件
scrapy之五大核心组件 scrapy一共有五大核心组件,分别为引擎.下载器.调度器.spider(爬虫文件).管道. 爬虫文件的作用: a. 解析数据 b. 发请求 调度器: a. 队列 队列是一 ...
- Scrapy 框架 安装 五大核心组件 settings 配置 管道存储
scrapy 框架的使用 博客: https://www.cnblogs.com/bobo-zhang/p/10561617.html 安装: pip install wheel 下载 Twisted ...
- scrapy框架post请求发送,五大核心组件,日志等级,请求传参
一.post请求发送 - 问题:爬虫文件的代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢? - 解答: ...
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
随机推荐
- 2018-2-13-wpf-PreviewTextInput-在鼠标输入获得-_u0003
title author date CreateTime categories wpf PreviewTextInput 在鼠标输入获得 � lindexi 2018-2-13 17:23:3 +08 ...
- Oracle查询表里的重复数据方法
select id from group by id having count(*) > 1 按照id分组并计数,某个id号那一组的数量超过1条则认为重复. 如何查询重复的数据 select 字 ...
- JavaScript-JQ实现自定义滚动条插件1.0
此滚动条仅支持竖向(Y轴) 一.Css /*这里是让用户鼠标在里面不能选中文字,避免拖动的时候出错*/ body { -moz-user-select: none; /*火狐*/ -webkit-us ...
- JavaScript文件与HTML文件本地连接
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Django与HTML业务基本结合--基本的用户名密码提交方法2
from django.shortcuts import render # Create your views here. from django.shortcuts import render de ...
- 项目ITP(七) javaWeb 整合 Quartz 实现动态调度 而且 持久化
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/u010378410/article/details/36255511 项目ITP(七) javaWe ...
- delete records in table A not in table B
转)A.B两表,找出ID字段中,存在A表,但是不存在B表的数据.A表总共13w数据,去重后大约3W条数据,B表有2W条数据,且B表的ID字段有索引. 方法一 使用 not in ,容易理解,效率低 ...
- linux 下配置多个tomcat同时运行
一个服务器上内存通常有2G或者更多,一个tomcat 运行管理这么多内存有点力不从心,并且貌似一个进程所能建立的线程数量是有限的,于是我们想要在一个服务器上运行多个tomcat.如下是摘抄自:http ...
- pom.xml中若出现jar not found;
pom.xml中若出现jar not found;我们可以直接在view ->tool windows ->Maven Project 中直接install
- 微信公众号系统在Linux下的部署操作
ps -ef | grep tomcat 查看tomcat进程