scrapy五大核心组件和中间件以及UA池和代理池
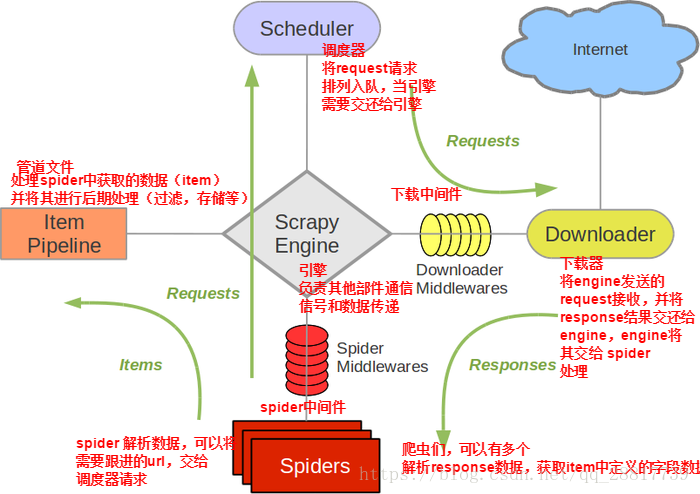
五大核心组件的工作流程
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面,会产生一个或者一批url
- 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
Spiders将url封装成请求对象传递给引擎,引擎将接受到的对象传递给调度器,调度器将重重复的请求对象去重利用过滤器的类过滤,然后将过滤完成之后的请求对象存到队列中。调度器再将请求对象传递给引擎,然后引擎再将请求对象给下载器,下载器接收到请求对象然后从互联网上下载,互联网将响应对象给下载器,下载器再将响应对象传递给引擎,引擎再将响应对象给spider中的回调方法的response,然后对数据进行解析,然后将解析的对象封装到item对象中,然后给引擎,引擎提交管道,管道收到items之后,调用parse_items方法,将数据进行持久化的存储
Downloader Middlewares
middlewares.py
class MiddleproDownloaderMiddleware(object):
#UA
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 可被选用的代理IP
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
]
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects. @classmethod
def from_crawler(cls, crawler):#实例化生成中间件对象
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s def process_request(self, request, spider):#拦截所有正常的请求
# Called for each request that goes through the downloader
# middleware. # Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
# 使用UI池进行对请求的UI伪装
print('this is process_request')
request.headers['User-Agent'] = random.choice(self.user_agent_list)
print(request.headers['User-Agent'])
return None def process_response(self, request, response, spider):#拦截所有的响应
# Called with the response returned from the downloader. # Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response def process_exception(self, request, exception, spider):#拦截到发生异常的请求
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception. # Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
if request.url.split(":")[0] == 'http':
request.meta['proxy'] = random.choice(self.PROXY_http)
else:
request.meta['proxy'] = random.choice(self.PROXY_https) def spider_opened(self, spider):#日志打印
spider.logger.info('Spider opened: %s' % spider.name)
scrapy五大核心组件和中间件以及UA池和代理池的更多相关文章
- scrapy下载中间件,UA池和代理池
一.下载中间件 框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器过程中, 下载中间件可以对请 ...
- scrapy 五大核心组件-分页
scrapy 五大核心组件-分页 分页 思路 总的原理和之前是一样的,但是由于框架的原因,要遵循他框架的使用方式,每次更改他的url,并指定回调函数 # -*- coding: utf-8 -*- i ...
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
- scrapy五大核心组件
scrapy五大核心组件 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- 爬虫的UA池和代理池
爬虫的UA池和代理池 一.下载中间件 先祭出框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下 ...
- 10 UA池和代理池
在Scrapy中,引擎和下载器之间有一个组件,叫下载中间件(Downloader Middlewares).因它是介于Scrapy的request/response处理的钩子,所以有2方面作用: (1 ...
- 12-UA池和代理池
一.UA池和代理池 1.UA池 scrapy的下载中间件: 下载中间件(Downloader Middlewares) 位于s ...
- UA池和代理池在scrapy中的应用
一.下载中间件 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器过程中, 下载中间件可以对请求进行一系 ...
- 爬虫开发13.UA池和代理池在scrapy中的应用
今日概要 scrapy下载中间件 UA池 代理池 今日详情 一.下载中间件 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: ( ...
随机推荐
- linux配置多个ip
linux配置多个ip /sbin/ifconfig eth0:1 172.19.121.180 broadcast 172.19.121.255 netmask 255.255.255.0 up ...
- :成功配置 centos + nginx + .net core 2.0
https://segmentfault.com/a/1190000010763523
- 【HANA系列】SAP HANA XS Administration Tool登录参数设置
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP HANA XS Admi ...
- python每日一练:0002题
第 0002 题:将 0001 题生成的 200 个激活码(或者优惠券)保存到 MySQL 关系型数据库中. 示例代码: import os import string import random i ...
- [转帖]小米手环采用RISC-V 指令集芯片
小米手环4或用“黄山一号”芯片,雷军再回前线,未来走向如何 静心科技 06-1111:19 忘记来源地址了 不过国内的很多东西都是有中国特色的 比如飞腾 比如麒麟(银河麒麟 还有华为的麒麟 980) ...
- [转帖]SSH命令总结
SSH命令总结 ssh-keygen ssh-copy-id 等命令自己用过 但是知道的不系统 也知道 转发命令 但是也只是知道一点点... ttps://www.cnblogs.com/chenfa ...
- mybatis 批量操作 ------持续更新
mybatis 不存在则才进行添加 # 添加的 sql 语句insert into sys_link_post_user(post_id,user_id)# 进行批量添加 (若不需要可以取消 froe ...
- PythonDay12
day12内置_函数 今日内容 生成器 推导式 内置函数一 生成器 什么是生成器?生成器的本质就是一个迭代器 迭代器是python自带的 生成器是程序员自己写的一种迭代器 生成器编写方式: 1.基于函 ...
- 自己动手实现一个html2canvas
前言 昨天写了新手引导动画的4种实现方式,里面用到了 html2canvas 于是就顺便了解了一下实现思路. 大概就是 利用 svg 的 foreignObject 标签, 嵌入 dom, 最后再利用 ...
- 2015 四川省赛 C Censor(哈希 | KMP)
模式串为子串 KMP /* @author : victor */ #include <bits/stdc++.h> using namespace std; typedef long l ...