scrapy 五大核心组件-分页
scrapy 五大核心组件-分页
分页
思路
总的原理和之前是一样的,但是由于框架的原因,要遵循他框架的使用方式,每次更改他的url,并指定回调函数
# -*- coding: utf-8 -*-
import scrapy
class XiaohuanameSpider(scrapy.Spider):
name = 'xiaohuaname'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.xiaohuar.com/list-1-0.html']
url=""
num=1
def parse(self, response):
names=response.xpath('//div[@class="title"]/span/a/text()')
for i in names:
print(i.extract())
#更改下一次请求的url
self.url=f'http://www.xiaohuar.com/list-1-{self.num}.html'
self.num+=1
#获取10页的数据
if self.num < 10:
#配置下次请求的url和回调函数
yield scrapy.Request(url=self.url,callback=self.parse)
五大核心组件
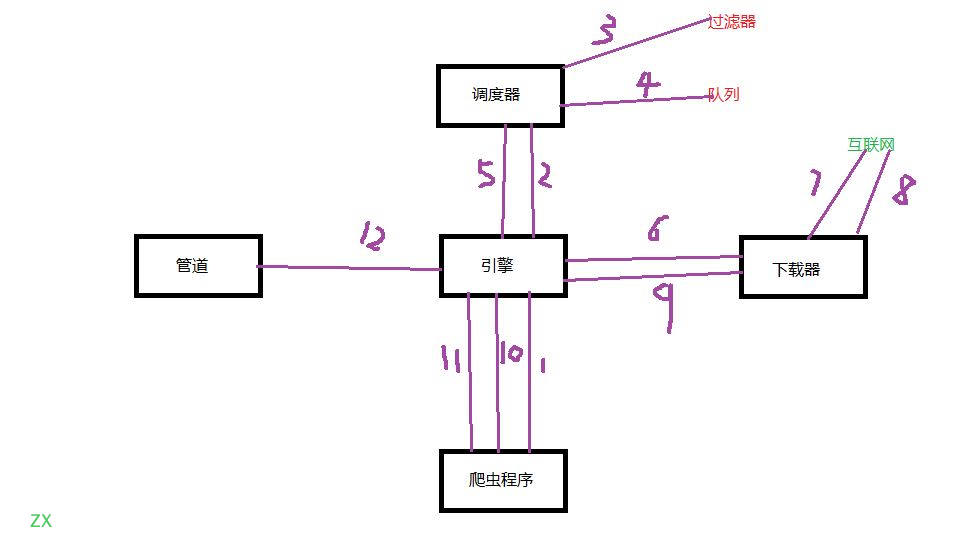
引擎(Scrapy)
(创建对象,根据数据调度方法等)
用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
执行流程
1.爬虫程序将url封装后发送给引擎
2.引擎拿到url后,把它给调度器
3.调度器首先过滤重复的url
4.将过滤好的url压入队列
5.将队列发给引擎
6.引擎将队列发给下载器
7.下载器向互联网请求数据
8.获取数据
9.将数据response发给引擎
10.引擎将数据发给爬虫程序的回调
11.数据处理好,在此发给引擎
12.引擎将数据发给管道,由管道进行数据的持久化存储
scrapy 五大核心组件-分页的更多相关文章
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
- scrapy五大核心组件
scrapy五大核心组件 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- scrapy五大核心组件和中间件以及UA池和代理池
五大核心组件的工作流程 引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- Scrapy五大核心组件简介
五大核心组件 scrapy框架主要由五大组件组成,他们分别是调度器(Scheduler),下载器(Downloader),爬虫(Spider),和实体管道(Item Pipeline),Scrapy引 ...
- 爬虫-scrapy五大核心组件及工作流
- scrapy之五大核心组件
scrapy之五大核心组件 scrapy一共有五大核心组件,分别为引擎.下载器.调度器.spider(爬虫文件).管道. 爬虫文件的作用: a. 解析数据 b. 发请求 调度器: a. 队列 队列是一 ...
- Scrapy 框架 安装 五大核心组件 settings 配置 管道存储
scrapy 框架的使用 博客: https://www.cnblogs.com/bobo-zhang/p/10561617.html 安装: pip install wheel 下载 Twisted ...
- scrapy框架post请求发送,五大核心组件,日志等级,请求传参
一.post请求发送 - 问题:爬虫文件的代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢? - 解答: ...
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
随机推荐
- class定义类 及 实现继承
class 定义类 代码如下: class Student { constructor(name) { this.name = name; } sayHello() { console.log(&qu ...
- idea 2019 1 spring boot 启动报错 An incompatible version [1.2.12] of the APR based Apache Tomcat Native library is installed, while Tomcat requires version [1.2.14]
1.构建一个简单springboot工程,日志打印报错内容如下: 15:38:28.673 [main] DEBUG org.springframework.boot.devtools.setting ...
- 20190906_matplotlib_学习与快速实现
20190906 Matplotlib 学习总结 第一部分: 参考连接: Introduction to Matplotlib and basic line https://www.jianshu.c ...
- CAT客户端如何从Apollo中读取配置?
运行环境 以下就是这个示例的运行环境,如果版本号不一样,区别也应该不会很大,可以根据实际情况做相应调整. JDK 8 spring boot 2.0.7.RELEASE cat-client 3.0. ...
- [Spark]Spark-streaming通过Receiver方式实时消费Kafka流程(Yarn-cluster)
1.启动zookeeper 2.启动kafka服务(broker) [root@master kafka_2.11-0.10.2.1]# ./bin/kafka-server-start.sh con ...
- Matplotlib 设置
# 导入相关模块 import matplotlib.pyplot as plt import numpy as np 设置 figure Matplotlib 绘制的图形都在一个默认的 figure ...
- 爬虫之selenium爬取京东商品信息
import json import time from selenium import webdriver """ 发送请求 1.1生成driver对象 2.1窗口最大 ...
- 深入理解C#第三版部分内容
最近,粗略的读了<深入理解C#(第三版)>这本技术书,书中介绍了C#不同版本之间的不同以及新的功能. 现在将部分摘录的内容贴在下面,以备查阅. C#语言特性: 1.C#2.0 C#2的主 ...
- 使用Typescript重构axios(二十三)——添加withCredentials属性
0. 系列文章 1.使用Typescript重构axios(一)--写在最前面 2.使用Typescript重构axios(二)--项目起手,跑通流程 3.使用Typescript重构axios(三) ...
- Redis集群--Redis集群之哨兵模式
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! 搭建R ...