爬虫---lxml爬取博客文章
上一篇大概写了下lxml的用法,今天我们通过案例来实践,爬取我的博客博客并保存在本地
爬取博客园博客
爬取思路:
1、首先找到需要爬取的博客园地址
2、解析博客园地址
# coding:utf-8
import requests
from lxml import etree
# 博客园地址
url = 'http://www.cnblogs.com/qican/'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
html =requests.get(url,headers=headers).text
# 解析html内容
xml = etree.HTML(html)
3、通过博客名称抓取博客标题和详情链接。
经过分析数据我们需要a标签下的文字和href内容
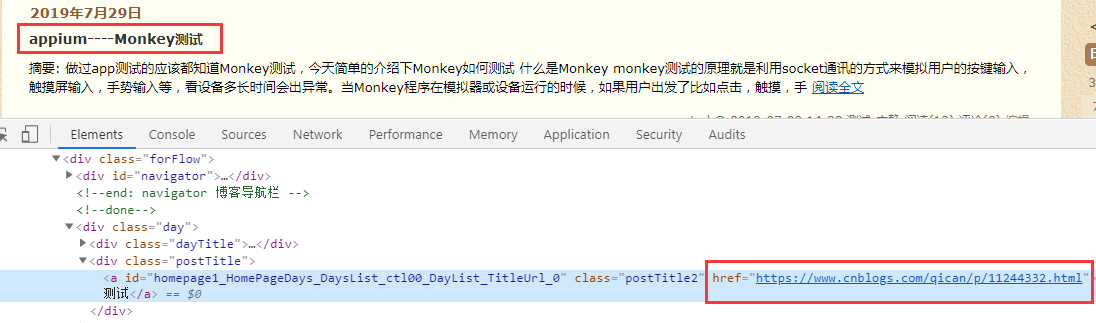
# 标题
title_list = xml.xpath('//div[@class="postTitle"]/a/text()')
# 链接url
url_list = xml.xpath('//div[@class="postTitle"]/a/@href')
4、再次请求博客详情链接获取博客内容
通过for循环获取到标题,链接内容,然后再次请求博客链接获取博客内容
for i,j in zip(title_list,url_list):
# 再次请求博客链接
r2 = requests.get(j,headers=headers).text
# 解析内容
xml_content = etree.HTML(r2)
# 获取博客内容
content = xml_content.xpath('//div[@class="postBody"]//text()')
5、获取的博客内容写入到txt文件中。
通过with写入txt文件中,这里注意内容的编码格式
for x in content:
print(x.strip())
with open(i+'.txt','a+',encoding='utf-8')as f:
f.write(x)
写到这里发现我们都已经把博客内容写入了txt文件中,当然了这只是其中第一页的内容,我们通过观察url链接,发现分页是有page控制的,我们来模拟page数据获取全部博客内容
代码如下:
通过for循环获取模拟分页
# coding:utf-8
import requests
from lxml import etree
# 通过循环模拟url分页
for page in range(1,4):
# 博客园地址
url = 'https://www.cnblogs.com/qican/default.html?page=%s'%page
print(url)
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
html =requests.get(url,headers=headers).text
# 解析html内容
xml = etree.HTML(html)
# 标题
title_list = xml.xpath('//div[@class="postTitle"]/a/text()')
# 链接url
url_list = xml.xpath('//div[@class="postTitle"]/a/@href')
for i,j in zip(title_list,url_list):
print(i)
# 再次请求博客链接
r2 = requests.get(j,headers=headers).text
# 解析内容
xml_content = etree.HTML(r2)
# 获取博客内容
content = xml_content.xpath('//div[@class="postBody"]//text()')
# 写入内容
for x in content:
print(x.strip())
with open(i+'.txt','a+',encoding='utf-8')as f:
f.write(x)
简单的通过案例又一次加深了lxml的用法,当然方法很多种,喜欢哪种用哪种。~~~
爬虫---lxml爬取博客文章的更多相关文章
- python 小爬虫爬取博客文章初体验
最近学习 python 走火入魔,趁着热情继续初级体验一下下爬虫,以前用 java也写过,这里还是最初级的爬取html,都没有用html解析器,正则等...而且一直在循环效率肯定### 很低下 imp ...
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- Python爬虫简单实现CSDN博客文章标题列表
Python爬虫简单实现CSDN博客文章标题列表 操作步骤: 分析接口,怎么获取数据? 模拟接口,尝试提取数据 封装接口函数,实现函数调用. 1.分析接口 打开Chrome浏览器,开启开发者工具(F1 ...
- [js高手之路]Node.js实现简易的爬虫-抓取博客文章列表信息
抓取目标:就是我自己的博客:http://www.cnblogs.com/ghostwu/ 需要实现的功能: 抓取文章标题,超链接,文章摘要,发布时间 需要用到的库: node.js自带的http库 ...
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
前面一直强调Python运用到网络爬虫方面很有效,这篇文章也是结合学习的Python视频知识及我研究生数据挖掘方向的知识.从而简介下Python是怎样爬去网络数据的,文章知识很easy ...
- Java使用Jsoup之爬取博客数据应用实例
导入Maven依赖 <!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --> <dependency> <g ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- 使用JAVA爬取博客里面的所有文章
主要思路: 1.找到列表页. 2.找到文章页. 3.用一个队列来保存将要爬取的网页,爬取队头的url,如果队列非空,则一直爬取. 4.如果是列表页,则抽取里面所有的文章url进队:如果是文章页,则直接 ...
- python3 爬虫之爬取安居客二手房资讯(第一版)
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author;Tsukasa import requests from bs4 import Beau ...
随机推荐
- android笔记--Intent和IntentFilter详解
本文转载自:https://www.cnblogs.com/liushengjie/archive/2012/08/30/2663066.html 本文转载自:https://www.cnblogs. ...
- 团队项目之Scrum1
小组:BLACK PANDA 时间:2019.11.16 部分 得分项 分数 完成内容 第 1 篇 Scrum 冲刺博客 各个成员在 Alpha 阶段认领的任务 3 明日各个成员的任务安排 3 用户登 ...
- ORA-12505
tomcat 连不上 oracle,报: java.sql.SQLException: Listener refused the connection with the following error ...
- acwing 47. 二叉树中和为某一值的路径
地址 https://www.acwing.com/problem/content/description/45/ 输入一棵二叉树和一个整数,打印出二叉树中结点值的和为输入整数的所有路径. 从树的根结 ...
- LeetCode 5129. 下降路径最小和 II Minimum Falling Path Sum II
地址 https://leetcode-cn.com/contest/biweekly-contest-15/problems/minimum-falling-path-sum-ii/ 题目描述给你一 ...
- CF1253F Cheap Robot(神奇思路,图论,最短路,最小生成树/Kruskal 重构树/并查集)
神仙题. 先考虑平方级别的暴力怎么做. 明显答案有单调性,先二分 \(c\). 先最短路预处理 \(dis_u\) 表示 \(u\) 到离它最近的充电站的距离(一开始把 \(1\) 到 \(k\) 全 ...
- 《细说PHP》 第四版 样章 第二章 PHP的应用与发展 4
2.4 PHP的发展 最初创建时,PHP是一个简单的用Perl语言编写的程序,只是为了统计自己的网站有多少访问者.后来又用C语言重新编写,多年来,PHP经过无数开源贡献者的不断迭代,历经数个版本,已 ...
- 【Linux命令】centos防火墙使用和配置
目录 firewalld iptables Linux中的防火墙(iptables,firewalld,ip6tables,ebtables).这些软件本身并不具备防火墙功能,他们的作用都是在用户空间 ...
- jQuery 源码分析(十一) 队列模块 Queue详解
队列是常用的数据结构之一,只允许在表的前端(队头)进行删除操作(出队),在表的后端(队尾)进行插入操作(入队).特点是先进先出,最先插入的元素最先被删除. 在jQuery内部,队列模块为动画模块提供基 ...
- RabbitMQ的消息确认ACK机制
1.什么是消息确认ACK. 答:如果在处理消息的过程中,消费者的服务器在处理消息的时候出现异常,那么可能这条正在处理的消息就没有完成消息消费,数据就会丢失.为了确保数据不会丢失,RabbitMQ支持消 ...