Java使用Jsoup之爬取博客数据应用实例
导入Maven依赖
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.</version>
</dependency>
选择你要爬取网站(这里我以爬取自己的博客文章为例)
通过浏览器进入这个网址
如我的博客
使用浏览器调试工具(后面会说到这个目的)
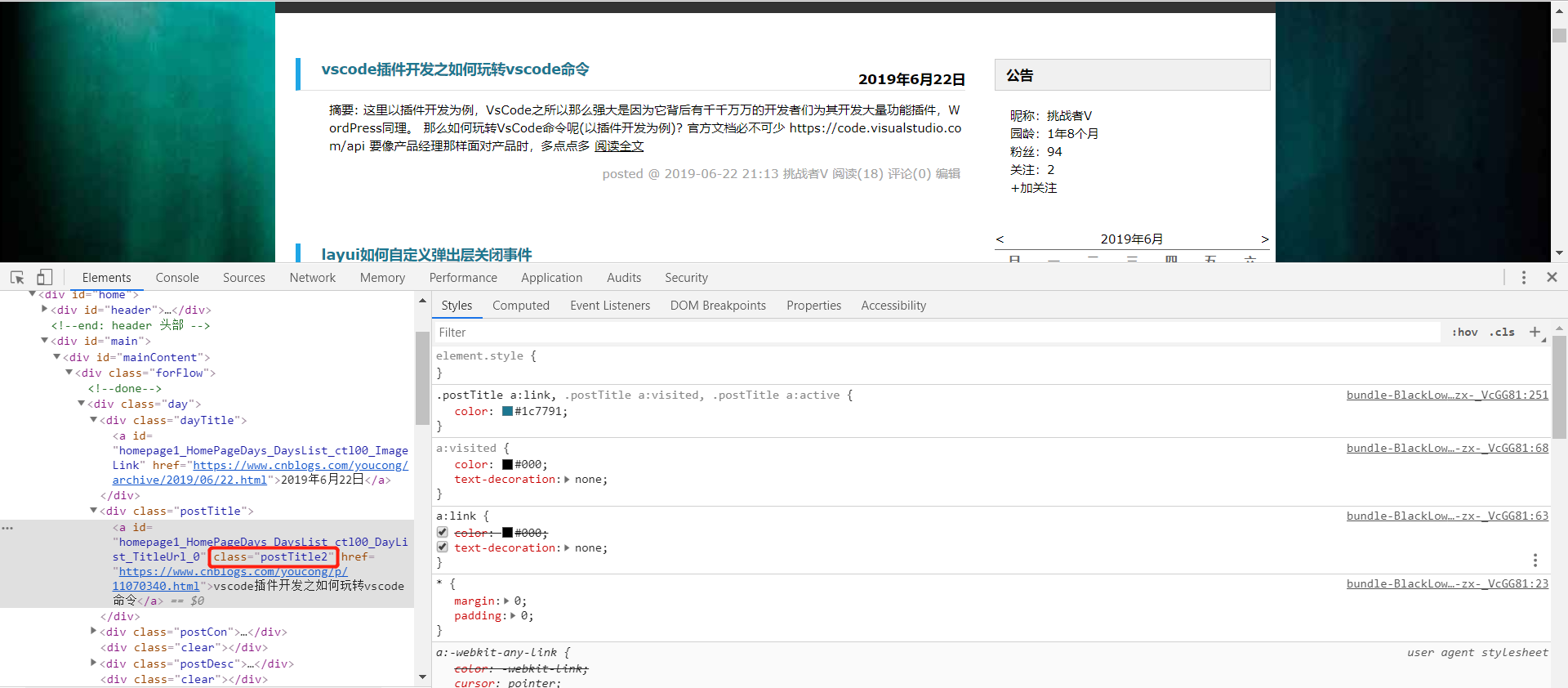
编写对应的Java的代码
package cn.test;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* A simple example, used on the jsoup website.
*/
public class BlogJsoup {
/**
* 获取博客最近十篇文章
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
Connection connection = Jsoup.connect("https://www.cnblogs.com/youcong/");
connection.header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36");
try {
Document document = connection.timeout(100000).get();
//包含所有列表的文章
Elements elements = document.getElementsByClass("postTitle2");
for (Element element : elements) {
String path = element.attr("href");
String text = element.text();
String msg = text+" "+path;
System.out.println(msg);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
上面的代码,用流程可以梳理为如下:
连接爬取的网站->设置浏览器请求头(防止因浏览器的限制导致爬取数据失败)->获取整个HTML(实际就是一个html)->选择HTML中的某一个元素(如类选择器postTitle2,如果不指定对应的元素选择器,那么直接爬取的就是整个HTML)->爬取数据并输出
输出结果如图:

Java使用Jsoup之爬取博客数据应用实例的更多相关文章
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- 爬虫---lxml爬取博客文章
上一篇大概写了下lxml的用法,今天我们通过案例来实践,爬取我的博客博客并保存在本地 爬取博客园博客 爬取思路: 1.首先找到需要爬取的博客园地址 2.解析博客园地址 # coding:utf-8 i ...
- 使用JAVA爬取博客里面的所有文章
主要思路: 1.找到列表页. 2.找到文章页. 3.用一个队列来保存将要爬取的网页,爬取队头的url,如果队列非空,则一直爬取. 4.如果是列表页,则抽取里面所有的文章url进队:如果是文章页,则直接 ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- python 小爬虫爬取博客文章初体验
最近学习 python 走火入魔,趁着热情继续初级体验一下下爬虫,以前用 java也写过,这里还是最初级的爬取html,都没有用html解析器,正则等...而且一直在循环效率肯定### 很低下 imp ...
- (java)Jsoup爬虫学习--获取智联招聘(老网站)的全国java职位信息,爬取10页
Jsoup爬虫学习--获取智联招聘(老网站)的全国java职位信息,爬取10页,输出 职位名称*****公司名称*****职位月薪*****工作地点*****发布日期 import java.io.I ...
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- 【Android 我的博客APP】1.抓取博客首页文章列表内容——网页数据抓取
打算做个自己在博客园的博客APP,首先要能访问首页获取数据获取首页的文章列表,第一步抓取博客首页文章列表内容的功能已实现,在小米2S上的效果图如下: 思路是:通过编写的工具类访问网页,获取页面源代码, ...
- [js高手之路]Node.js实现简易的爬虫-抓取博客文章列表信息
抓取目标:就是我自己的博客:http://www.cnblogs.com/ghostwu/ 需要实现的功能: 抓取文章标题,超链接,文章摘要,发布时间 需要用到的库: node.js自带的http库 ...
随机推荐
- Java集合框架 面试问题整理
简介 java集合类是java.util 包中的重要内容.java集合框架包含了大量集合接口以及这些接口的实现类和操作他们的算法. java集合框架图 主要提供的数据结构 List 又称有序的Coll ...
- CentOS 6 使用 tptables 打开关闭防火墙与端口
开启访问端口 Linux版本:CentOS release 6.9 此处以nginx访问端口8081为例 编辑:vi /etc/sysconfig/iptables 添加:-A RH-Firewall ...
- webdriver切换frame的方法
iframe: iframe 就是一个特殊的html 元素, 它在原来的html 范围内,开辟了一个新的HTML. iframe 元素会创建包含另外一个文档的内联框架(即行内框架) 理解:网页嵌套网页 ...
- docker管理监控方案
docker相关管理可分为四类:docker基础功能.docker监控.docker集群管理和docker系统认证管理.docker管理的基础或信息来源都是docker命令行或docker API. ...
- 原生ajax解析&封装原生ajax函数
前沿:对于此篇随笔,完是简要写了几个重要的地方,具体实现细节完在提供的源码做了笔记 <一>ajax基本要点介绍--更好的介绍ajax 1. ajax对象中new XMLHttpReques ...
- vim中自动补全插件snipmate使用
vim中自动补全插件snipmate使用 1.下载snipMatezip:https://github.com/msanders/snipmate.vim/archive/master.zip 2.解 ...
- python爬虫中的ip代理设置
设置ip代理是爬虫必不可少的技巧: 查看本机ip地址:打开百度,输入“ip地址”,可以看到本机的IP地址: 本文使用的是goubanjia.com里面的免费ip: 使用时注意要注意传输协议是http还 ...
- Kotlin调用Java程序解析
Kotlin跟Java是百分百兼容的,换言之,也就是它们俩是可以互操作的,也就是Java可以调Kotlin,Koltin可以调Java,所以下面来看一下在Kotlin中如何来调用Java代码: 咱们来 ...
- C# 退出应用程序的几种方法
Application.Exit();//好像只在主线程可以起作用,而且当有线程,或是阻塞方法的情况下,很容易失灵 this.Close();//只是关闭当前窗体. Application.ExitT ...
- 将照片转成base64时候,使用下面的这个包更加安全一些
import org.apache.commons.net.util.Base64; 在项目中将照片转成base64时候,使用下面的这个包更加安全一些