快速理解spark-on-k8s中的external-shuffle-service
【摘要】 external-shuffle-service是Spark里面一个重要的特性,有了它后,executor可以在不同的stage阶段动态改变数量,大大提升集群资源利用率。但是这个特性当前在k8s上并不能很好的运行。让我们来看看,在k8s上要实现这个external-shuffle-service特性的最新进展吧。

如果你想在kubernetes集群中运行Spark任务,那么你可能会对:如何在k8s上运行external-shuffle-service感兴趣。把Driver和Executor都当做容器,丢到k8s上(k8s集群则把他们当做一般的容器,和其他业务类app一样对待),这种模式,可以使得集群资源池归一,避免Spark一个资源池,业务类(K8S)集群一个资源池。提升整体资源利用率,统一维护也降低运维成本。这也是Spark官方在2.3版本后为什么要支持Spark-on-k8s的主要驱动力。
1 external-shuffle-service作用
如果想要executor数量可以动态变化,就需要依赖external-shuffle-service功能(注意这句话,因为在k8s集群中,容器启动关闭很方便。所以非常希望executor数量可以动态调整,提升资源利用率)。
原因是在shuffle过程中,一个executor会到另一个executor那里取数据。如果一个executor节点挂掉了,那么它也就无法处理其他executor发过来的 shuffle 的数据读取请求了,它之前生成的数据都没有意义了。为了解决“取shuffle数据”,和“目标executor是否运行”分开。Spark引入了external-shuffle-service服务。相当于先把shuffle数据暂存到external-shuffle-service那里,然后大家去external-shuffle-service那里取就行了(有点像个中介)。
好文参考:https://zhmin.github.io/2019/08/05/spark-external-shuffle-service/
2 原来怎么部署
在原Spark框架中,external-shuffle-service是部署在每个节点上的。
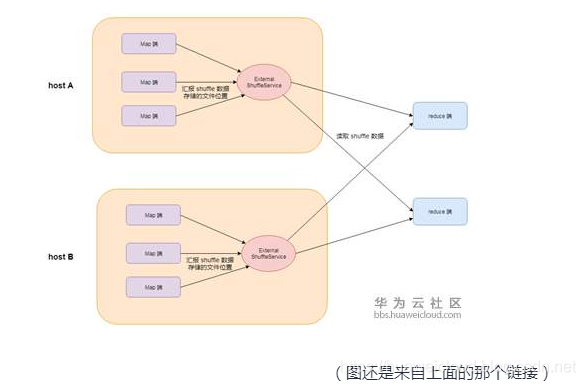
(1)executor 告诉 external-shuffle-service 数据存放在哪里,然后(2) external-shuffle-service 记下来,供别人查询。所以问题的关键是,数据放“哪里”支持哪些格式呢。我们看(1)里面通知是结构是长这样:
public class RegisterExecutor extends BlockTransferMessage {
public final String appId; // spark application id
public final String execId; // executor id
public final ExecutorShuffleInfo executorInfo; // 《==文件路径
}可以看出来,关键在 “在哪里” 要看(2)长什么样:
public class ExecutorShuffleInfo implements Encodable {
public final String[] localDirs; // 《== 第一级目录列表
public final int subDirsPerLocalDir; // 第二级目录列表
public final String shuffleManager; // shuffleManager的类型,目前只有一种类型 SortShuffleManager
}可以看到,这个shuffle数据 “在哪里” 只能支持HostPath(本地路径)。
问题的关键就来了:executor容器跑在k8s节点上面,external-shuffle-service跑在另一个容器里面。要想共享相同Path文件,那就必须使用节点路径(k8s-hostpath)。要用这个Hostpath 还得拥有节点的所有权,这个对于多用户共享的K8s集群来说,权限不安全,数据未隔离。
3 在k8s上要怎么解决(一)
Spark的external-shuffle-service要怎么在k8s上运行,这是个问题。Spark社区关于这个有个讨论:https://docs.google.com/document/d/1uCkzGGVG17oGC6BJ75TpzLAZNorvrAU3FRd2X-rVHSM/edit#heading=h.btqugnmt2h40
这个文档主要是说:
当前external-shuffle-service的实现有缺点:(1)多个Spark应用共用一个external-shuffle-service,如果external-shuffle-service出问题,多个Spark应用都受影响,即隔离性差。(2)一个节点一个external-shuffle-service,导致不同节点间压力不均衡。同时如果节点挂了,external-shuffle-service也就没了,这个节点上面的所有executor都受影响,可靠性差。(3)在当前较火热的Docker容器环境下,executor写入的shuffle数据(在一个容器内)。不一定就能被external-shuffle-service读取到(在另一个容器内)。因为有些k8s集群中,管理员出于安全考虑,会强制隔离不同用户的容器,禁止任何共享。
所以提出了改进方向:即executor保存shuffle数据时,不限定非得是保存在本地Path中。
具体实现方案可以有多种。
(1) 保存shuffle数据时,通过external-shuffle-service上传的方式。
(2) external-shuffle-service支持shuffle数据为远端uri地址,而不仅仅是主机路径。
(3) 由Driver来维护所有的shuffle数据信息,取消external-shuffle-service组件。
(4) 将shuffle数据保存到分布式存储中。
(5) 将shuffle数据上传到external-shuffle-service,然后由Driver跟踪文件路径。
总体思路就是:以前external-shuffle-service是本地写,远程读。调整为:远程写,远程读。
4 在k8s上要怎么解决(二)
其实要在k8s上实现executor数量动态调整(dynamic resource allocation),还有另一条小路(即不通过external-shuffle-service的方式)。并且这条路已经实现了,在这个PR里面。https://github.com/apache/spark/pull/24817
Ø 实现原理:
当发现executor里面是shuffle数据没有用了,则可以删除该executor。如果这个executor里面的shuffle数据,还会被其他Jop读取,那么就保持这个executor存活着不被删除。从而实现executor数量可以动态调整。
Ø 缺点:
可以看出来,这种方式其实是一种缓兵之计。(1)删除部分暂时不被使用executor,但是必须保留那些还会被使用的executor。所以动态效果并不是最优的。另外,(2)一个executor也许最近不被使用,被删除了。但是后续其他Stage又有可能去访问那个shuffle数据。结果发现找不到(被动态删除嘛),这个时候又得重新计算,浪费性能。
PR里面的讨论也说了,这个是无法用来完整替代external-shuffle-service的。
5 路标计划
通过上面的分析,基本了解了在k8s上面跑external-shuffle-service的困难和思路。
所以要达到目的的路径为:(1)external-shuffle-service支持远端保存shuffle数据。(2)executor和external-shuffle-service共享云端shuffle数据。(3)executor数量可以动态调整,不影响功能。(4)在k8s上支持了executor数量动态调整(dynamic resource allocation)。
看Spark的规划是在 3.0.0 版本提供完整能力,嗯,让我们期待Spark on K8s越来越溜吧。
https://issues.apache.org/jira/browse/SPARK-24432
作者:tsjsdbd
快速理解spark-on-k8s中的external-shuffle-service的更多相关文章
- 降本增效利器!趣头条Spark Remote Shuffle Service最佳实践
王振华,趣头条大数据总监,趣头条大数据负责人 曹佳清,趣头条大数据离线团队高级研发工程师,曾就职于饿了么大数据INF团队负责存储层和计算层组件研发,目前负责趣头条大数据计算层组件Spark的建设 范振 ...
- Spark机器学习 Day2 快速理解机器学习
Spark机器学习 Day2 快速理解机器学习 有两个问题: 机器学习到底是什么. 大数据机器学习到底是什么. 机器学习到底是什么 人正常思维的过程是根据历史经验得出一定的规律,然后在当前情况下根据这 ...
- 理解Spark RDD中的aggregate函数(转)
针对Spark的RDD,API中有一个aggregate函数,本人理解起来费了很大劲,明白之后,mark一下,供以后参考. 首先,Spark文档中aggregate函数定义如下 def aggrega ...
- 快速理解Python中使用百分号占位符的字符串格式化方法中%s和%r的输出内容的区别
<Python中使用百分号占位符的字符串格式化方法中%s和%r的输出内容有何不同?>老猿介绍了二者的区别,为了快速理解,老猿在此使用另外一种方式补充说明一下: 1.使用%r是调用objec ...
- 在 K8S 中快速部署 Redis Cluster & Redisinsight
Redis Cluster 部署 使用 Bitnami helm chart 在 K8S redis 命名空间中一键部署 Redis cluster . helm repo add bitnami h ...
- k8s中几个基本概念的理解,pod,service,deployment,ingress的使用场景
k8s 总体概览 前言 Pod 副本控制器(Replication Controller,RC) 副本集(Replica Set,RS) 部署(Deployment) 服务(Service) ingr ...
- 深入理解k8s中的访问控制(认证、鉴权、审计)流程
Kubernetes自身并没有用户管理能力,无法像操作Pod一样,通过API的方式创建/删除一个用户实例,也无法在etcd中找到用户对应的存储对象. 在Kubernetes的访问控制流程中,用户模型是 ...
- 《深入理解Spark:核心思想与源码分析》(前言及第1章)
自己牺牲了7个月的周末和下班空闲时间,通过研究Spark源码和原理,总结整理的<深入理解Spark:核心思想与源码分析>一书现在已经正式出版上市,目前亚马逊.京东.当当.天猫等网站均有销售 ...
- 《深入理解Spark:核心思想与源码分析》(第2章)
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
随机推荐
- Vue组件间通信方式到底有几种
1. 前言 Vue的一个核心思想就是组件化.所谓组件化,就是把页面拆分成多个组件 (component),每个组件依赖的 CSS.JavaScript.模板.图片等资源放在一起开发和维护.组件是资源独 ...
- 原生JS实现双向链表
1.前言 双向链表和单向链表的区别在于,在链表中,一个节点只有链向下一个节点的链接,而在双向链表中,链接是双向的:一个链向下一个元素,另一个链向前一个元素,如下图所示: 从图中可以看到,双向链表中,在 ...
- jQuery源码分析--为什么在参数列表中传入undefined
(function(window, undefined){ //jQuery code; })(window); 为什么要传入undefined? 1.没有传入undefined: <!DOCT ...
- html5 微信真机调试方法vConsole
html5 微信真机调试方法 vConsolehttps://blog.csdn.net/weixin_36934930/article/details/79870240
- php ffmpeg截取视频第一帧保存为图片的方法
php ffmpeg截取视频第一帧保存为图片的方法 <pre> $xiangmupath = $this->getxiangmupath(); $filename = 'chengs ...
- Eclipse下载安装并运行第一个Hello world(详细)
Eclipse下载安装并运行第一个Hello world(详细) 1.下载安装和配置JDK JDK详细的安装教程参考:https://www.cnblogs.com/mxxbc/p/11845150. ...
- 7月22 Linux作业-文件管理
习题内容 解答 1.答案 [root@centos7 ~]# echo '*/1 * * * * /usr/bin/cp /etc /data/`/usr/bin/date +\%Y-\%m-\%d` ...
- C++中对C的扩展学习新增内容———面向对象(继承)函数扩展性及虚函数机制
1.c语言中的多态,动态绑定和静态绑定 void do_speak(void(*speak)()) { speak(); } void pig_speak() { cout << &quo ...
- 力扣(LeetCode)计数质数 个人题解
统计所有小于非负整数 n 的质数的数量. 示例: 输入: 10 输出: 4 解释: 小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 . 一般方法,也就是一般人都会用的,将数从2到它本 ...
- 痞子衡嵌入式:飞思卡尔Kinetis系列MCU启动那些事(10)- KBOOT特性(可靠升级)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是飞思卡尔Kinetis系列MCU的KBOOT之可靠升级(Reliable Update)特性. 所谓可靠升级机制,即在更新Applica ...