数据分析入门——pandas之Series
一、介绍
Pandas是一个开源的,BSD许可的库(基于numpy),为Python编程语言提供高性能,易于使用的数据结构和数据分析工具。
官方中文文档:https://www.pypandas.cn/docs/
本次演示使用数据来自github:https://github.com/jakevdp/PythonDataScienceHandbook/tree/master/notebooks/data
二、快速入门
1.导入

2.重点数据结构
主要是series和dataframe
所以一般情况下我们导入的是数据分析的三剑客:
numpy Series DataFrame:(如果只导入pd,那就正常使用pd.Series即可了)
from pandas import Series,DataFrame
三、Series
Series是Pandas中的一维数据结构,类似于Python中的列表和Numpy中的Ndarray,不同之处在于:Series是一维的,能存储不同类型的数据,有一组索引与元素对应。也就是加了索引的一维数据结构(索引不一定是0 1 2 3的数字)

1.创建
1)通过列表或者numpy数组进行创建,默认索引是0 1 2 3这样的整数索引。示例如上图
想要指定索引,可以设置index参数:(创建的时候指定也是可以的)
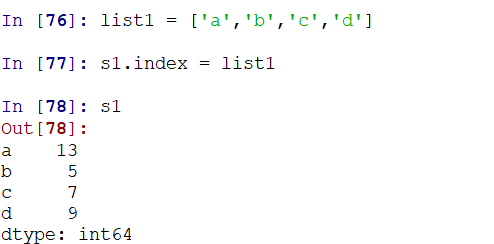
特别地,使用ndarray创建的series是引用,对series的改变会影响ndarray
2)由字典创建
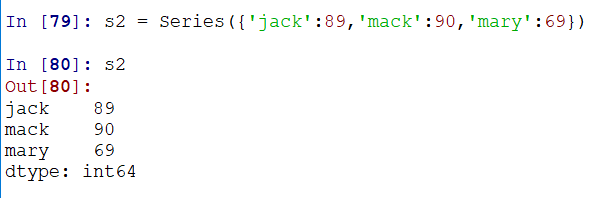
Series主要分为index、values两块
2.索引和切片
1).使用index作为索引值(不推荐)

2)使用升级为Series之后的loc()函数(推荐)
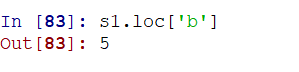
3)使用隐式索引(不显式指定索引的内容值,通过类似ndarray的索引风格取数据)

4)切片,可以直接[]或者loc形式

3.Series基本概念
1)常用属性:index、values、shape(一维的,所以只能是一个元素的元组)、size
2)可以通过head()、tail()等查看头部和尾部数据(类似linux的命令),只看前5个或者后5个
3)索引没有对应的值时,值会出现NaN,也就是数据缺失的情况,在np中使用np.nan表示这个空值,python中就是None表示了
4)可以使用 isnull()、notnull()来检测空值:
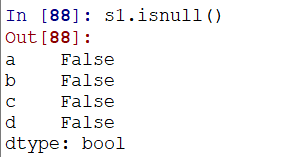
可以通过notnull()等进行空数据过滤:
s2 = s.notnull()
# 以下取出的便是为True的非空数据
s[s2]
5)每个Series都有一个name属性,可以在DataFrame中进行区分,在df中,也就相当于列名
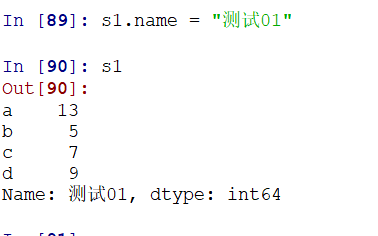
6)Series运算
可以正常的进行加减运算,其中None值不会参与计算,而ndarray值为None时为报错,为np.nan时计算结果为nan


或者通过s1.add(10,fill_value= 0)等形式来控制NaN的默认值
两个Series之间也可以运算,不对齐的部分(也就是索引不相等的部分),补充NaN

要保留index不对齐的部分,可以使用add()方法:,通过fill_value

数据分析入门——pandas之Series的更多相关文章
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 数据分析入门——Pandas类库基础知识
使用python进行数据分析时,经常会用Pandas类库处理数据,将数据转换成我们需要的格式.Pandas中的有两个数据结构和处理数据相关,分别是Series和DataFrame. Series Se ...
- 数据分析入门——pandas之DataFrame基本概念
一.介绍 数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列. 可以看作是Series的二维拓展,但是df有行列索引:index.column 推荐参考:https://www. ...
- 数据分析入门——pandas数据处理
1,处理重复数据 使用duplicated检测重复的行,返回一个series,如果不是第一次出现,也就是有重复行的时候,则为True: 对应的,可以使用drop_duplicates来删除重复的行: ...
- 数据分析入门——pandas之DataFrame多层/多级索引与聚合操作
一.行多层索引 1.隐式创建 在构造函数中给index.colunms等多个数组实现(datafarme与series都可以) df的多级索引创建方法类似: 2.显式创建pd.MultiIndex 其 ...
- 数据分析入门——pandas之DataFrame数据丢失
一.数据丢失分类 1)nd中分为两种:None和np.nan(NaN) 其中,None是python中的对象,是一个object:而nan是一个float类型 两种不同的类型,运算速度也是不同的 2) ...
- 数据分析之pandas库--series对象
1.Series属性及方法 Series是Pandas中最基本的对象,Series类似一种一维数组. 1.生成对象.创建索引并赋值. s1=pd.Series() 2.查看索引和值. s1=Serie ...
- 数据分析入门——pandas之数据合并
主要分为:级联:pd.concat.pd.append 合并:pd.merge 一.numpy级联的回顾 详细参考numpy章节 https://www.cnblogs.com/jiangbei/p/ ...
随机推荐
- DELL 管理软件安装
dell不进入bios修改cpu为高性能的方法:(在下次重启后生效) 首先安装omsa:安装方法: http://linux.dell.com/repo/hardware/Linux_Reposito ...
- python 类 双下划线解析
__getattr__用法:说明:这是python里的一个内建函数,当调用的属性或者方法不存在时,该方法会被调用调用不存在的属性调用不存在的方法
- 项目兼容ie8技术要点
好久没有写博客了,因为最近公司项目要调ie8兼容,一直在忙这事,终于竣工了,跟大家分享下这老掉牙的浏览器是如何搞定的...本人新手一枚,欢迎大家指教 项目是使用的jeecg框架,后台使用的java,前 ...
- 安装node.js 和 npm 的完整步骤
vue 生命周期 1,beforeCreate 组件刚刚被创建 2,created 组件创建完成 3,beforeMount 挂载之前 4,mounted 挂载之后 5,beforeDestory 组 ...
- Kubernetes 学习26 基于kubernetes的Paas概述
一.概述 1.通过以往的学习应该可以了解到k8s 和以往提到的devops概念更容易落地了.比如我们说的CI,CD,CD a.CI(Continuous Integration):持续集成 b.CD( ...
- Kubernetes 学习4 kubernetes应用快速入门
一.相关命令 1.kubectl 通过连接api server 进行各k8s对象资源的增删改查,如pod,service,controller(控制器),我们常用的pod控制器replicaset,d ...
- RookeyFrame 通用页面 加载数据 原理
说明: 我是一步一步跳转进去的哈 测试的功能:通用列表页面的普通查询 点一下查询按钮,就能看到请求的地址:/DataAsync/LoadGridData.html 1.DataController - ...
- npm 安装全局包 不是内部或外部命令的问题
场景: npm已经安装成功 ,通过npm install -g 安装的 全局包 提示不是内部或外部命令 第一步: npm list -g --depth=0:查看npm全局包的路径,和有哪些安装包 ...
- C语言利用fgetc复制拷贝文件内容
#include <stdio.h> #include <stdlib.h> //文件的内容复制 int main(int a,char *argv[]){ if(a!=3){ ...
- flutter 从接口获取json数据显示到页面
如题,在前端,是个很简单的ajax请求,json的显示,取值都很方便,换用dart之后,除了层层嵌套写的有点略难受之外,还有对json的使用比js要麻烦 1. 可以参照 flutter-go 先封装一 ...