Spark day06
- SparkStreaming简介
SparkStreaming是流式处理框架,是Spark API的扩展,支持可扩展、高吞吐量、容错的实时数据流处理,实时数据的来源可以是:Kafka, Flume, Twitter, ZeroMQ或者TCP sockets,并且可以使用高级功能的复杂算子来处理流数据。例如:map,reduce,join,window 。最终,处理后的数据可以存放在文件系统,数据库等,方便实时展现。
- SparkStreaming与Storm的区别
- Storm是纯实时的流式处理框架,SparkStreaming是准实时的处理框架(微批处理)。因为微批处理,SparkStreaming的吞吐量比Storm要高。
- Storm 的事务机制要比SparkStreaming的要完善。
- Storm支持动态资源调度。(spark1.2开始和之后也支持)
- SparkStreaming擅长复杂的业务处理,Storm不擅长复杂的业务处理,擅长简单的汇总型计算。
- SparkStreaming初始
- SparkStreaming初始理解

注意:
- receiver task是7*24小时一直在执行,一直接受数据,将一段时间内接收来的数据保存到batch中。假设batchInterval为5s,那么会将接收来的数据每隔5秒封装到一个batch中,batch没有分布式计算特性,这一个batch的数据又被封装到一个RDD中,RDD最终封装到一个DStream中。
例如:假设batchInterval为5秒,每隔5秒通过SparkStreamin将得到一个DStream,在第6秒的时候计算这5秒的数据,假设执行任务的时间是3秒,那么第6~9秒一边在接收数据,一边在计算任务,9~10秒只是在接收数据。然后在第11秒的时候重复上面的操作。
- 如果job执行的时间大于batchInterval会有什么样的问题?
如果接受过来的数据设置的级别是仅内存,接收来的数据会越堆积越多,最后可能会导致OOM(如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟 )。
- SparkStreaming代码
代码注意事项:
- 启动socket server 服务器:nc –lk 9999
- receiver模式下接受数据,local的模拟线程必须大于等于2,一个线程用来receiver用来接受数据,另一个线程用来执行job。
- Durations时间设置就是我们能接收的延迟度。这个需要根据集群的资源情况以及任务的执行情况来调节。
- 创建JavaStreamingContext有两种方式(SparkConf,SparkContext)
- 所有的代码逻辑完成后要有一个output operation类算子。
- JavaStreamingContext.start() Streaming框架启动后不能再次添加业务逻辑。
- JavaStreamingContext.stop() 无参的stop方法将SparkContext一同关闭,stop(false),不会关闭SparkContext。
- JavaStreamingContext.stop()停止之后不能再调用start。
|
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("WordCountOnline"); /** * 在创建streaminContext的时候 */ JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
JavaReceiverInputDStream<String> lines = jsc.socketTextStream("node5", 9999);
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { /** * */ private
@Override public Iterable<String> call(String s) { return Arrays.asList(s.split(" ")); } });
JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() { /** * */ private
@Override public Tuple2<String, Integer> call(String s) { return } });
JavaPairDStream<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() { /** * */ private
@Override public Integer call(Integer i1, Integer i2) { return } });
//outputoperator类的算子 counts.print();
jsc.start(); //等待spark程序被终止 jsc.awaitTermination(); jsc.stop(false);
|
- SparkStreaming算子操作
- foreachRDD
- output operation算子,必须对抽取出来的RDD执行action类算子,代码才能执行。
- transform
- transformation类算子
- 可以通过transform算子,对Dstream做RDD到RDD的任意操作。
- updateStateByKey
- transformation算子
- updateStateByKey作用:
- 为SparkStreaming中每一个Key维护一份state状态,state类型可以是任意类型的,可以是一个自定义的对象,更新函数也可以是自定义的。
- 通过更新函数对该key的状态不断更新,对于每个新的batch而言,SparkStreaming会在使用updateStateByKey的时候为已经存在的key进行state的状态更新。
- 使用到updateStateByKey要开启checkpoint机制和功能。
- 多久会将内存中的数据写入到磁盘一份?
如果batchInterval设置的时间小于10秒,那么10秒写入磁盘一份。如果batchInterval设置的时间大于10秒,那么就会batchInterval时间间隔写入磁盘一份。
- 窗口操作
- 窗口操作理解图:

假设每隔5s 1个batch,上图中窗口长度为15s,窗口滑动间隔10s。
- 窗口长度和滑动间隔必须是batchInterval的整数倍。如果不是整数倍会检测报错。
- 优化后的window窗口操作示意图:
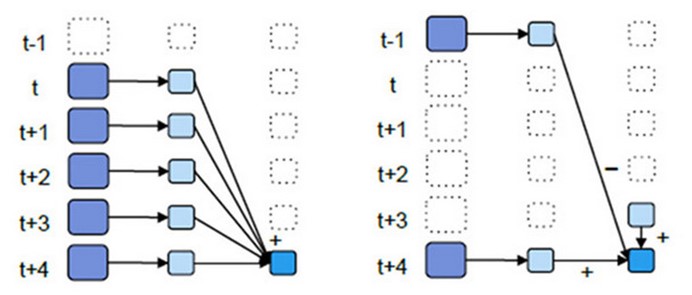
- 优化后的window操作要保存状态所以要设置checkpoint路径,没有优化的window操作可以不设置checkpoint路径。
- Driver HA(Standalone或者Mesos)
因为SparkStreaming是7*24小时运行,Driver只是一个简单的进程,有可能挂掉,所以实现Driver的HA就有必要(如果使用的Client模式就无法实现Driver HA ,这里针对的是cluster模式)。Yarn平台cluster模式提交任务,AM(AplicationMaster)相当于Driver,如果挂掉会自动启动AM。这里所说的DriverHA针对的是Spark standalone和Mesos资源调度的情况下。实现Driver的高可用有两个步骤:
第一:提交任务层面,在提交任务的时候加上选项 --supervise,当Driver挂掉的时候会自动重启Driver。
第二:代码层面,使用JavaStreamingContext.getOrCreate(checkpoint路径,JavaStreamingContextFactory)
- Driver中元数据包括:
- 创建应用程序的配置信息。
- DStream的操作逻辑。
- job中没有完成的批次数据,也就是job的执行进度。
- Kafka
- kafka是什么?使用场景?
kafka是一个高吞吐的分布式消息队列系统。特点是生产者消费者模式,先进先出(FIFO)保证顺序,自己不丢数据,默认每隔7天清理数据。消息列队常见场景:系统之间解耦合、峰值压力缓冲、异步通信。
- kafka生产消息、存储消息、消费消息

Kafka架构是由producer(消息生产者)、consumer(消息消费者)、borker(kafka集群的server,负责处理消息读、写请求,存储消息,在kafka cluster这一层这里,其实里面是有很多个broker)、topic(消息队列/分类相当于队列,里面有生产者和消费者模型)、zookeeper(元数据信息存在zookeeper中,包括:存储消费偏移量,topic话题信息,partition信息) 这些部分组成。
kafka里面的消息是有topic来组织的,简单的我们可以想象为一个队列,一个队列就是一个topic,然后它把每个topic又分为很多个partition,这个是为了做并行的,在每个partition内部消息强有序,相当于有序的队列,其中每个消息都有个序号offset,比如0到12,从前面读往后面写。一个partition对应一个broker,一个broker可以管多个partition,比如说,topic有6个partition,有两个broker,那每个broker就管3个partition。这个partition可以很简单想象为一个文件,当数据发过来的时候它就往这个partition上面append,追加就行,消息不经过内存缓冲,直接写入文件,kafka和很多消息系统不一样,很多消息系统是消费完了我就把它删掉,而kafka是根据时间策略删除,而不是消费完就删除,在kafka里面没有一个消费完这么个概念,只有过期这样一个概念。
producer自己决定往哪个partition里面去写,这里有一些的策略,譬如如果hash,不用多个partition之间去join数据了。consumer自己维护消费到哪个offset,每个consumer都有对应的group,group内是queue消费模型(各个consumer消费不同的partition,因此一个消息在group内只消费一次),group间是publish-subscribe消费模型,各个group各自独立消费,互不影响,因此一个消息在被每个group消费一次。
- kafka的特点
- 系统的特点:生产者消费者模型,FIFO
Partition内部是FIFO的,partition之间呢不是FIFO的,当然我们可以把topic设为一个partition,这样就是严格的FIFO。
- 高性能:单节点支持上千个客户端,百MB/s吞吐,接近网卡的极限
- 持久性:消息直接持久化在普通磁盘上且性能好
直接写到磁盘中去,就是直接append到磁盘里去,这样的好处是直接持久化,数据不会丢失,第二个好处是顺序写,然后消费数据也是顺序的读,所以持久化的同时还能保证顺序,比较好,因为磁盘顺序读比较好。
- 分布式:数据副本冗余、流量负载均衡、可扩展
分布式,数据副本,也就是同一份数据可以到不同的broker上面去,也就是当一份数据,磁盘坏掉的时候,数据不会丢失,比如3个副本,就是在3个机器磁盘都坏掉的情况下数据才会丢,在大量使用情况下看这样是非常好的,负载均衡,可扩展,在线扩展,不需要停服务。
- 很灵活:消息长时间持久化+Client维护消费状态
消费方式非常灵活,第一原因是消息持久化时间跨度比较长,一天或者一星期等,第二消费状态自己维护消费到哪个地方了可以自定义消费偏移量。
- kafka集群搭建
- 上传kafka_2.10-0.8.2.2.tgz包到三个不同节点上,解压。
- 配置../
kafka_2.10-0.8.2.2/config/server.properties文件节点编号:(不同节点按0,1,2,3整数来配置)
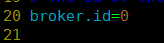
真实数据存储位置:
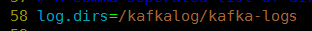
zookeeper的节点:

- 启动zookeeper集群。
- 三个节点上,启动kafka:
|
bin/kafka-server-start.sh config/server.properties |
最好使用自己写的脚本启动,将启动命令写入到一个文件:
|
nohup bin/kafka-server-start.sh config/server.properties > kafka.log 2>&1 &
脚本附件: (放在与bin同一级别下,注意创建后要修改权限:chmod 755 startkafka.sh)
|

- 相关命令:
创建topic:
|
./kafka-topics.sh |
用一台节点控制台来当kafka的生产者:
|
./kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 |
用另一台节点控制台来当kafka的消费者:
|
./kafka-console-consumer.sh |
查看kafka中topic列表:
|
./kafka-topics.sh --list --zookeeper node3:2181,node4:2181,node5:2181 |
查看kafka中topic的描述:
|
./kafka-topics.sh --describe --zookeeper node3:2181,node4:2181,node5:2181 --topic topic2017
注意:ISR是检查数据的完整性有哪些个节点。 |

查看zookeeper中topic相关信息:
|
启动zookeeper客户端: ./zkCli.sh 查看topic相关信息: ls /brokers/topics/ 查看消费者相关信息: ls /consumers |
- 删除kafka中的数据。
- :在kafka集群中删除topic,当前topic被标记成删除。
|
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --delete --topic t1205 |
在每台broker节点上删除当前这个topic对应的真实数据。
- :进入zookeeper客户端,删除topic信息
|
rmr /brokers/topics/t1205 |
- :删除zookeeper中被标记为删除的topic信息
|
rmr /admin/delete_topics/t1205 |
- kafka的leader的均衡机制
当一个broker停止或者crashes时,所有本来将它作为leader的分区将会把leader转移到其他broker上去,极端情况下,会导致同一个leader管理多个分区,导致负载不均衡,同时当这个broker重启时,如果这个broker不再是任何分区的leader,kafka的client也不会从这个broker来读取消息,从而导致资源的浪费。
kafka中有一个被称为优先副本(preferred replicas)的概念。如果一个分区有3个副本,且这3个副本的优先级别分别为0,1,2,根据优先副本的概念,0会作为leader 。当0节点的broker挂掉时,会启动1这个节点broker当做leader。当0节点的broker再次启动后,会自动恢复为此partition的leader。不会导致负载不均衡和资源浪费,这就是leader的均衡机制。
在配置文件conf/ server.properties中配置开启(默认就是开启):
|
auto.leader.rebalance.enable true |
- SparkStreaming+Kafka
- receiver模式
- receiver模式原理图
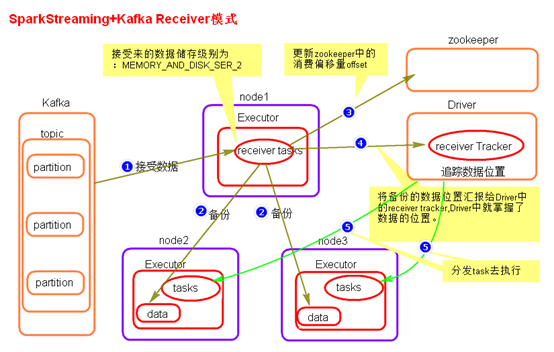
- receiver模式理解:
在SparkStreaming程序运行起来后,Executor中会有receiver tasks接收kafka推送过来的数据。数据会被持久化,默认级别为MEMORY_AND_DISK_SER_2,这个级别也可以修改。receiver task对接收过来的数据进行存储和备份,这个过程会有节点之间的数据传输。备份完成后去zookeeper中更新消费偏移量,然后向Driver中的receiver tracker汇报数据的位置。最后Driver根据数据本地化将task分发到不同节点上执行。
- receiver模式中存在的问题
当Driver进程挂掉后,Driver下的Executor都会被杀掉,当更新完zookeeper消费偏移量的时候,Driver如果挂掉了,就会存在找不到数据的问题,相当于丢失数据。
如何解决这个问题?
开启WAL(write ahead log)预写日志机制,在接受过来数据备份到其他节点的时候,同时备份到HDFS上一份(我们需要将接收来的数据的持久化级别降级到MEMORY_AND_DISK),这样就能保证数据的安全性。不过,因为写HDFS比较消耗性能,要在备份完数据之后才能进行更新zookeeper以及汇报位置等,这样会增加job的执行时间,这样对于任务的执行提高了延迟度。
- receiver模式代码(见代码)
- receiver的并行度设置
receiver的并行度是由spark.streaming.blockInterval来决定的,默认为200ms,假设batchInterval为5s,那么每隔blockInterval就会产生一个block,这里就对应每批次产生RDD的partition,这样5秒产生的这个Dstream中的这个RDD的partition为25个,并行度就是25。如果想提高并行度可以减少blockInterval的数值,但是最好不要低于50ms。
- Driect模式
- Direct模式理解
SparkStreaming+kafka 的Driect模式就是将kafka看成存数据的一方,不是被动接收数据,而是主动去取数据。消费者偏移量也不是用zookeeper来管理,而是SparkStreaming内部对消费者偏移量自动来维护,默认消费偏移量是在内存中,当然如果设置了checkpoint目录,那么消费偏移量也会保存在checkpoint中。当然也可以实现用zookeeper来管理。
- Direct模式并行度设置
Direct模式的并行度是由读取的kafka中topic的partition数决定的。
- Direct模式代码(见代码)
- 相关配置
预写日志:
|
spark.streaming.receiver.writeAheadLog.enable 默认false没有开启 |
blockInterval:
|
spark.streaming.blockInterval 默认200ms |
反压机制:
|
spark.streaming.backpressure.enabled 默认false |
接收数据速率:
|
spark.streaming.receiver.maxRate 默认没有设置 |
Spark day06的更多相关文章
- spark练习--由IP得到所在地
今天我们就来介绍,如何根据一个IP来求出这个IP所在的地址是什么,首先我们如果要做这个内容,那么我们要有一个IP地址的所在地字典,这个我们可以在网上购买,形如: 1.0.1.0|1.0.3.255|1 ...
- spark练习--mysql的读取
前面我们一直操作的是,通过一个文件来读取数据,这个里面不涉及数据相关的只是,今天我们来介绍一下spark操作中存放与读取 1.首先我们先介绍的是把数据存放进入mysql中,今天介绍的这个例子是我们前两 ...
- spark的排序方法
今天我们来介绍spark中排序的操作,spark的排序很简单,我们可以直接使用sortBy来进行,这个里面我们使用case clas,使用case class的好处是1.不用newjiukeyi 搞出 ...
- 大数据学习day23-----spark06--------1. Spark执行流程(知识补充:RDD的依赖关系)2. Repartition和coalesce算子的区别 3.触发多次actions时,速度不一样 4. RDD的深入理解(错误例子,RDD数据是如何获取的)5 购物的相关计算
1. Spark执行流程 知识补充:RDD的依赖关系 RDD的依赖关系分为两类:窄依赖(Narrow Dependency)和宽依赖(Shuffle Dependency) (1)窄依赖 窄依赖指的是 ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
随机推荐
- Web API 接口说明文档
1.采用 Web API Help Page 显示效果 2.swaggerui 创建文档接口 效果图 3.swagger ui 安装配置 nuget 安装 2.设置xml文件 3.配置根路径 预览sw ...
- ArcGIS Data Interoperability 的使用(1)
今天在用OneMap的时候,发现OneMap中注册过后的WFS服务无法在skyline中加载,于是想知道OneMap注册后的WFS服务与server中的原生态WFS服务有啥区别.首先想到是否能在Arc ...
- String、StringBuffer和StringBuilder源码解析
1.String 1.1类的定义 public final class String implements java.io.Serializable, Comparable<String> ...
- Java Iterator模式
Iterator迭代器的定义:迭代器(Iterator)模式,又叫做游标(Cursor)模式.GOF给出的定义为:提供一种方法访问一个容器(container)对象中各个元素,而又不需暴露该对象的内部 ...
- python 中文乱码问
在本文中,以'哈'来解释作示例解释所有的问题,“哈”的各种编码如下: 1. UNICODE (UTF8-16),C854: 2. UTF-8,E59388: 3. GBK,B9FE. 一.python ...
- 2018-2019年中国CDN市场发展报告:阿里云成为中国CDN市场的领军者
近日,权威ICT市场咨询机构计世资讯(CCW Research)发布<2018-2019年中国CDN市场发展报告>,报告显示,当前,随着新型信息技术在中国不断应用,以及互联网化新业务的快速 ...
- xhEditor 简单用法
1.下载需要文件包: http://xheditor.com/ 2.解压文件中文件 xheditor-zh-cn.min.js以及xheditor_emot.xheditor_plugins和xhed ...
- 前端(jQuery)(9)-- jQuery菜单
1.垂直菜单布局 2.垂直菜单实现 <!DOCTYPE html> <html lang="en"> <head> <meta chars ...
- Eclipse配置Maven详细教程
一.使用eclipse自带的maven插件 首先,现在下载Eclipse Mars之后的版本,基本上都自带了maven插件,无需自己再安装maven. 有几个注意点: 1.默认的本地仓库的目录是在C: ...
- GIT → 02:Git和Svn比较
2.1 SVN介绍 2.1.1 SVN简介 SVN 属于集中式版本管理控制系统,服务器中保存了所有文件的不同版本,而协同工作人员通过连接svn服务器,提取出最新的文件,获取提交更新.Subversio ...