python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本。
工具:python3.7+selenium+任意一款编辑器
前期准备:可以正常使用的浏览器,这里推荐chrome,一个与浏览器同版本的驱动,这里提供一个下载驱动的链接https://chromedriver.storage.googleapis.com/77.0.3865.40/chromedriver_win32.zip
首先我们来看一下百度文库中这一篇文章https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html
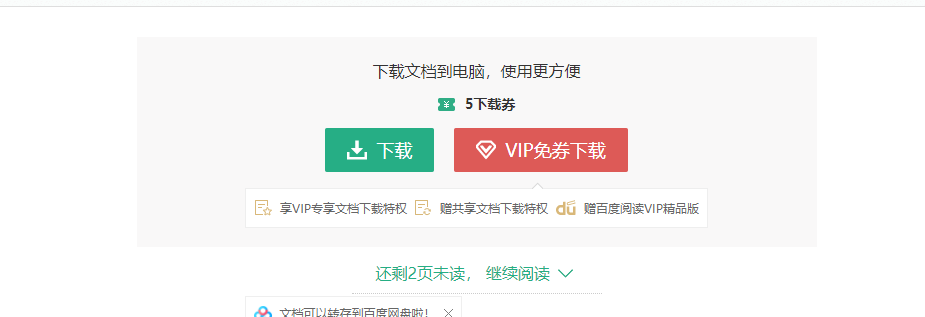
可以看到,在文章的最末尾需要我们来点击继续阅读才能爬取到所有的文字,不然我们只能获取到一部分的文字。这给我们的爬虫带来了一些困扰。因此,我们需要借助selenium这一个自动化工具来帮助我们的程序完成这一操作。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from bs4 import BeautifulSoup
import re
driver = webdriver.Chrome('D:/chromedriver.exe')
driver.get("https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html")
我们先通过驱动器来请求这个页面,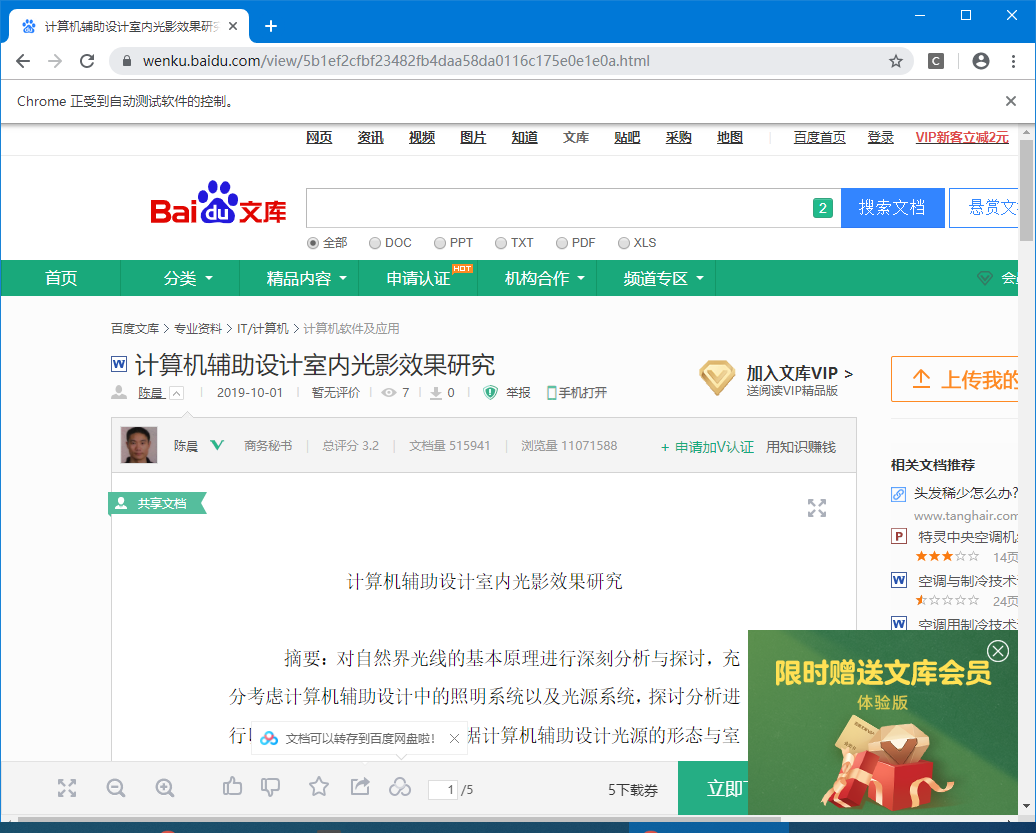
可以看到,已经请求成功这个页面了。接下来需要我们通过驱动来点击继续阅读来加载到这篇文章的所有文字。我们通过f12审查元素,看看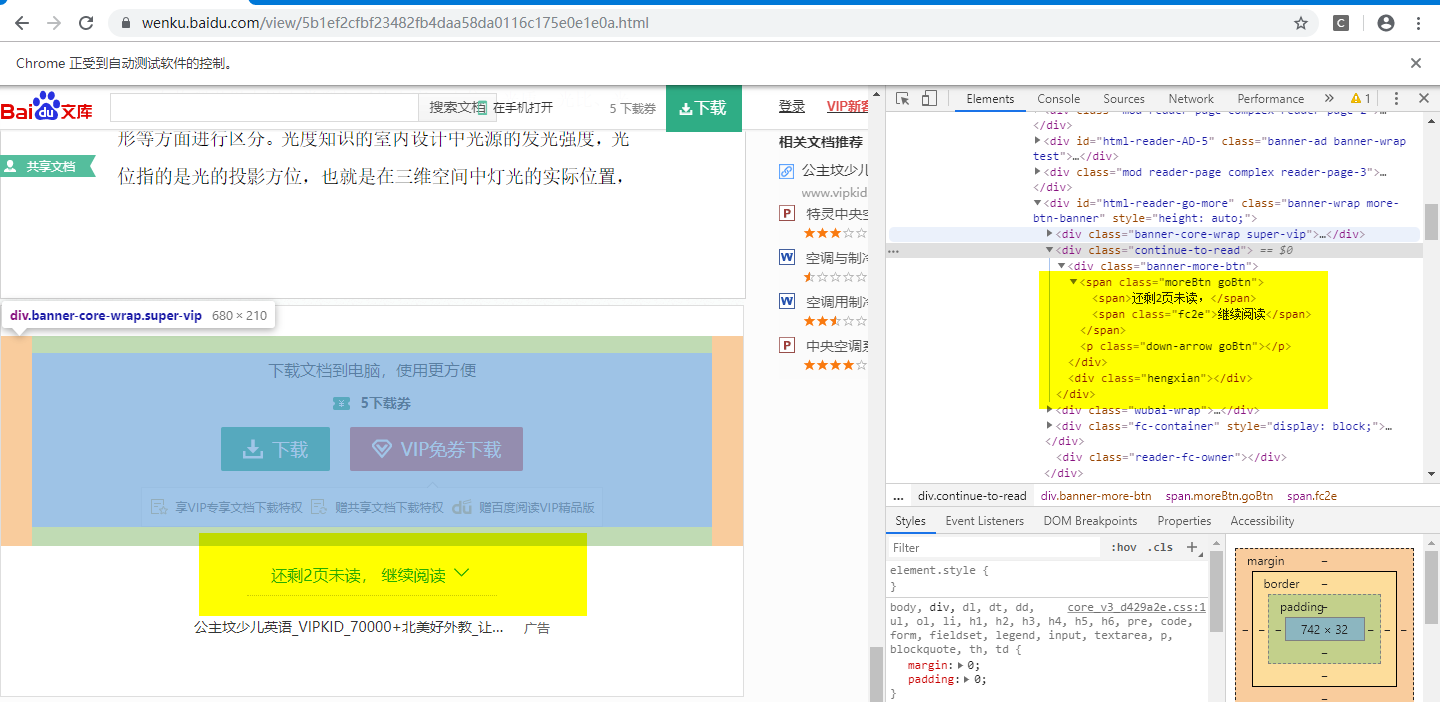
然后通过selenium的定位功能,定位到左边黄色区域所在的位置,调用驱动器进行点击
driver = webdriver.Chrome('D:/chromedriver.exe')
driver.get("https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html")
driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p").click()
然后执行看看
 黄字是报错的信息,显示的是有另外一个元素接受了点击的调用。可能是屏幕没有滑动到下方,直接点击被遮盖了。所以我们要通过驱动器先将浏览器滑动到底部,再点击继续阅读
黄字是报错的信息,显示的是有另外一个元素接受了点击的调用。可能是屏幕没有滑动到下方,直接点击被遮盖了。所以我们要通过驱动器先将浏览器滑动到底部,再点击继续阅读
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from bs4 import BeautifulSoup
import re
driver = webdriver.Chrome('D:/chromedriver.exe')
driver.get("https://wenku.baidu.com/view/5b1ef2cfbf23482fb4daa58da0116c175e0e1e0a.html")
page=driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p")
driver.execute_script('arguments[0].scrollIntoView();', page) #拖动到可见的元素去
page=driver.find_element_by_xpath("//*[@id='html-reader-go-more']/div[2]/div[1]/p").click()
先获取到继续阅读所在页面的位置,然后使用
driver.execute_script('arguments[0].scrollIntoView();', page) #拖动到可见的元素去方法将页面滚动到可以点击的位置
这样就获取到了整个完整页面,在使用beautifulsoup进行解析
html=driver.page_source
bf1 = BeautifulSoup(html, 'lxml')
result=bf1.find_all(class_='page-count')
num=BeautifulSoup(str(result),'lxml').span.string
count=eval(repr(num).replace('/', ''))
page_count=int(count)
for i in range(1,page_count+1):
result=bf1.find_all(id="pageNo-%d"%(i))
for each_result in result:
bf2 = BeautifulSoup(str(each_result), 'lxml')
texts = bf2.find_all('p')
for each_text in texts:
main_body = BeautifulSoup(str(each_text), 'lxml')
s=main_body.get_text()
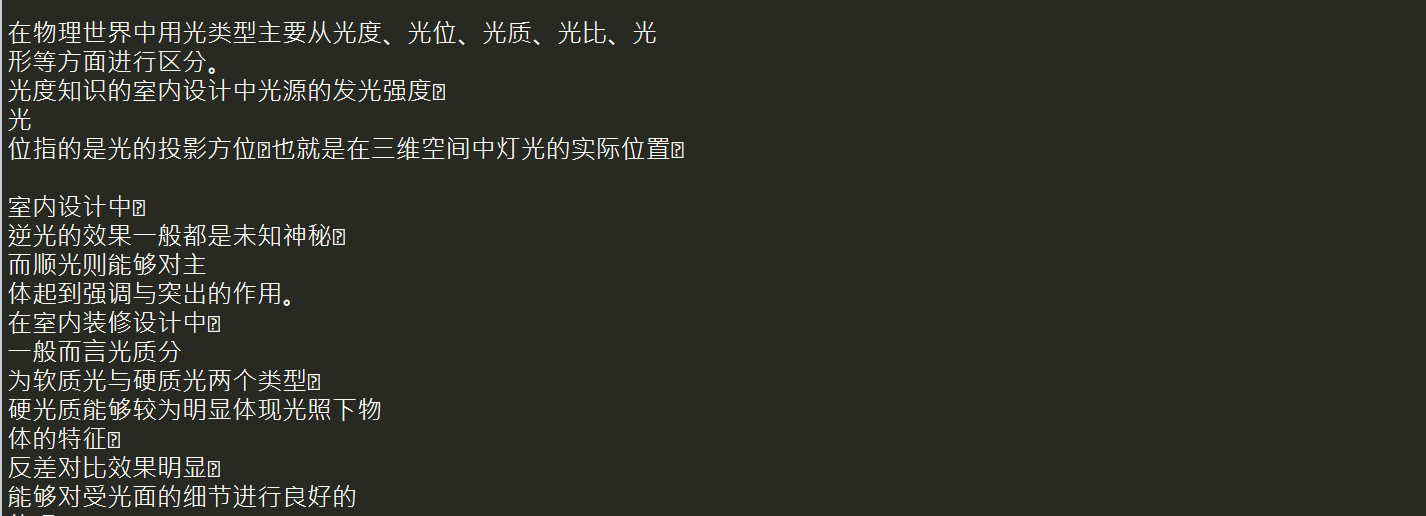
最后在写入txt文档
f=open("baiduwenku.txt","a",encoding="utf-8")
f.write(s)
f.flush()
f.close()
python+selenium爬取百度文库不能下载的word文档的更多相关文章
- python 利用selenium爬取百度文库的word文章
今天学习如何使用selenium库来爬取百度文库里面的收费的word文档 from selenium import webdriver from selenium.webdriver.common.k ...
- python+requests爬取百度文库ppt
实验网站:https://wenku.baidu.com/view/c7752014f18583d04964594d.html 在下面这种类型文件中的请求头的url打开后会得到一个页面 你会得到如下图 ...
- python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移
先说一下可能用到的一些python知识 一.python中使用的是unicode编码, 而日常文本使用各类编码如:gbk utf-8 等等所以使用python进行文字读写操作时候经常会出现各种错误, ...
- Python+Selenium爬取动态加载页面(1)
注: 最近有一小任务,需要收集水质和水雨信息,找了两个网站:国家地表水水质自动监测实时数据发布系统和全国水雨情网.由于这两个网站的数据都是动态加载出来的,所以我用了Selenium来完成我的数据获取. ...
- Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一.效果如下: 二.运行环境: win10系统:python3:PyCharm 三.QQ机器人用的是qqbot模块 用pip安装命令是: pip install qqbot (前提需要有request ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
- python 3 爬取百度图片
python 3 爬取百度图片 学习了:https://blog.csdn.net/X_JS612/article/details/78149627
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
随机推荐
- python之子类继承父类时进行初始化的一些问题
直接看代码: class Person: def __init__(self): self.name = "jack" class Student(Person): def __i ...
- C#操作注册表(简单方便,兼容X32和X64)
C#操作注册表(简单方便,兼容X32和X64) 大家好,我在这里给大家介绍本人实现的操作注册表的类,简单方便,兼容32位系统和64位系统. 一般大家用C#操作注册的方法是使用命名空间Microsoft ...
- CI框架获取post和get参数_CodeIgniter使用心得
请参考:CI文档的输入类部分: $this->input->post()$this->input->get() -------------------------------- ...
- springboot整合apache ftpserver详细教程(看这一篇就够了)
原创不易,如需转载,请注明出处https://www.cnblogs.com/baixianlong/p/12192425.html,否则将追究法律责任!!! 一.Apache ftpserver相关 ...
- K8S基于ingress-nginx实现灰度发布
之前介绍过使用ambassador实现灰度发布,今天介绍如何使用ingre-nginx实现. 介绍 Ingress-Nginx 是一个K8S ingress工具,支持配置 Ingress Annota ...
- APICloud开发者进阶之路 | UIPickerView 模块示例demo
本文出自APICloud官方论坛 rongCloud2 3.2.8 版本更新后添加了发送小视频接口,发送文件接口. rongCloud2 概述 融云是国内首家专业的即时通讯云服务提供商,专注为互联 ...
- async-await 线程分析
这里没有线程 原文地址:https://blog.stephencleary.com/2013/11/there-is-no-thread.html 前言 我是在看 C#8.0 新特性异步流时在评论里 ...
- Google搜索成最大入口,简单谈下个人博客的SEO
个人静态博客SEO该考虑哪些问题呢?本篇文章给你答案 咖啡君在开始写文章时首选了微信公众号作为发布平台,但公众号在PC端的体验并不好,连最基本的文章列表都没有,所以就搭建了运维咖啡吧的网站,可以通过点 ...
- 固定表头的table
在前端的开发过程中,表格时经常使用的一种展现形式.在我的开发过程中,当数据过多时,最常用的一种方式就是分页,但是有些地方还是需要滚动.通常的table 会随着滚动,导致表头看不见.一下是我找到的一种固 ...
- 自己动手搭环境—unit 1、Struts2环境搭建
1.web.xml中增加Struts2配置 <filter> <filter-name>struts2</filter-name> <filter-class ...